Ultra-Fast Data Loading and Testing in Altinity.Cloud


ClickHouse testing is easy with Altinity.Cloud. Users can quickly experiment with different things. Adjusting server settings, changing instance types or ClickHouse versions, adding shards and replicas, sharing data between ClickHouse clusters — all these tools are important components of application development and performance tuning. In this article, we will explain how to load and test datasets with lightning speed in Altinity.Cloud.
S3 table function on steroids
We have already discussed ClickHouse S3 table functions in our previous articles. It is a very powerful tool to load the data. It takes about 4 minutes to load popular ‘ontime’ and NYC taxi ‘tripdata’ datasets from compressed CSV files hosted in S3 bucket. ClickHouse can do much better, however, if data is pre-processed and stored in Native format. We have worked with ClickHouse many years, but still we were shocked by ourselves when we discovered that:
It takes just 42 seconds in order to load the 1.3B rows dataset from S3!
INSERT INTO tripdata
SELECT * FROM s3('https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/nyc_taxi_rides/data/tripdata_bin/data-*.bin.zstd', 'Native', 'pickup_date Date, id UInt64, vendor_id String, tpep_pickup_datetime DateTime, tpep_dropoff_datetime DateTime, passenger_count UInt8, trip_distance Float32, pickup_longitude Float32, pickup_latitude Float32, rate_code_id String, store_and_fwd_flag String, dropoff_longitude Float32, dropoff_latitude Float32, payment_type LowCardinality(String), fare_amount Float32, extra String, mta_tax Float32, tip_amount Float32, tolls_amount Float32, improvement_surcharge Float32, total_amount Float32, pickup_location_id UInt16, dropoff_location_id UInt16, junk1 String, junk2 String', 'zstd')
SETTINGS max_threads = 32, max_insert_threads = 32;
0 rows in set. Elapsed: 41.994 sec. Processed 1.31 billion rows, 167.39 GB (31.22 million rows/s., 3.99 GB/s.)Note that the bucket is located in the us-east-1 region, matching the Altinity.Cloud test instance. It could be slower for other configurations.
Why is it so fast? In addition to utilizing server and network resources efficiently (note ‘max_threads’ and ‘max_insert_threads’ settings, and there are more under the covers), there are two other reasons why Native format is highly performant in this case. First, data in Native format is more compact compared to other formats typically used for datasets. If we compare the size of compressed CSV files and the same data in Native format, we will find the difference is 1.5 times.

The second reason is more important, though. The data in Native format is already prepared the same way as ClickHouse stores it in RAM. It is an internal columnar representation. There is no need for additional parsing of CSV files, therefore ClickHouse can stream data to the storage with minimum extra overhead.
Preparing data in Native format
Okay, Native format is very fast for data imports. But how can we prepare the data in this format with ClickHouse?
First of all, let’s remember that ClickHouse table functions can be used in two directions: we can read from an S3 bucket with SELECT, and we can write to an S3 bucket with INSERT. Therefore, in order to store dataset on S3 in Native format we can run the following SQL:
INSERT INTO FUNCTION
s3('https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/nyc_taxi_rides/data/tripdata_bin/data.bin.zstd',
'***', '***',
'Native',
'pickup_date Date, id UInt64, vendor_id String, tpep_pickup_datetime DateTime, tpep_dropoff_datetime DateTime, passenger_count UInt8, trip_distance Float32, pickup_longitude Float32, pickup_latitude Float32, rate_code_id String, store_and_fwd_flag String, dropoff_longitude Float32, dropoff_latitude Float32, payment_type LowCardinality(String), fare_amount Float32, extra String, mta_tax Float32, tip_amount Float32, tolls_amount Float32, improvement_surcharge Float32, total_amount Float32, pickup_location_id UInt16, dropoff_location_id UInt16, junk1 String, junk2 String',
'zstd')
SELECT * FROM tripdataThat would create a single file on S3, which makes parallel reloading with multiple threads not very efficient. Certainly, we could run multiple INSERT statements for different time periods, but it would require quite a bit of manual work. Fortunately one of our Altinity developers added a convenient partitioned writes feature. It is now possible to automatically split data written to an S3 table function into multiple objects:
INSERT INTO FUNCTION
s3('https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/nyc_taxi_rides/data/tripdata_bin/data-{_partition_id}.bin.zstd',
'***', '***',
'Native',
<list of columns skipped>,
'zstd')
PARTITION BY toYYYYMM(pickup_date)
SELECT * FROM tripdataLook at ‘{_partition_id}’ part of the S3 URL. This is an instruction for ClickHouse to substitute the value of the ‘PARTITION BY’ expression. As a result, ClickHouse creates one object per partition. When it matches partitioning of the table itself, minimum modifications of the data are necessary when reading/writing data from S3.
Unfortunately, during the writing of this article we discovered that the INSERT performance is nothing like that of SELECT. It is approximately 30 times slower, maybe due to a lack of parallelism. It is not a big issue since we need to do it once, but this needs to be improved.
Another inconvenience is the need to specify a list of columns (structure) as a parameter of S3 table function. It can be copied from the table definition “as-is”, but it looks too bulky. In the future we plan to make it more user friendly and avoid copy/paste.
Measuring query performance accurately
Once the data is in ClickHouse we can start running test queries. However, the network lag between client and the cloud environment contributes to observed query performance and skews the results. For a fair benchmark network latency needs to be excluded. ClickHouse provides a nice tool that captures all relevant metrics — ‘system.query_log’ table. In order to identify particular queries or test runs we can add SQL comments, for example:
/* TESTRUN=Qtest */
SELECT count() from system.parts
SETTINGS log_queries=1After we run this query multiple times, we can check the query_log and see how it performs:
SELECT extract(query, 'TESTRUN=(Q.[^ ]*) ') Q, count(),
min(query_duration_ms) min_t,
max(query_duration_ms) max_t,
round(avg(query_duration_ms),2) avg_t
FROM system.query_log
where event_date=today()
and type='QueryFinish'
and query like '%TESTRUN%'
group by Q ORDER BY Q
┌─Q─────┬─count()─┬─min_t─┬─max_t─┬─avg_t─┐
│ Qtest │ 6 │ 0 │ 1 │ 0.83 │
└───────┴─────────┴───────┴───────┴───────┘This query can of course be extended with other metrics as needed.
Sharing data between different ClickHouse clusters
Consider we’ve got the data in one ClickHouse server already. What is the fastest way to move it to another server? Altinity.Cloud provides several ways to do the job.
First, it is possible to re-scale the ClickHouse instance of a cluster to a different instance type. The data is automatically re-attached to the new nodes, and it is immediately ready to use.
The second approach is what we call a ‘replica cluster’. In order to use that, tables need to be created with the ReplicatedMergeTree engine first. That enables replication even if there are no other replicas. If a user starts a replica cluster, Altinity.Cloud configures the new cluster to replicate from the source cluster. ClickHouse replication is super fast, so the data is available almost immediately after the replica cluster is started. How is it different from re-scaling to a different instance type? In addition to changing the instance type it allows to change the storage configuration, for example, and also compare source and replica clusters side by side.
It is also possible to use a backup. Altinity.Cloud performs backups to an S3 bucket, and can restore from S3 bucket to a newly launched cluster. That requires a data transfer between ClickHouse to S3 and back, so it is not going to be fast. However, S3 backup can be used in order to restore data on an on-prem server, or to another cloud.
In the future we plan to add extra capabilities into ClickHouse and Altinity.Cloud in order to make it even easier to share datasets.
Trying it all together
Let’s try to apply the recipes of this article to a real benchmarking exercise. We will take the Star Schema Benchmark (SSB) that we analyzed a few months ago in our “Nailing cost efficiency against Druid and RockSet” article and measure how fast we can repeat the benchmark from scratch. The 600M rows test dataset in Native format has been uploaded to S3 bucket before the experiment.
Step 1. Starting Altinity.Cloud ClickHouse instance
Our go-to instance type for benchmarks at Altinity.Cloud is m6i.8xlarge with 32 vCPUs, 128GB or RAM, and 1TB of EBS storage. The latest ClickHouse version 21.11 has been used. Starting a single node ClickHouse took 3 minutes.
Step 2. Creating a table and loading the dataset
SSB benchmark exists in several variants, and we took the denormalized schema for simplicity. ‘lineorder_wide’ table definition is available in our github repo. It took slightly more than 2 minutes to load the 600M rows dataset from S3 using the following query:
INSERT INTO lineorder_wide
SELECT * FROM
s3('https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/ssb/data/lineorder_wide_bin/*.bin.zstd',
'Native',
" `LO_ORDERKEY` UInt32,
`LO_LINENUMBER` UInt8,
`LO_CUSTKEY` UInt32,
`LO_PARTKEY` UInt32,
`LO_SUPPKEY` UInt32,
`LO_ORDERDATE` Date,
`LO_ORDERPRIORITY` LowCardinality(String),
`LO_SHIPPRIORITY` UInt8,
`LO_QUANTITY` UInt8,
`LO_EXTENDEDPRICE` UInt32,
`LO_ORDTOTALPRICE` UInt32,
`LO_DISCOUNT` UInt8,
`LO_REVENUE` UInt32,
`LO_SUPPLYCOST` UInt32,
`LO_TAX` UInt8,
`LO_COMMITDATE` Date,
`LO_SHIPMODE` LowCardinality(String),
`C_CUSTKEY` UInt32,
`C_NAME` String,
`C_ADDRESS` String,
`C_CITY` LowCardinality(String),
`C_NATION` LowCardinality(String),
`C_REGION` Enum8('ASIA' = 0, 'AMERICA' = 1, 'AFRICA' = 2, 'EUROPE' = 3, 'MIDDLE EAST' = 4),
`C_PHONE` String,
`C_MKTSEGMENT` LowCardinality(String),
`S_SUPPKEY` UInt32,
`S_NAME` LowCardinality(String),
`S_ADDRESS` LowCardinality(String),
`S_CITY` LowCardinality(String),
`S_NATION` LowCardinality(String),
`S_REGION` Enum8('ASIA' = 0, 'AMERICA' = 1, 'AFRICA' = 2, 'EUROPE' = 3, 'MIDDLE EAST' = 4),
`S_PHONE` LowCardinality(String),
`P_PARTKEY` UInt32,
`P_NAME` LowCardinality(String),
`P_MFGR` Enum8('MFGR#2' = 0, 'MFGR#4' = 1, 'MFGR#5' = 2, 'MFGR#3' = 3, 'MFGR#1' = 4),
`P_CATEGORY` String,
`P_BRAND` LowCardinality(String),
`P_COLOR` LowCardinality(String),
`P_TYPE` LowCardinality(String),
`P_SIZE` UInt8,
`P_CONTAINER` LowCardinality(String)",
'zstd')
settings max_threads=32, max_insert_threads=32;
0 rows in set. Elapsed: 131.629 sec. Processed 600.04 million rows, 111.19 GB (4.56 million rows/s., 844.69 MB/s.)This is slower compared to the ‘tripdata’ dataset due to having more columns and randomized data in the ‘lineorder_wide’ table that does not compress especially well. The data size on disk for 1.3B rows of ‘tripdata’ is 37GB, but it is above 70GB for 600M rows of ‘lineorder_wide’ table.
Step 3. Running the benchmark queries
Once the data is loaded, we can run test queries. We used the same benchmark script as in the previous article. It performs one warmup run for every query, then takes 3 test runs, and extracts the average query time from the query_log using the technique described above.
$ TRIES=3 CH_CLIENT=clickhouse-client CH_HOST=ssb.tenant-a.staging.altinity.cloud CH_USER=admin CH_PASS=*** CH_DB=default QUERIES_DIR=flattened/queries ./bench.sh
flattened/queries: faa53a191069c9c7374af1cec754ad34 -
Q1.1.sql ... 0.053
Q1.2.sql ... 0.01
Q1.3.sql ... 0.016
Q2.1.sql ... 0.116
Q2.2.sql ... 0.055
Q2.3.sql ... 0.046
Q3.1.sql ... 0.122
Q3.2.sql ... 0.102
Q3.3.sql ... 0.11
Q3.4.sql ... 0.008
Q4.1.sql ... 0.066
Q4.2.sql ... 0.031
Q4.3.sql ... 0.045
Total : 0.779Performance of every query as well as the total query time improved 1.5 times since March 2021! We did not apply any optimizations at all! This is typical for ClickHouse — it gets only faster with age.
The end-to-end benchmarking exercise took less than 20 minutes. The test instance has been deleted after completion. We could also stop it with all the data retained, if we need to resume it in the future.
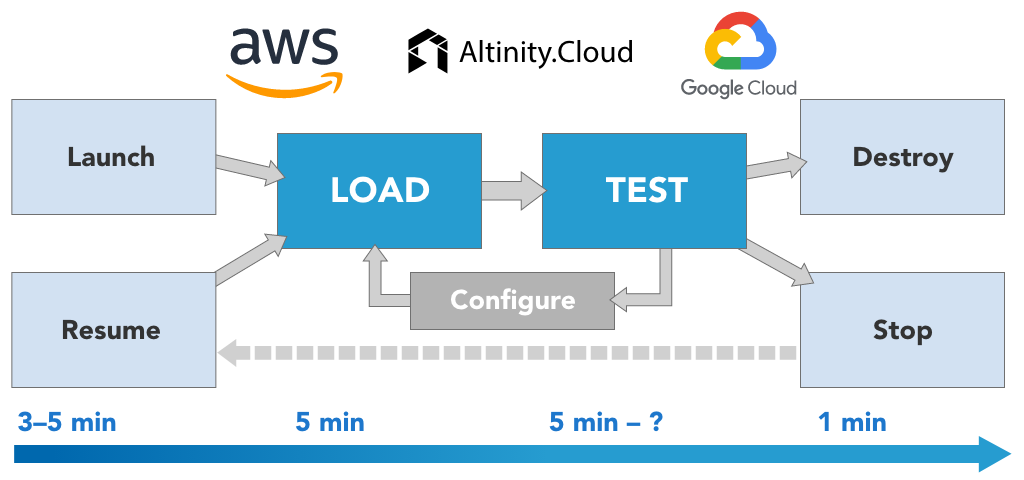
Conclusion
Cloud operations change the way users interact with stored data and compute. It is super easy and fast to load datasets from object storage like S3, especially if those are prepared in an optimal way. Testing different instance types or storage configurations becomes a routine, thanks to automation provided by cloud management software.
Altinity.Cloud brings the power of cloud operation to ClickHouse. It significantly simplifies the development and deployment of ClickHouse applications, and it takes over operations and maintenance. Many of Altinity’s customers deployed their solutions ahead of competitors thanks to Altinity.Cloud. Go ahead and jump on the train. It’s full steam ahead for high-performance applications!
Hello,
Excellent content! I have one question:
“The 600M rows test dataset in Native format has been uploaded to S3 bucket before the experiment.”
Can you please shed some light on how to convert data to Native format? (i.e. from csv)
It is explained in section ‘Preparing data in Native format’. This is a simple INSERT SELECT statement to S3.