Tips for High-Performance ClickHouse® Clusters with S3 Object Storage

In our previous blog posts, we explained the various ways that ClickHouse can use S3 object storage. To keep things simple we generally focused on single-node operation. However, ClickHouse often runs in a cluster, and cluster operation poses some interesting questions regarding S3 usage. They include parallelizing data load across nodes, benefits of horizontal vs. vertical scaling, and avoiding unnecessary replication.
In this article, we will discuss how ClickHouse clusters can be used with S3 efficiently thanks to two important new features: the ‘s3Cluster‘ table function and zero-copy replication. We hope our description will pave the way for more ClickHouse users to exploit scalable, inexpensive object storage in their deployments.
Loading Data from S3 to ClickHouse Clusters
Consider we have a cluster of 4 shards, and several dozen data files in a S3 bucket. What is the fastest way to load those files into ClickHouse?
For this exercise, we will be using our favourite 1.3B rows NYC taxi rides dataset. We have a copy stored in a public S3 bucket in the AWS us-east1 region. The data size is 37.3GB stored in 96 gzip compressed CSV files. Our test ClickHouse cluster is powered by Altinity.Cloud running at 4 m5.2xlarge nodes, 8vCPUs and 32GB RAM each. We used the latest ClickHouse community version 21.7.4 in all tests, though anything 21.6+ should be good enough.

Let’s start with a straightforward approach — loading data to a cluster via a Distributed table. For that, we need to create a local table ‘tripdata_local’ and a distributed table ‘tripdata_dist’.
CREATE TABLE IF NOT EXISTS tripdata_local on cluster 'all-sharded' (
pickup_date Date DEFAULT toDate(pickup_datetime) CODEC(Delta, LZ4),
id UInt64,
vendor_id String,
pickup_datetime DateTime CODEC(Delta, LZ4),
dropoff_datetime DateTime,
passenger_count UInt8,
trip_distance Float32,
pickup_longitude Float32,
pickup_latitude Float32,
rate_code_id String,
store_and_fwd_flag String,
dropoff_longitude Float32,
dropoff_latitude Float32,
payment_type LowCardinality(String),
fare_amount Float32,
extra String,
mta_tax Float32,
tip_amount Float32,
tolls_amount Float32,
improvement_surcharge Float32,
total_amount Float32,
pickup_location_id UInt16,
dropoff_location_id UInt16,
junk1 String,
junk2 String)
ENGINE = MergeTree
PARTITION BY toYYYYMM(pickup_date)
ORDER BY (vendor_id, pickup_location_id, pickup_datetime);CREATE TABLE tripdata_dist ON CLUSTER `all-sharded` AS tripdata_local
ENGINE = Distributed('all-sharded', default, tripdata_local, cityHash64(pickup_location_id, dropoff_location_id));Now let’s try to insert data into a distributed table. It can be done with a simple ‘INSERT SELECT’ statement from an ‘s3’ table function as follows:
INSERT INTO tripdata_dist
SELECT * FROM s3('https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/nyc_taxi_rides/data/tripdata/data-*.csv.gz',
'CSVWithNames',
'pickup_date Date, id UInt64, vendor_id String, tpep_pickup_datetime DateTime, tpep_dropoff_datetime DateTime, passenger_count UInt8, trip_distance Float32, pickup_longitude Float32, pickup_latitude Float32, rate_code_id String, store_and_fwd_flag String, dropoff_longitude Float32, dropoff_latitude Float32, payment_type LowCardinality(String), fare_amount Float32, extra String, mta_tax Float32, tip_amount Float32, tolls_amount Float32, improvement_surcharge Float32, total_amount Float32, pickup_location_id UInt16, dropoff_location_id UInt16, junk1 String, junk2 String',
'gzip')
settings max_threads=8, max_insert_threads=8, input_format_parallel_parsing=0;
0 rows in set. Elapsed: 1082.577 sec. Processed 1.31 billion rows, 167.39 GB (1.21 million rows/s., 154.62 MB/s.)Hint
Set max_threads and max_insert_threads to the number of cores and disable input_format_parallel_parsing since all cores are already utilized. When input_format_parallel_parsing is enabled (this is default) performance degrades by 20% in these tests. This setting makes sense for a single file, but not for a set of files loaded in parallel.
The table was loaded pretty fast into a distributed table. We’ve got a notable 1.2M rows per second. However, only a single node was busy processing and parsing the data, while other nodes were just fetching prepared parts. The performance was bounded by a single node in this case.
Is there a way to use the cluster more efficiently? For example, we could distribute the load and run an INSERT/SELECT query on every node separately. But that would require coordination and also splitting the set of files in the S3 bucket to a number of chunks somehow. Since ClickHouse 21.5 there is a new table function — s3Cluster — that makes it easy!
‘s3Cluster’ does exactly what we need: the query initiator node retrieves list of objects from a S3 bucket first, then it distributes objects to be processed to shards in the cluster, so every shard reads its own set of objects increasing cluster utilization and parallelism.
Let’s test whether it makes data import any faster:
INSERT INTO tripdata_dist
SELECT * FROM
s3Cluster('all-sharded', 'https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/nyc_taxi_rides/data/tripdata/data-*.csv.gz', 'CSVWithNames', <list_of_columns_skipped>, 'gzip');
0 rows in set. Elapsed: 327.225 sec. Processed 1.31 billion rows, 167.39 GB (4.01 million rows/s., 511.55 MB/s.)The results are outstanding! We get over three times better performance, reaching 4M rows per second. Definitely, ‘s3Cluster’ does the job perfectly.
Hint
When the ‘s3Cluster’ function is used, max_threads, max_insert_threads and input_format_parallel_parsing settings need to be propagated to all shards explicitly. This can be done using a custom configuration file. Otherwise, shards will be running with the defaults resulting in slower loading speed. An example configuration file looks like this:
users.d/defaults_for_s3.xml:
<yandex>
<profiles>
<default>
<max_threads>8</max_threads>
<max_insert_threads>8</max_insert_threads> <input_format_parallel_parsing>0</input_format_parallel_parsing>
</default>
</profiles>
</yandex>Really curious minds can look into the ‘query_log’ table in order to see the load distribution across shards. Note the use of Map data type:
WITH cast( (ProfileEvents.Names, ProfileEvents.Values) as Map(String, String)) as events
SELECT
hostName(),
is_initial_query as iq,
read_rows, read_bytes,
events['S3ReadBytes'] AS S3ReadBytes,
events['S3ReadRequestsCount'] AS S3ReadRequestsCount
FROM cluster('all-sharded', system.query_log)
WHERE event_date >= today() - 7 AND type = 'QueryFinish'
AND initial_query_id = '42151a7d-91b5-4cba-8698-baef9daff0de'
ORDER BY is_initial_query DESC
FORMAT PrettyCompactMonoBlock
┌─hostName()────────────────────┬─iq─┬───€read_rows─┬────€read_bytes─┬─S3ReadBytes─┬─S3ReadRequestsCount─┐
│ chi-s3cluster-s3cluster-0-0-0 │ 1 │ 1310903963 │ 167391011493 │ │ 1 │
│ chi-s3cluster-s3cluster-0-0-0 │ 0 │ 322490535 │ 41061261158 │ 9917185805 │ 24 │
│ chi-s3cluster-s3cluster-1-0-0 │ 0 │ 313441214 │ 40051378538 │ 8974431017 │ 24 │
│ chi-s3cluster-s3cluster-2-0-0 │ 0 │ 337841899 │ 43195896401 │ 10645649141 │ 24 │
│ chi-s3cluster-s3cluster-3-0-0 │ 0 │ 337130315 │ 43082475396 │ 10462064786 │ 24 │
└──────────────────────────────┴────┴────────────┴──────────────┴─────────────┴──────────────────────┘As you can see 96 files were evenly distributed across 4 shards.
Horizontal vs. Vertical Scalability
Let’s conduct a few more experiments. First, what if we replace our 4 node m5.2xlarge cluster with a single m5.8xlarge instance? That would give us the same 32 vCPUs and 128GB RAM size but on a single machine instead of a cluster. A distributed table is not needed in this case, data can be loaded directly into a local table.
INSERT INTO tripdata
SELECT * FROM s3('https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/nyc_taxi_rides/data/tripdata/data-*.csv.gz', 'CSVWithNames', <list_of_columns_skipped>, 'gzip')
settings max_threads=32, max_insert_threads=32, input_format_parallel_parsing=0;
0 rows in set. Elapsed: 269.602 sec. Processed 1.31 billion rows, 167.39 GB (4.86 million rows/s., 620.88 MB/s.)It is almost exactly 4 times faster than a single run on m5.2xlarge node, and 20% faster than the ‘s3Cluster’ function on a 4 node cluster of smaller nodes. So S3 performance scales linearly if we add more cores (Note: this may be true until a certain limit, as there could be network bandwidth limitations as well.)
Let’s confirm it from another angle by eliminating a source of ClickHouse storage overhead. Note that all queries above consist of two stages: SELECT and INSERT. The latter stage does not depend on ‘s3’ function performance at all, but requires quite a lot of resources. So let’s run just the SELECT part without storing the result to see how fast we can pull data from S3. This can be done with a special format Null. Alternatively, we could INSERT into a Null table engine.
SELECT * FROM s3('https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/nyc_taxi_rides/data/tripdata/data-*.csv.gz', 'CSVWithNames', <list_of_columns_skipped>, 'gzip')
settings max_threads=32, max_insert_threads=32, input_format_parallel_parsing=0 FORMAT Null;
0 rows in set. Elapsed: 159.653 sec. Processed 1.31 billion rows, 167.39 GB (8.21 million rows/s., 1.05 GB/s.)Wow, it is almost twice as fast, reaching 8M rows per second! Definitely, ClickHouse storage processing layer adds its overhead when INSERT-ing to S3.
A 4-node sharded cluster of m5.2xlarge nodes showed 2.06 million rows/s for ‘s3’ table function and 6.49 million rows/s for ‘s3Cluster’ table function respectively. Results of all experiments are summarized below:
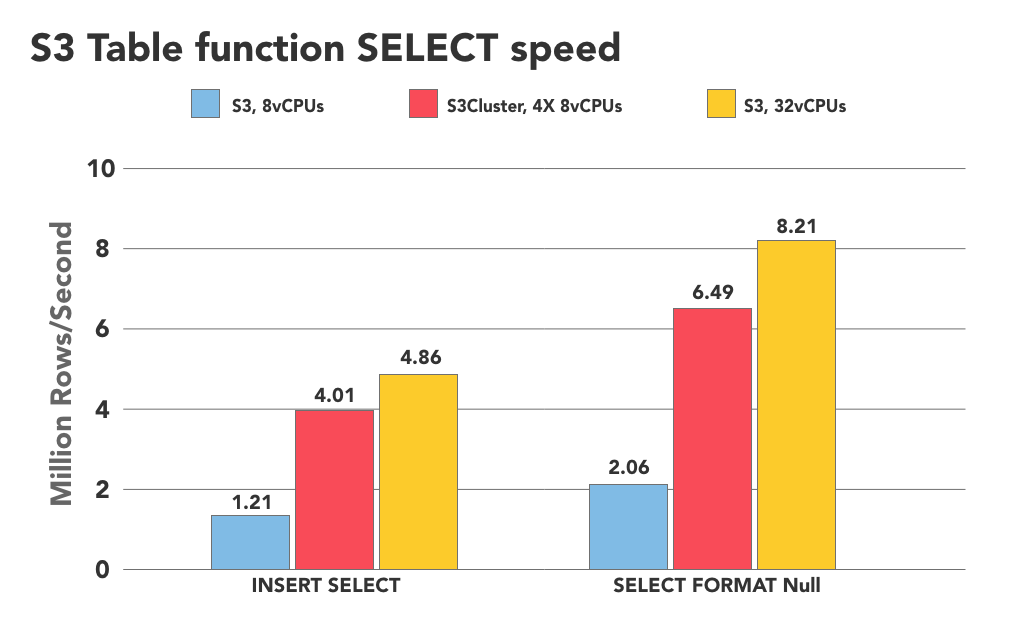
These results demonstrate that vertical scalability of S3 usage in ClickHouse is linear, while horizontal scalability is slightly behind. This is true not just for S3 but for many other ClickHouse workloads as well. Users of Altinity.Cloud can easily scale both horizontally and vertically thanks to network attached EBS volumes. We see a similar scaling effect here as well.
Disk S3 and Replication
Working with s3 table functions in a replicated cluster does not bring any surprises. ‘s3Cluster’ respects the cluster configuration properly, similar to a Distributed table. However, when S3 is used as storage for a ReplicatedMergeTree table, there is a problem that we highlighted in one of our earlier articles: ReplicatedMergeTree using an S3 disk as storage would replicate S3 data as well, creating multiple copies on S3.
That does not make any sense, since S3 is already replicated by the cloud provider. ClickHouse 21.4 introduced a new feature called “zero copy replication”. It allows you to configure S3-backed ReplicatedMergeTree properly on a replicated cluster.
Let’s start a single node cluster and configure access to an S3 bucket.
<yandex>
<storage_configuration>
<disks>
<s3>
<type>s3</type>
<endpoint>http://s3.us-east-1.amazonaws.com/my_bucket/data</endpoint>
<access_key_id>*****</access_key_id>
<secret_access_key>*****</secret_access_key>
</s3>
</disks>
<policies>
<s3>
<volumes>
<s3>
<disk>s3</disk>
</s3>
</volumes>
</s3>
</policies>
</storage_configuration>
</yandex>Here, we have defined an S3 storage policy that would store all the data in the S3 bucket.
In order to turn off replication for S3 data, we need to add a setting to merge_tree settings:
<merge_tree>
<allow_s3_zero_copy_replication>1</allow_s3_zero_copy_replication>
</merge_tree>Now we are ready to run some tests. Let’s load a tripdata dataset into a replicated table stored on S3, check the bucket size, and then re-scale the cluster into two nodes. First, we create a replicated table stored onS3:
CREATE TABLE default.tripdata
(
`pickup_date` Date DEFAULT toDate(pickup_datetime) CODEC(Delta(2), LZ4),
`id` UInt64,
`vendor_id` String,
`pickup_datetime` DateTime CODEC(Delta(4), LZ4),
`dropoff_datetime` DateTime,
`passenger_count` UInt8,
`trip_distance` Float32,
`pickup_longitude` Float32,
`pickup_latitude` Float32,
`rate_code_id` String,
`store_and_fwd_flag` String,
`dropoff_longitude` Float32,
`dropoff_latitude` Float32,
`payment_type` LowCardinality(String),
`fare_amount` Float32,
`extra` String,
`mta_tax` Float32,
`tip_amount` Float32,
`tolls_amount` Float32,
`improvement_surcharge` Float32,
`total_amount` Float32,
`pickup_location_id` UInt16,
`dropoff_location_id` UInt16,
`junk1` String,
`junk2` String
)
ENGINE = ReplicatedMergeTree('/clickhouse/{cluster}/tables/{shard}/{database}/{table}', '{replica}')
PARTITION BY toYYYYMM(pickup_date)
ORDER BY (vendor_id, pickup_location_id, pickup_datetime)
SETTINGS index_granularity = 8192, storage_policy = 's3';Note the ‘storage_policy’ reference in the settings. This tells ClickHouse to store table data in S3 instead of the default storage type. After the table is created, we can load CSV files from the S3 bucket using the s3() table function as we did earlier.
Once the table is loaded, we can check the system.parts table for the data size:
SELECT
total_rows,
formatReadableSize(total_bytes)
FROM system.tables
WHERE name = 'tripdata'
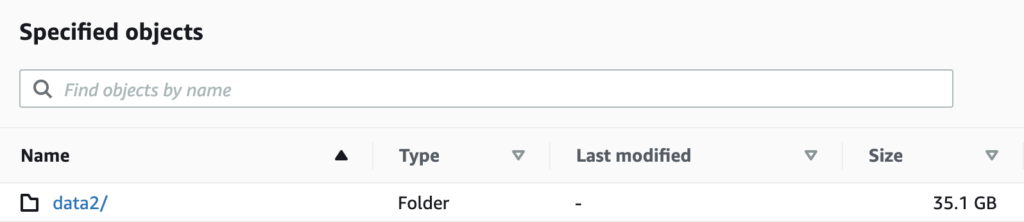
┌─total_rows─┬─formatReadableSize(total_bytes)─┐
│ 1310903963 │ 35.05 GiB │
└───────────┴──────────────────────────────────┘We also check the data size in the S3 bucket using the AWS console to confirm it is the same:
Now let’s add a second replica. If you are using Altinity clickhouse-operator for Kubernetes or Altinity.Cloud, that takes just a couple of minutes. It also makes sure that replicated tables are created on a new replica automatically.
Once the replica is added, we can check that data is in place on both replicas with the following query:
SELECT
hostName(),
total_rows,
formatReadableSize(total_bytes)
FROM cluster('all-sharded', system.tables)
WHERE name = 'tripdata'
┌─hostName()────────────────┬─total_rows─┬─formatReadableSize(total_bytes)─┐
│ chi-s3test3-s3test3-0-0-0 │ 1310903963 │ 35.05 GiB │
└──────────────────────────┴────────────┴──────────────────────────────────┘
┌─hostName()────────────────┬─total_rows─┬─formatReadableSize(total_bytes)─┐
│ chi-s3test3-s3test3-0-1-0 │ 1310903963 │ 35.05 GiB │
└──────────────────────────┴────────────┴──────────────────────────────────┘The table has been successfully replicated. If we check the bucket size in the AWS console we will see the bucket size is the same as before.
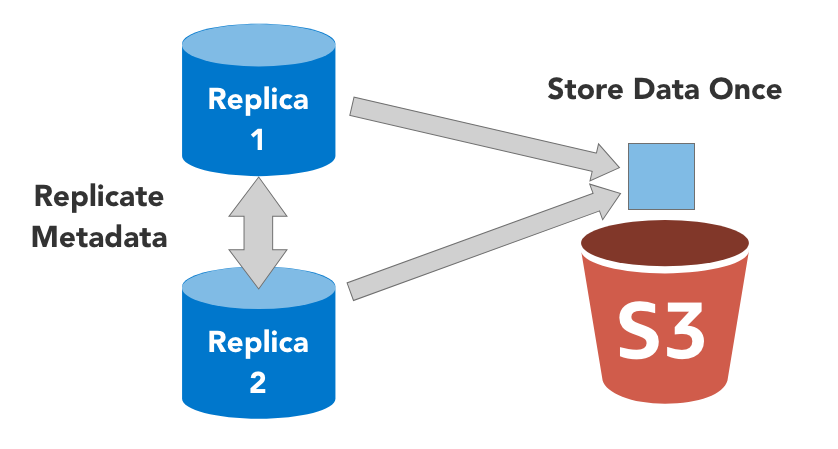
Under the hood, ClickHouse continues to coordinate and manage replication of the file references and metadata as before, but does not replicate S3 objects once they are created by an insertion or merge process. With this excellent feature, S3 disk storage becomes totally usable in replicated ClickHouse clusters.
Zero copy replication can be extended to other storage types that replicate on their own. Recently added HDFS support for MergeTree tables can be configured to use zero copy replication as well. As a side effect the setting ‘allow_s3_zero_copy_replication’ is renamed to ‘allow_remote_fs_zero_copy_replication’ in ClickHouse release 21.8 and above.
Conclusion
ClickHouse was originally designed for bare metal operation with tightly coupled compute and storage. But times change, and today many users operate ClickHouse in public or private clouds. Operating in the cloud requires ClickHouse to adopt and leverage cloud services. Object Storage is one such important service. While the basic object storage support was added to ClickHouse more than a year ago, it took many months to make it efficient and stable. Along with many other community members, Altinity contributed development and QA resources to make it happen.
In this article, we presented an overview of two important new ClickHouse features: ‘s3Cluster’ table function and zero copy replication. These increase ClickHouse efficiency both in terms of cost and performance. More ClickHouse cloud features are on the horizon. Stay tuned!
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.
We tried the configuration mentioned here, although the insert query completes as noted in this post, actual data takes long time to write to underlying local tables. It is probably due to the fact that Distributed table queues the files and dispatches 1 at a time to other nodes. Is this a known limitation or there is a workaround here?