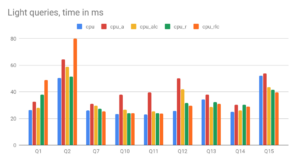
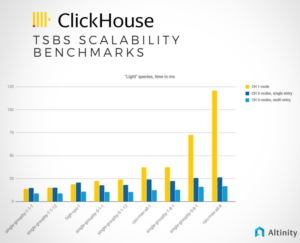
The Tournament of AWS CPUs in Altinity.Cloud®
Dive into our latest blog to explore a rigorous ClickHouse benchmark tournament, featuring AWS’s 7th-gen Intel m7i, AMD m7a, and Graviton m7g instances. With Altinity.Cloud’s easy configuration, discover which instance offers the best price-performance ratio for your cloud operations. Find…