ClickHouse® Nails Cost Efficiency Challenge Against Druid & Rockset

Rick Bilodeau from Imply published an excellent article in June 2020 comparing Druid cost-efficiency to Google Big Query for what they called ‘hot analytics’ — sub-second response time with high query concurrency. We appreciate this effort and great results of an open source technology. In that article Rick used the popular Star Schema Benchmark (SSB).
We know this benchmark very well. One of Altinity founders and Percona CTO Vadim Tkachenko uses it quite regularly when comparing different open source analytical options (in 2017 and in 2020). Few weeks ago another real time analytics company Rockset published their results claiming much better performance and efficiency compared to Druid. We decided to take a closer look at the Druid and Rockset approach, and see how ClickHouse can perform.
To make a long story short, we were pleased to confirm that ClickHouse is 6 times faster than Druid and 4 times faster than Rockset with fewer hardware resources!
Testing methodology
We were not going to repeat Imply and Rockset experiments precisely, but used the same methodology for the ClickHouse benchmark in order to compare results. The original article does not provide enough detail, but Imply also published a detailed white paper for curious readers, which we certainly are. Rockset also published a whitepaper that explains their specifics.
Similar to Druid and Rockset, for this benchmark we generated 600 million rows (approximately 100GB) of test data using SSB’s dbgen utility. This is a relatively small dataset. In comparison, Vadim Tkachenko used 15B rows in his benchmark of column store databases a few months ago.
Original SSB design uses 4 main tables: lineorder, customer, supplier, part. Druid and Rockset are not particularly good at joins, therefore the schema has been denormalized into a flat table. ClickHouse can do joins pretty well, but performance degrades when filter conditions are applied to join tables. For this reason we tried 3 different schema options:
- Original SSB schema
- Flattened schema following Druid and Rockset approach
- Flattened schema with additional indices to boost performance.
SSB proposes 13 standard SQL queries that test different scenarios. In the Druid test, each of the 13 queries were run 10 times in each test flight, and there were 5 flight runs. Results were averaged per flight run. Per standard benchmark practices, the fastest and slowest results were considered outliers and discarded before analyzing the results. The remaining results were averaged to provide a final result.
Rockset made it simpler: they run each query 3 times on a warmed OS cache and reported the median of the run times.
For ClickHouse we took the Rockset approach. First we made a warm-up run, then executed every query 3 times and averaged the results.
Hardware
The Druid cluster used the following AWS resources:
- Data Servers: 3 x i3.2xlarge (8 vCPU, 61 GB memory, 1.9 TB NVMe SSD storage each)
- Query Servers: 2 x m5d.large (2 vCPU, 8 GB memory each)
- Master Server: 1 x m5.large (2 vCPU, 8 GB memory)
In total it counts as 30 sCPUs and 207GB RAM on 6 AWS instances that would cost $2.194/hour altogether (3*0.624 + 2*0.113 + 0.096).
Rocket’s setup is similar:
- Leaf nodes: 3 x i3.2xlarge (8 vCPU, 61 GB RAM, 1.9 TB NVMe SSD storage each)
- Dedicated aggregator nodes: 3 x m5.large (2 vCPU, 8GB RAM)
In total it matches Druid’s 30 vCPUs and 207GB RAM, but is less expensive at 2.16$/hour due to use of m5 instead of m5d (3*0.624 + 3*0.096)
With ClickHouse we will continue to use AWS configuration powered by Altinity.Cloud that served us well in our recent ClickHouse vs. Redshift FinTech benchmark:
- Single m5.8xlarge server: 32 vCPU, 120GB RAM, EBS.
We only need a single server that costs $1.54/hour, though ClickHouse can easily scale to more when needed.
Imply’s claim on cost-performance is based on scalability for concurrent queries. However they did not run concurrent queries at all, but instead built a model using a single query performance and then made cost projections based on this model. We did not validate if their model holds true for ClickHouse, so will only compare the basic test flight results for a given hardware and schema configuration.
Original SSB schema
We put schema and query files into a github repository https://github.com/Altinity/ssb for easy reference. The original schema consists of 4 tables: one fact table lineorder, and 3 dimensions: supplier, customer and part. Once 600M rows are loaded into ClickHouse it takes about 15GB of storage:
SELECT
table,
sum(rows),
sum(bytes),
round(sum(bytes) / sum(rows)) AS bpr
FROM system.parts
WHERE active AND database = 'ssb' AND table IN ('lineorder', 'supplier', 'customer', 'part')
GROUP BY table
┌─table───────┬─sum(rows)─┬───€sum(bytes)─┬─bpr─┐
│ supplier │ 200000 │ 7894419 │ 39 │
│ part │ 1400000 │ 25302925 │ 18 │
│ customer │ 3000000 │ 120309380 │ 40 │
│ lineorder │ 600038145 │ 15648835603 │ 26 │
└────────────┴───────────┴─────────────┴──────┘The fact table takes 26 bytes per row on average, but the compression ratio is only x1.5 – very low for ClickHouse. The generated table with random integers does not compress well, and we did not optimize schema for storage efficiency.
Note on benchmarking
In order to measure query performance accurately test scripts are usually executed as close as possible to the database itself. It is not always possible with cloud deployments. Altinity.Cloud can run in any AWS region but the instance I used is 7000 km away so network latency is significant. Fortunately, ClickHouse can perfectly measure query execution time by itself and log accurate timings to the system.query_log table. The only challenge is how to locate the proper query in the query log when running benchmarks? The trick is to add an SQL comment to the query with some unique reference, and use it to locate the proper test run. See our benchmarking script for more details.
Now we are ready to check the queries on the normalized table. In fact, we were a bit disappointed with ClickHouse performance in this case. It can definitely do better if some optimizations are applied. Only queries that did not have joins (Q1.x) were “ClickHouse-fast”, once heavy joins were applied performance degraded significantly. The total running time with normalized dataset was 18.5s, which is still slightly faster than Google BigQuery from the Imply article but seems hardly competitive for this use case.
Let’s see what happens once we change the schema in the way that Druid and Rockset did.
Flattened (denormalized) schema
Flattened schema denormalizes the data model so all tables are merged into one. Flattened version of lineorder table has 41 columns. Benchmark designers were kind enough to provide unique prefixes for all column names, so it was very easy to create a new table, just combining columns from all 4 tables together. Look at the full table definition for the details.
One notable change is that we also adjusted the ORDER BY for the query efficiency:
ORDER BY (S_REGION, C_REGION, P_MFGR, S_NATION, C_NATION, P_CATEGORY, LO_CUSTKEY, LO_SUPPKEY)
All queries use S_REGION, C_REGION in WHERE clause, so we organized a table in a proper order.
In order to populate the table with the original version we used this very simple SQL query:
INSERT INTO lineorder_wide
SELECT *
FROM lineorder LO
LEFT OUTER JOIN customer C ON (C_CUSTKEY = LO_CUSTKEY)
LEFT OUTER JOIN supplier S ON (S_SUPPKEY = LO_SUPPKEY)
LEFT OUTER JOIN part P ON (P_PARTKEY = LO_PARTKEY)It took just 260 seconds in order to populate a flattened ‘wide’ 600M row table on our server.
Queries require hardly any rewrite as well. We removed JOINs and did not touch anything else, since column names did not change.
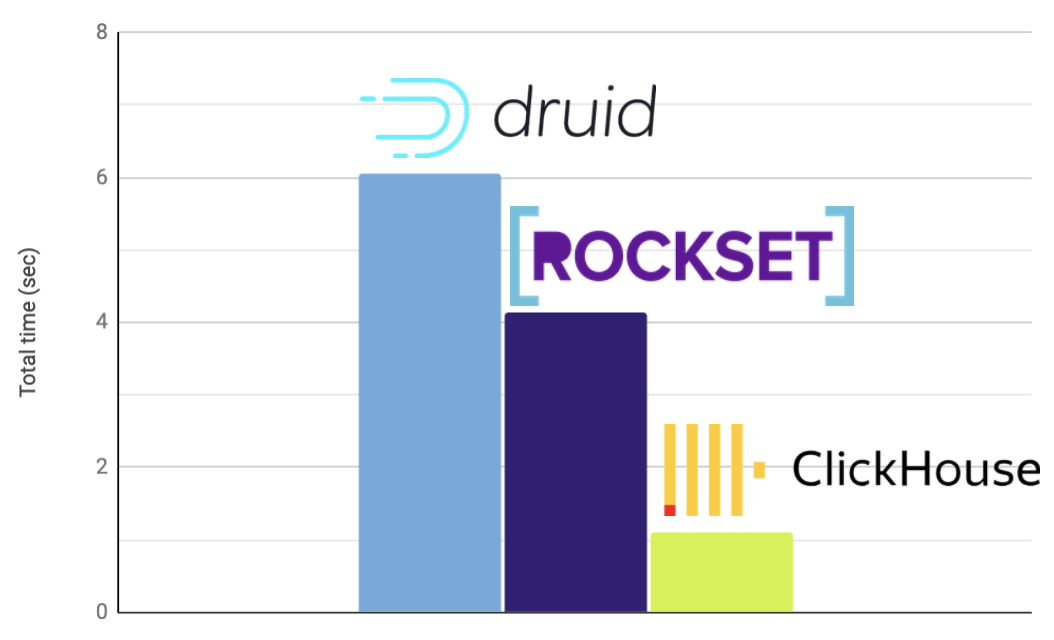
With the flattened table ClickHouse runs at full throttle, while both Druid and Rockset are left far behind.

| Query | Druid, $2.194/h | Rockset, 2.16$/h | ClickHouse, $1.54/h |
| Q1.1 | 1.245 | 0.944 | 0.112 |
| Q1.2 | 0.155 | 0.254 | 0.02 |
| Q1.3 | 0.092 | 0.296 | 0.03 |
| Q2.1 | 0.662 | 0.161 | 0.165 |
| Q2.2 | 0.591 | 0.136 | 0.079 |
| Q2.3 | 0.319 | 0.129 | 0.066 |
| Q3.1 | 0.292 | 0.696 | 0.186 |
| Q3.2 | 0.514 | 0.598 | 0.09 |
| Q3.3 | 0.417 | 0.343 | 0.165 |
| Q3.4 | 0.1 | 0.032 | 0.012 |
| Q4.1 | 0.883 | 0.384 | 0.08 |
| Q4.2 | 0.389 | 0.132 | 0.039 |
| Q4.3 | 0.384 | 0.041 | 0.068 |
| Total run time: | 6.043 | 4.146 | 1.112 |
ClickHouse is simply 6 times faster than Druid and 4 times faster than Rockset!
While schema is simpler and much more performant, it is significantly less efficient from the storage perspective:
┌─table───────┬─sum(rows)─┬───€sum(bytes)─┬─bpr─┐
│ lineorder │ 600038145 │ 62630185595 │ 104 │
└────────────┴───────────┴─────────────┴──────┘The new table is 4 times larger! There is no free lunch — we traded storage for performance. Normalized schemas are always more efficient compared to denormalized ones.
Adding some indices
ClickHouse data skipping indexes are somewhat special. They are not designed in order to locate data faster, but rather help ClickHouse to skip out-of-filter data faster using the table primary ordering. To do that ClickHouse stores additional information for indexed columns inside the primary key, and uses this instead of looking into the column itself if possible.
Q2.2 and Q2.3 both have P_BRAND in the WHERE clause. Can we use a skipping index to improve performance there? ClickHouse skipping indexes are added into two stages. First, index is added into the table metadata, this is an instant operation but it only applies to the new data. Second, the index should be ‘materialized’ with a special statement.
ALTER TABLE lineorder_wide add INDEX p_brand P_BRAND TYPE minmax GRANULARITY 4;
ALTER TABLE lineorder_wide MATERIALIZE INDEX p_brand;
Here we created a minmax index that will store the minimum and maximum value of P_BRAND column for every 4 index granulas (i.e. for every 32768 rows). When running a query with P_BRAND condition ClickHouse will check boundaries and skip 32K rows if value is out of bounds.
With this index query times dropped from 0.079 to 0.057 for Q2.2 and from 0.066 to 0.053 for Q2.3.
Another examples are Q3.3 and Q3.4 that both use S_CITY and C_CITY in the WHERE clause. We can optimize those with the index as well:
ALTER TABLE lineorder_wide add INDEX s_city S_CITY TYPE set(0) GRANULARITY 35;
ALTER TABLE lineorder_wide MATERIALIZE INDEX s_city;
ALTER TABLE lineorder_wide add INDEX c_city C_CITY TYPE set(0) GRANULARITY 7;
ALTER TABLE lineorder_wide MATERIALIZE INDEX c_city;
Here we used a set index that stores all distinct values of cities in index granulas. Granularity values were tuned experimentally, but anything in 10-30 range should work.
Those extra indices reduced Q3.3 query time from 0.165 to 0.047, and the total run ran in under 1 second!
While we demonstrated how performance can be improved with the use of skipping indices, we do not feel this is a fair approach in this benchmark, so we leave it as an example but do not include it in the final results.
Trying out a 15 billion row dataset
600 million rows is a small dataset for ClickHouse, so no wonder queries were very fast. We decided to give a 15 billion rows dataset a try, following Percona research by Vadim Tkachenko. We already experimented with a 500B dataset on an Intel NUC mini-PC last year, so 15 billion rows did not seem like a problem. However, the 15 billion rows SSB dataset happened to be a bit of a challenge for our server, mainly because of the data size. The lineorder table of the original schema design took 400GB of storage, and when converted to de-normalized version it took up an awe-inspiring 1.5TB. Here are our table sizings:
┌─table──────────┬────€sum(rows)─┬─────€sum(bytes)─┬─bpr─┐
│ supplier │ 5000000 │ 197609331 │ 40 │
│ part │ 2400000 │ 43366490 │ 18 │
│ customer │ 75000000 │ 3009778506 │ 40 │
│ lineorder │ 15000001484 │ 397809556981 │ 27 │
│ lineorder_wide │ 15000001484 │ 1557519940578 │ 104 │
└───────────────┴─────────────┴───────────────┴──────┘Our server did not have enough storage initially, but since we were running in Altinity.Cloud we could add extra storage quickly, then resume data loading and start testing the queries.
The results were very interesting. Let’s note that we are testing with 25x larger data size. Normalized schema degraded quite a lot, but our results were better than Vadim’s from a year ago. We were using exactly the same schema as he did, so the improvement comes from ClickHouse evolution. Vadim used ClickHouse 20.4 and we are running 21.1. (As a side note, we were experimenting with schema for this case as well, and could improve query performance twice, but we secured those results for another article).
The flattened schema performed extremely well! Most of the queries were still below 1 second totalling slightly above 16s for the full run! And once we applied skipping indices, the total performance improved by yet another 25%!
| Query | Percona 2020 (CH 20.4) | Altinity 2021 (CH 21.1) | Flattened schema | Flattened with indices |
| Total run time: | 1419.364 | 623.852 | 16.324 | 12.477 |
Note how the effect of skipping indices is more evident on a bigger dataset.
Conclusion
Database performance wars are good opportunities to push technologies to their limits. With the Star Schema Benchmark exercise we took the challenge proposed by Druid and Rockset teams and demonstrated how ClickHouse can perform. With the more traditional normalized behavior there is clearly some work to be done.
However, when we use the same schema approaches as Druid and Rockset, ClickHouse significantly outperformed both whilst using the cheaper AWS setup. We also scaled the dataset 25 times up to 15 billion rows, and ClickHouse could handle it as well, delivering sub second response time for the most of queries.
We welcome the opportunity to participate in more benchmarking competitions as well as find ways to make ClickHouse better. If you are a great C++ developer with database background and want to improve ClickHouse, please drop us a note at hr@altinity.com. We are working on TPC-DS benchmarks among other projects and your contribution may help us to get it sooner. Otherwise stay tuned and watch out new ClickHouse stories in our blog!
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.
When comparing Rockset, Druid and Clickhouse, it’s also important to talk about ingest performance. In this department, Rockset might have the lead since it can ingest a very large amount of rows (row by row, not batches or micro-batches). You also get support for full table joins.