ClickHouse® ReplacingMergeTree Explained: The Good, The Bad, and The Ugly

TL;DR: ReplacingMergeTree is a MergeTree variant that deduplicates rows sharing the same ORDER BY key, keeping only the latest version. Deduplication happens asynchronously during background merges, not at insert time. Until a merge occurs, duplicate rows coexist in the table. To query only the latest version without waiting for a merge, add FINAL to your SELECT. For multi-threaded insert pipelines, use a version column. The row with the higher value wins, which matters when updates arrive out of order. Use ReplacingMergeTree for real-time update pipelines from OLTP sources (MySQL, PostgreSQL), or anywhere you need eventual row-level uniqueness without locking. It is not a substitute for true UPSERT semantics at insert time.
“Every gun makes its own tune“
―Clint Eastwood
The ReplacingMergeTree Engine has been in ClickHouse for 10 years already. It is a very powerful engine when properly used, but it can also shoot you in the foot. One of the main use cases of ReplacingMergeTree is that it allows us to handle real time updates. In particular, we can build pipelines that keep mutable data in OLTP databases in sync with ClickHouse.
In recent releases, ReplacingMergeTree has added some new features, so we decided to give a detailed explanation of the old and new functionality for ClickHouse users. It includes insights into how ReplacingMergeTree works that will enable you to use it effectively in your own applications.
The Basics
Let’s start with basic syntax:
CREATE TABLE [db.]table_name
(
/* columns */
) ENGINE = ReplacingMergeTree
[PARTITION BY expr]
ORDER BY exprThe most important part of ReplacingMergeTree engine definition is the ORDER BY expression. Unlike a generic MergeTree engine, ORDER BY has a different meaning here: it defines an “eventually unique” key for the table. It is much closer to the traditional primary key of OLTP databases, which enforces uniqueness of keys. The difference is that instead of rejecting non-unique values, ReplacingMergeTree de-duplicates them, keeping only the last version.
The ORDER BY for ReplacingMergeTree defines a unique column or a unique combination of columns that acts as a key. When a row with the same key is added to the table, it is considered a new version of the row. ClickHouse then returns the new version in queries and removes old versions in the background during merges. Note that until the old version is removed in the background, both old and new versions can appear in queries. Special syntax is required to query the new version only.
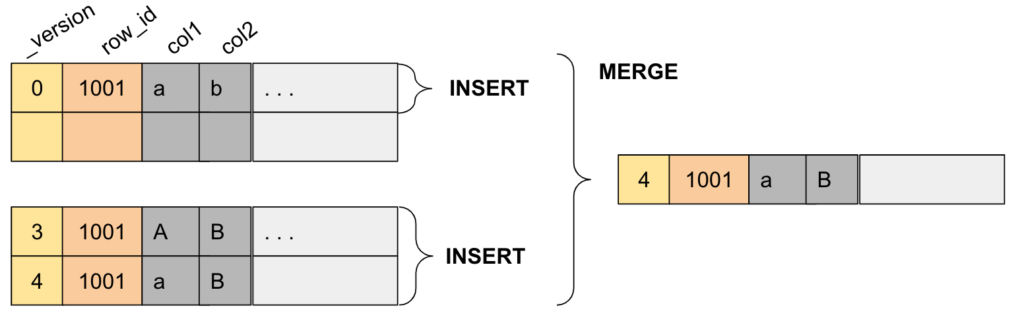
ReplacingMergeTree is useful for two different scenarios:
- Deduplication, when the same data is inserted multiple times due to retries
- Real time updates, when data is inserted or updated in place to replace old values
We will focus on the second case, since it is more interesting. But techniques discussed in this article are applicable to deduplication scenarios as well.
Defining a Good Key
In the ordinary MergeTree table type, ORDER BY is used to define the optimal physical order for queries and compression. In ReplicingMergeTree the ORDER BY key is the basis for replacement logic. Those two goals need to be combined. Let’s take an example.
We will take the 600M rows ‘lineorder_wide’ table used in our recent benchmark of AWS Graviton3 for ClickHouse. The table definition is the following (see full DDL statement here):
CREATE TABLE lineorder_wide (
/* columns */
) ENGINE = MergeTree
PARTITION BY toYYYYMM(LO_ORDERDATE)
ORDER BY (S_REGION, C_REGION, P_MFGR, S_NATION, C_NATION, P_CATEGORY, LO_CUSTKEY, LO_SUPPKEY)Consider we want to convert this table to ReplacingMergeTree in order to do real time updates. We need a modified table definition that includes a unique key in the ORDER BY clause. For this table, LO_ORDERKEY and LO_LINENUMBER uniquely identify the table record. So the Engine definition for ReplacingMergeTree might look like this:
CREATE TABLE lineorder_wide_rmt AS lineorder_wide
ENGINE = ReplacingMergeTree
PARTITION BY toYYYYMM(LO_ORDERDATE)
ORDER BY (LO_ORDERKEY, LO_LINENUMBER)Unfortunately, if we define the table this way, the query performance will dramatically degrade for some queries. For example, this ORDER BY does not allow efficient filtering by S_REGION or C_REGION. Therefore, we need to create the key differently, to serve both performance and uniqueness:
CREATE TABLE lineorder_wide_rmt AS lineorder_wide
ENGINE = ReplacingMergeTree
PARTITION BY toYYYYMM(LO_ORDERDATE)
ORDER BY (S_REGION, C_REGION, P_MFGR, S_NATION, C_NATION, P_CATEGORY, LO_CUSTKEY, LO_SUPPKEY, LO_ORDERKEY, LO_LINENUMBER)Here, we added unique columns at the end of an ORDER BY that is properly optimized for performance.
Best practice: Use the beginning of the ORDER BY to optimize for query performance, and add unique columns at the end.
However, there are two potential issues that such a long ORDER BY may cause.
- The primary key index is stored in RAM, so we increased RAM usage by the size of two columns. If it is a concern, PRIMARY KEY on a subset of ORDER BY columns can be defined. This reduces the index size but does not affect the replacing behavior of ReplacingMergeTree.
- The columns in ORDER BY cannot be updated using replacing logic. If one decides to change P_CATEGORY for a certain order record, for example, the old record will need to be deleted.Therefore, when designing the ORDER BY for ReplacingMergeTree keep in mind what columns can be potentially updated.
Let’s create this table, populate it with the same data as the original lineorder_wide table, and conduct some experiments.
The Good: Realtime Updates
Real time updates in ReplacingMergeTree are implemented with a technique called ‘upserts’, i.e. inserting rows or updating rows for the key that already exists using a single SQL INSERT statement. No special syntax is required.
INSERT INTO table_rmt VALUES(key_col1, key_col2, …. ., col1, col2 ….)
The rules are very simple here:
- If a row with such a key does not exist in the table – it is inserted as is.
- If a row with such a key already exists in the table, the new row is inserted as is, and ClickHouse will remove the old one during the merge process or at query time.
When data is inserted in multiple threads, there can be confusion about what is considered to be the ‘newest’ version of the row. In order to implement proper serialization of updates an additional column can be used:
ENGINE = ReplacingMergeTree([version])
‘version’ here is the name of a column. It can be an integer or timestamp. The row with higher value replaces the lower one for the same key.
Let’s make some updates to our test table. The statement below will insert 100000 rows with all the columns having the same values except for the C_ADDRESS column that is set to ‘N/A’. Note the use of the REPLACE modifier:
INSERT INTO lineorder_wide_rmt
SELECT * REPLACE('N/A' as C_ADDRESS) FROM lineorder_wide
WHERE toYear(LO_ORDERDATE)=1997 AND C_NATION = 'CHINA'
LIMIT 100000
SETTINGS min_insert_block_size_rows = 1000The INSERT is almost instant. We can confirm that data has been inserted, and row counts are different:
SELECT table, sum(rows), sum(data_compressed_bytes), count()
FROM system.parts
WHERE table LIKE 'lineorder%' AND active
GROUP BY table
┌─table──────────────┬─sum(rows)─┬─sum(data_compressed_bytes)─┬─count()─┐
│ lineorder_wide │ 600038145 │ 73535585898 │ 193 │
│ lineorder_wide_rmt │ 600138145 │ 73566038106 │ 234 │
└────────────────────┴───────────┴────────────────────────────┴─────────┘The background process that removes old versions of rows is the normal merge process for MergeTree tables. Merges are scheduled by ClickHouse using some tricky heuristics, so there is no guarantee when replacing logic is applied to the stored data. It might not even happen to particular rows, because ClickHouse stops merging parts after they reach a certain size. Therefore querying the ReplacingMergeTree table requires a little extra footwork to ensure we don’t see old rows.
Querying ReplacingMergeTree
OPTIMIZE FINAL
OPTIMIZE FINAL forces the merge, and also forces ClickHouse to merge all parts in one partition to one part (if size permits). As a result, all updated rows will be properly replaced.
The main problem with this approach is performance. It is slow, locks the table, and can only be used occasionally.
SELECT FINAL
The FINAL modifier for SELECT statements applies the replacing logic at query time. If one were to try 'SELECT * FROM table_rmt FINAL‘, it will be as slow as OPTIMIZE FINAL and may potentially run out of RAM. In queries, however, we normally select a subset of columns and also use WHERE conditions. That dramatically reduces the amount of data that needs to be processed in a query time, and gives good performance even when FINAL is used.
Let’s run some examples. Here is a query 3.1 from the Star Schema Benchmark:
SELECT
C_NATION, S_NATION,
toYear(LO_ORDERDATE) AS year,
SUM(LO_REVENUE) AS revenue
FROM lineorder_wide
WHERE C_REGION = 'ASIA' AND S_REGION = 'ASIA' AND year >= 1992 AND year <= 1997
GROUP BY C_NATION, S_NATION, year
ORDER BY year ASC, revenue DESCIt runs in about 0.9s on my 4 vCPU test instance. The query for ReplacingMergeTree is almost the same. We only need to add FINAL modifier after the table name:
SELECT
C_NATION, S_NATION,
toYear(LO_ORDERDATE) AS year,
SUM(LO_REVENUE) AS revenue
FROM lineorder_wide_rmt FINAL
WHERE C_REGION = 'ASIA' AND S_REGION = 'ASIA' AND year >= 1992 AND year <= 1997
GROUP BY C_NATION, S_NATION, year
ORDER BY year ASC, revenue DESCThis query takes 11s! This is more than 10 times slower, so FINAL comes at a huge expense. But don’t worry, we will show how to address performance in the next chapter.
The other downside is usability. It requires FINAL keywords to be added to SQL queries explicitly. This may be undesirable, especially if ClickHouse is used as a backend of some BI tool. Up until recently, the workaround was to add a VIEW on top of SQL query, like this:
CREATE VIEW view_rmt AS SELECT * from table_rmt FINAL
Starting from ClickHouse version 23.2 there is a more convenient way: the ‘final’ setting. It can be set at the profile level or specified in the query as follows:
SELECT * from table_rmt SETTINGS final = 1
This setting affects all tables used in a query, including subqueries and joins. The advantage of the ‘final’ setting over the FINAL keyword is that the setting can be specified in a session or in a user profile, so there is no need to add it into queries explicitly. You don’t have to rewrite queries to use ReplacingMergeTree.
The ‘final’ setting for ReplacingMergeTree was contributed to ClickHouse by Altinity developers.
The Bad: FINAL performance
Performance of FINAL has improved dramatically over the last 3 years. Before ClickHouse version 20.5 it was single threaded and ve-e-e-ry slow. In 22.6 and above it is multi-threaded and much faster. See the up-to-date status in the Altinity KB article on this topic. Still it is not as fast as one would expect from ClickHouse, but there are techniques that can make SELECT FINAL run fast enough for virtually all purposes.
Merge across partitions
ReplacingMergeTree logic is based on ORDER BY. However, a table may also have partitioning. ClickHouse allows users to replace data between partitions as well, but in practice it almost never happens. (And you can usually fix your PARTITION KEY to avoid it.) There is a special setting in ClickHouse that tells ClickHouse that partitions can be merged and processed independently from each other in SELECT FINAL:
do_not_merge_across_partitions_select_final=1
If we add this setting to the query from the previous section, query time drops down 7 times from 9s to 1.25s! This is just 30% slower than the query without FINAL, and seems quite acceptable.
Hint: We recommend enabling do_not_merge_across_partitions_select_final as soon as you start working with ReplacingMergeTree. If you are using Altinity clickhouse-operator for ClickHouse or Altinity.Cloud (managed service for ClickHouse), this setting is enabled by default. In the rest of the article we will assume it is always enabled.
Missing PREWHERE optimization
FINAL in queries works well if the WHERE condition contains the key columns. Since no merge is happening across the key columns, ClickHouse can load the data using filters – reducing its size – and apply replacing logic afterwards. It becomes different if the WHERE condition does not contain any key columns. For ordinary MergeTree tables ClickHouse uses what is called PREWHERE optimization in this case. It loads a filter column into RAM, applies the filter to the key columns first to identify granules (blocks of compressed data) that have matching values, and then uses this information as an index in order to load other columns efficiently.
Unfortunately, PREWHERE optimization is not implemented for FINAL queries. Queries with filters that were fast without FINAL may turn to sluggish ones again when FINAL is applied. The workaround here is to rewrite the query and emulate PREWHERE logic with a subquery. For example, let’s take this simple query:
SELECT sum(LO_REVENUE)
FROM lineorder_wide
WHERE C_CITY = 'UNITED KI5' AND toYear(LO_ORDERDATE)=1997This query uses a C_CITY column that is not a part of the ORDER BY. It runs in 0.4s thanks to PREWHERE optimization. If we run the same with FINAL for ReplacingMergeTree, the performance drops to very pokey 9s! In order to get good performance with FINAL, we have to rewrite it as follows, emulating the PREWHERE:
SELECT sum(LO_REVENUE)
FROM lineorder_wide_rmt FINAL
WHERE (S_REGION, C_REGION) IN (
SELECT S_REGION, C_REGION
FROM lineorder_wide_rmt
WHERE C_CITY = 'UNITED KI5' AND toYear(LO_ORDERDATE) = 1997
)
AND C_CITY = 'UNITED KI5' AND toYear(LO_ORDERDATE) = 1997This query runs in about 2.5s. Still much slower than the non-Replacing version though, so there’s work to be done to make it approach regular MergeTree performance. PREWHERE with FINAL should be fixed in ClickHouse eventually. See this issue to track the status: https://github.com/ClickHouse/ClickHouse/issues/31411.
The Ugly: ReplacingMergeTree Deletes
Okay, we now know how to handle updates, but what about deletes? There are a few options.
ALTER TABLE DELETE
The standard way to delete data in MergeTree tables is ALTER TABLE DELETE. The main problem is that ALTER TABLE DELETE is asynchronous and does not work for realtime deletes. For realtime deletes we need a way to exclude deleted rows from queries immediately as soon as data has been inserted.
‘deleted’ column
The natural way that every developer thinks of is adding an extra column to flag deleted rows. When a row needs to be deleted, this column is set to 1. We can easily set it to 1 with the same upsert statement as we do for updates. At query time, an extra WHERE condition needs to be added in order to filter out deleted rows.
SELECT ... FROM table_rmt FINAL WHERE deleted = 0 AND <other conditions>
It definitely comes at some expense, but if deletes are rare this is ok. In the background we can also run:
ALTER TABLE table_rmt DELETE WHERE deleted = 1
That will remove deleted rows from the table permanently.
Let’s try to play around with deletes using our test tables. First, let’s add ‘version’ and ‘deleted’ columns to our test table:
ALTER TABLE lineorder_wide_rmt
ADD COLUMN version UInt32, ADD COLUMN deleted UInt8
Next, mark rows that we updated earlier as deleted using INSERT statement:
INSERT INTO lineorder_wide_rmt
SELECT * REPLACE(version+1 as version, 1 as deleted)
FROM lineorder_wide_rmt
WHERE C_ADDRESS = 'N/A' AND toYear(LO_ORDERDATE)=1997Now we can query the table with respect to deleted rows:
SELECT
C_NATION, S_NATION,
toYear(LO_ORDERDATE) AS year,
SUM(LO_REVENUE) AS revenue
FROM lineorder_wide_rmt FINAL
WHERE C_REGION = 'ASIA' AND S_REGION = 'ASIA' AND year >= 1992 AND year <= 1997
AND deleted = 0
GROUP BY C_NATION, S_NATION, year
ORDER BY year ASC, revenue DESCIt is fast, just 1.3s, which is the same performance as the same query without a deleted filter. We had to add an extra condition, though. Is there a way to avoid it? Of course, yes.
Row Policy
ClickHouse has an interesting feature that can help handle deleted rows. It is a Row Policy. Originally developed as a security filter, it can be used in order to filter out deleted rows automatically as well.
CREATE ROW POLICY delete_mask ON lineorder_wide_rmt USING is_deleted = 0 FOR ALL
It’s fast. With this policy, ClickHouse will apply the extra filtering step very early in the query pipeline.
‘Deleted’ Column Revisited
Since version 23.3, ReplacingMergeTree learned how to handle the ‘deleted’ column automatically! That requires adding an extra parameter to the ReplacingMergeTree engine:
Engine = ReplacingMergeTree(version, deleted)
When the ‘deleted’ column is specified, ClickHouse will automatically filter out rows with ‘deleted=1’ at query time! In order to remove those rows permanently, there is an extension to OPTIMIZE TABLE:
OPTIMIZE TABLE table_rmt FINAL WITH CLEANUP
It is more convenient but still not ideal. So there is also a new setting to fix that:
Engine = ReplacingMergeTree(version, deleted) …
SETTINGS clean_deleted_rows='Always'
This magical setting tells ClickHouse to remove deleted rows automatically when merging. No additional actions from the user are needed!
Let’s try to create a new table that uses this feature:
CREATE TABLE lineorder_wide_rmtd AS lineorder_wide_rmt
Engine = ReplacingMergeTree(version, deleted)
PARTITION BY toYYYYMM(LO_ORDERDATE)
ORDER BY (S_REGION, C_REGION, P_MFGR, S_NATION, C_NATION, P_CATEGORY, LO_CUSTKEY, LO_SUPPKEY, LO_ORDERKEY, LO_LINENUMBER)
SETTINGS clean_deleted_rows='Always';
INSERT INTO lineorder_wide_rmtd SELECT * FROM lineorder_wide_rmt;Once data is populated, let’s confirm that delete logic actually kicks in:
SELECT count() FROM lineorder_wide_rmt FINAL
WHERE toYear(LO_ORDERDATE)=1997 AND deleted=0
SELECT count() FROM lineorder_wide_rmtd FINAL
WHERE toYear(LO_ORDERDATE)=1997Both queries return an identical 90950869 rows in about 8s.
Now we can run queries on lineorder_wide_rmtd without the extra ‘deleted=0’ filter!
‘deleted’ column for ReplacingMergeTree was contributed to ClickHouse by ContentSquare developers.
Lightweight DELETEs
Lightweight DELETE is the ClickHouse name for the standard SQL DELETE statement. It is called ‘lightweight’ to distinguish it from heavyweight ALTER TABLE DELETE mutations. Lightweight deletes implement logic similar to the ‘deleted’ column, so it could be used to delete rows. Unfortunately, the implementation is still not complete, and we do not yet recommend using it for anything other than tests. See the list of problems and limitations in this issue: https://github.com/ClickHouse/ClickHouse/issues/39870
Synchronizing ClickHouse With External Data Sources
The rich functionality of ReplacingMergeTree makes it a natural choice when implementing different data synchronization scenarios. For example, it can be used as a tool for replication from an external OLTP database, such as MySQL or PostgreSQL, to ClickHouse. ReplacingMergeTree was first used in pg2ch for logical replication between PostgreSQL and ClickHouse 4 years ago. We use it in the Altinity Sink Connector for ClickHouse. The full implementation details would be outside of the scope of this article, so we will give just a few hints.
We use ReplacingMergeTree with ‘version’ and ‘deleted’ columns. Version is essential for multi-threaded loading. But more importantly, it also allows easier bootstrapping: when the replication starts on a big table, loading the full table over the replication sink may be too slow. Instead, replication may start in the current database log position, and historical data can be imported later with version=0. That guarantees that recently updated rows are not overwritten.
The most difficult part is automatic schema creation, because inferring the proper PARTITION BY and ORDER BY key is hard without user input. In the MySQL case you may get hints from the MySQL (not ClickHouse!) PARTITION BY clause in the source schema.
Conclusion
ReplacingMergeTree is one of the most powerful ClickHouse features. It can handle deduplication and real-time update scenarios. However, querying data is not always efficient. In order to get good query performance one needs to understand how ReplacingMergeTree works, and apply some extra techniques. Properly used, it enables real-time synchronization pipelines from OLTP databases like MySQL or PostgreSQL.
While originally implemented long ago, ReplacingMergeTree continues to be improved by the ClickHouse team as well as developers from other companies, including Altinity. The recent community contributions of ‘final’ settings and ‘deleted’ column makes ReplacingMergeTree much easier to use in applications. The combination of ‘final’ setting and ‘deleted’ columns allow us to query updated and deleted data from ReplacingMergeTree without any changes in SQL! This is a great example of open source collaboration, and we are proud that Altinity is a contributor.
Want to learn more insights about the coolest ClickHouse features? Stay tuned!
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.