Moving Data in Bulk From ClickHouse® to Iceberg Using Altinity Ice

In a recent blog article we introduced the Altinity Ice Toolset, which provides a lightweight Iceberg REST catalog and client that run in any environment. The Ice Toolset is a critical component of our work on Project Antalya, which adapts ClickHouse to use Apache Iceberg tables as primary storage.
This blog takes the next step and digs into ways to move data efficiently from ClickHouse into Iceberg. We’ll demonstrate parallelization, zero-copy Iceberg file registrations, and the latest innovation–automatic loading of Parquet files just by writing them to S3.
Background
Ice is very helpful to load existing Parquet datasets into Iceberg so that ClickHouse and other query engines can see them easily. This is convenient for loading test data, among other things.
As we implemented ice, we were also thinking about another use case: moving data in an automatic, transactional way from ClickHouse clusters into Iceberg. This is a key capability to allow users to extend MergeTree tables transparently onto cheaper, shared Iceberg storage. The following picture illustrates the overall design.
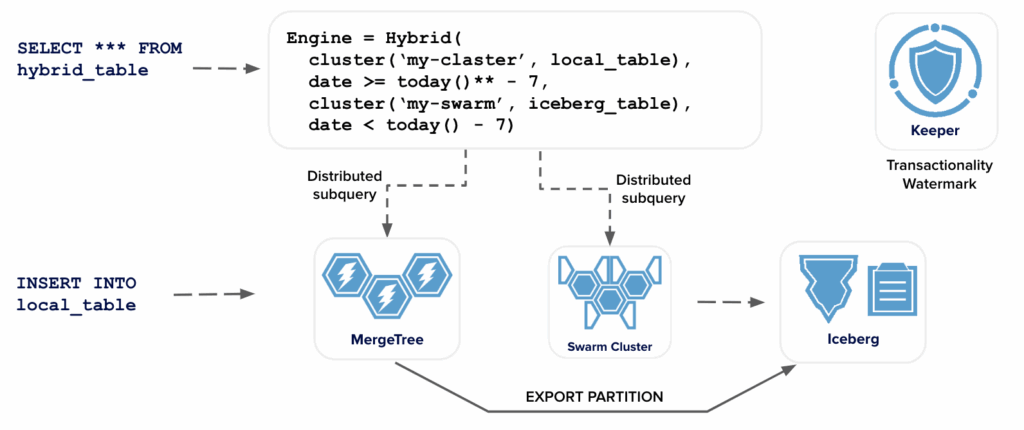
Our goal is to move entire MergeTree partitions containing potentially many Parquet files into Iceberg without losing or duplicating data. Ice handles the last step in the process, namely loading files. Ice includes a number of important capabilities for this purpose.
- Automatic generation of Iceberg table definitions from Parquet files.
- Enabling convenient specification of partition and sort orders in Iceberg, so that they match MergeTree table organization. You have to do it manually for now, but we are working on transfer logic that will apply them automatically.
- Offering flexible options to move large files into the correct location to register them in Iceberg.
- Transparently applying schema modifications in Parquet data. This allows Iceberg tables to morph automatically to match source data in MergeTree tables. (We’ll discuss this particular capability in a future blog article.)
These capabilities are necessary to arrange transferred data so that queries on MergeTree and Iceberg tables get similar results and performance. MergeTree and Iceberg have similar data models and such transparency is feasible. The devil is in the details, and we will mention a couple of issues in this article. For more information on transparent tiering of MergeTree and Iceberg data, see our recent blog article on Hybrid table engine.
One important note: you might wonder why we don’t just use built-in ClickHouse support for writing to Iceberg tables. The answer is simple. At this time, ClickHouse writes to Iceberg are still quite immature and unable to handle many important special cases that arise in representations of MergeTree data on Iceberg. For now the best way to handle data loading is to build on the Java Iceberg libraries. Over time we fully expect to migrate these capabilities fully into ClickHouse.
Setup
We’ll use the Kubernetes setup instructions in the Altinity antalya-examples project.
Follow the README.md to bring up a Project Antalya cluster, including setup of an ice rest catalog running on AWS EKS. The setup looks like the following:
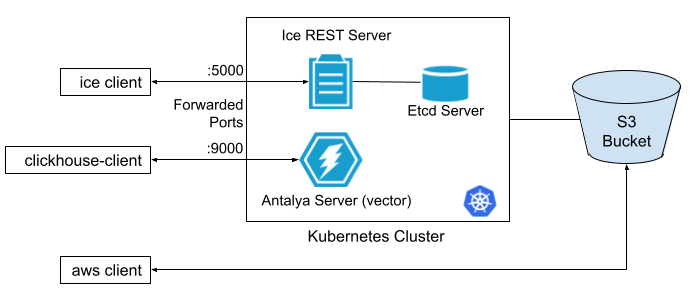
The setup also includes swarm servers, which are not shown here. The AWS instance types are shown in the following table.
| Node(s) | Instance Type | vCPUs | RAM |
| vector (initiator) | m6i.large | 2 | 8 GiB |
| swarm nodes | m6i.xlarge | 4 | 16 GiB |
| Ice REST Server | t3.large | 2 | 8 GiB |
If you want to try these commands at home, they work with any configuration that has an Antalya build listening on port 9000, an Ice REST catalog on port 5000, and an accessible S3 bucket with read/write access. On Kubernetes you’ll need to forward the server and catalog ports as follows:
kubectl port-forward service/clickhouse-vector 9000:9000 &
kubectl port-forward service/ice-rest-catalog 5000:5000 &With the port forwards in place, we’re ready to move data around and have some fun.
Writing ClickHouse Data to S3
Let’s start by picking a table to write into S3. I happen to have a portion of the famous NYC taxi and limousine trip data handy for this experiment. The schema looks like the following. I’ve left out most of the columns so we can focus on differences between MergeTree and Iceberg data.
CREATE TABLE default.tripdata
(
`pickup_date` Date DEFAULT toDate(pickup_datetime) CODEC(Delta(2), LZ4),
`id` UInt64,
`vendor_id` String,
`pickup_datetime` DateTime CODEC(Delta(4), LZ4),
`dropoff_datetime` DateTime,
`passenger_count` UInt8,
`trip_distance` Float32,
…
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(pickup_date)
ORDER BY (vendor_id, pickup_location_id, pickup_datetime)There are around 131M rows in the table. Here is a simple query to check averages. This is a good basis for comparison of queries against Iceberg.
SELECT avg(passenger_count), avg(trip_distance)
FROM tripdata
┌─avg(passenger_count)─┬─avg(trip_distance)─┐
1. │ 1.6571129913837774 │ 4.768565390873597 │
└──────────────────────┴────────────────────┘ClickHouse has excellent support for writing Parquet data. Let’s dump the table data to S3 by inserting the table into the S3 table function with partitioning. Here’s what it looks like.
INSERT INTO FUNCTION s3('s3://mybucket-ice-rest-catalog-demo/PARQUET/{_partition_id}.parquet', 'Parquet')
PARTITION BY concat('month=', month)
SELECT *, toYYYYMM(pickup_date) AS month FROM tripdataWe can confirm the results using the aws s3 command. Looks about right. We’re ready to make some Iceberg tables!
$ aws s3 ls s3://mybucket-ice-rest-catalog-demo/PARQUET/
2025-10-16 16:22:49 143954637 month=201601.parquet
2025-10-16 16:23:07 149758092 month=201602.parquet
…
2025-10-16 16:24:04 59719084 month=201611.parquet
2025-10-16 16:24:20 61518691 month=201612.parquetYou might notice that we don’t sort the rows using SELECT … ORDER BY. This means that the data in the Parquet files is not guaranteed to have exactly the same order as the MergeTree data. ClickHouse selects data in parallel even from single parts, which means that Parquet row groups may be out of order. They won’t exactly match the MergeTree part order.
It turns out that this does not make a lot of difference for ClickHouse queries at the current time, because ClickHouse queries don’t take advantage of Iceberg sort ordering yet. However, it does potentially affect other tools that may read data in Iceberg, such as Spark.
You could try to ensure proper ordering by adding ORDER BY toYYYYMM(pickup_date) to the query. Unfortunately, this breaks on most large data sets, because ClickHouse runs out of memory handling the sort.
Received exception from server (version 25.6.5):
Code: 241. DB::Exception: Received from localhost:9000. DB::Exception: (total) memory limit exceeded: would use 6.06 GiB (attempt to allocate chunk of 4.08 MiB bytes), current RSS: 6.85 GiB, maximum: 6.85 …For now we’ll just omit the Iceberg sort order when we load data. A solution to this problem is on the way: Altinity Antalya 25.6 and above includes the ALTER TABLE EXPORT PART command. It is an Antalya-specific feature to move parts directly and ensures that the part sort order is fully preserved. You can learn more about this command here.
Loading Parquet Data to Iceberg
Basic Multi-Part Copy and File Registration to Iceberg
Now that we have ClickHouse data stored in Parquet files on S3, it’s time to create Iceberg tables. The simplest command to load data is show below. It automatically creates a table from the Parquet schema (-p option), copies the data into the proper S3 location for Iceberg tables, and registers the files.
ice insert blog.tripdata_multipart -p --thread-count=6 \
"s3://mybucket-ice-rest-catalog-demo/PARQUET/*.parquet"This command is painfully slow. The copy downloads Parquet files to the ice client and uploads them again using S3 multipart upload. We can make it a bit better by using 6 threads to upload files in parallel. The 2 vCPU VM vector server takes about 6 minutes to load 131M rows or about 300K rows per second. Not very impressive.
Once loaded, queries on the table are pretty fast. To get this we’ll turn on the Native Parquet Reader, a new feature in ClickHouse 25.8. Bear in mind we’re using a weaklish 2vCPU instance when looking at the performance numbers. If you want to run tests yourself, choose a larger instance size.
SELECT avg(passenger_count), avg(trip_distance)
FROM ice.`blog.tripdata_multipart`
SETTINGS input_format_parquet_use_native_reader_v3 = 1
┌─avg(passenger_count)─┬─avg(trip_distance)─┐
1. │ 1.6571129913837774 │ 4.768565390873606 │
└──────────────────────┴────────────────────┘
1 row in set. Elapsed: 2.529 sec. Processed 131.17 million rows, 1.05 GB (51.86 million rows/s., 414.88 MB/s.)
Peak memory usage: 52.50 MiB.We can still see scaling effects easily. The performance on a swarm cluster on a 2 node swarm cluster with 4 vCPUs per node is much better. (We see some modest differences in the results due to floating point imprecision.)
SELECT avg(passenger_count), avg(trip_distance)
FROM ice.`blog.tripdata_multipart`
SETTINGS input_format_parquet_use_native_reader_v3 = 1,
object_storage_cluster = 'swarm'
┌─avg(passenger_count)─┬─avg(trip_distance)─┐
1. │ 1.6571129913837774 │ 4.768565390873603 │
└──────────────────────┴────────────────────┘
1 row in set. Elapsed: 0.933 sec. Processed 131.17 million rows, 1.05 GB (140.66 million rows/s., 1.13 GB/s.)
Peak memory usage: 90.59 MiB.Background S3 Copy and Setting Partition Metadata
Multi-part upload through the ice client is slow and resource-intensive. Can’t we just move files using server-side copy? S3 has the CopyObject API call, which does exactly that. Let’s use it to move all 12 files at once and register them in a new table. We’ll also add a partition specification to tell Iceberg that the parts are divided by month.
ice insert blog.tripdata_copyobject -p --thread-count=12 \
--s3-copy-object \
--partition='[{"column":"pickup_date", "transform":"month"}]' \
"s3://mybucket-ice-rest-catalog-demo/PARQUET/*.parquet"This completes in just 4 seconds! (On a 2 vCPU machine, no less.)
Selecting averages as we did with the previous example has identical behavior, so we won’t test with that. We will, however, test selecting from a single table part.
SELECT avg(passenger_count), avg(trip_distance)
FROM ice.`blog.tripdata_copyobject`
WHERE toYYYYMM(pickup_date) = 201602
SETTINGS input_format_parquet_use_native_reader_v3 = 1,
┌─avg(passenger_count)─┬─avg(trip_distance)─┐
1. │ 1.6552078901097491 │ 5.060763086054928 │
└──────────────────────┴────────────────────┘
1 row in set. Elapsed: 0.352 sec. Processed 11.38 million rows, 113.82 MB (32.34 million rows/s., 323.44 MB/s.)
Peak memory usage: 39.27 MiB.The performance is quite zippy. The reason is that the ClickHouse server prunes the unwanted partitions automatically during query planning. We can prove that by looking up the metrics for this query in system.query_log. Here’s how you do it. We are selecting one month from a year of data, with one Parquet file per month. We expect to see 11 pruned files. That is exactly what the result shows.
SELECT hostName() AS host, k, v
FROM clusterAllReplicas('all-sharded', system.query_log)
ARRAY JOIN ProfileEvents.keys AS k, ProfileEvents.values AS v
WHERE (initial_query_id = '66db4063-08a1-4020-a252-2e26303718d5')
AND (type = 2)
AND ((k ILIKE '%s3%') OR (k ILIKE '%iceberg%') OR (k ILIKE '%parquet%'))
ORDER BY host ASC, k ASC
Query id: 7c251f49-e99d-498c-8a78-a6b88d7cea07
┌─host─────────────────────┬─k────────────────────────────────┬────────v─┐
1. │ chi-vector-example-0-0-0 │ IcebergMetadataFilesCacheHits │ 4 │
2. │ chi-vector-example-0-0-0 │ IcebergPartitionPrunedFiles │ 11 │
...
└──────────────────────────┴──────────────────────────────────┴──────────┘A Closer Look at Where Iceberg Places Data
The previous example glossed over a problem with S3 CopyObject–it only works with files that are under 5 GiB. Rather than fail, ice reverts back to multipart copy, which means that the largest parts will also use the slowest copy mechanism. That’s exactly the opposite of what we want.
We want to fix upload efficiency, but to do so we’ll have to be clear about where Iceberg stores table data. Here’s a handy diagram.
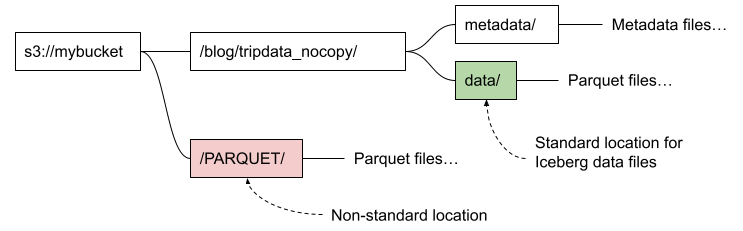
If the files are already under the standard data prefix you can register them where they are, without copying. If they are in a non-standard location, we’ll have to be a bit firmer about our intentions to register data outside the normal prefix in S3.
Loading Files to Iceberg Without Copying
Ice has two options that allow us to register files without copying them. The –no-copy option registers files to Iceberg in their current location, provided that location is the data directory prefix that Iceberg expects. If the files are outside that prefix you must use the –force-no-copy option. We’ll do the latter, because it can register the files we already wrote to the PARQUET directory.
ice insert blog.tripdata_nocopy -p --thread-count=12 \
--force-no-copy \
--partition='[{"column":"month"}]' \
"s3://mybucket-ice-rest-catalog-demo/PARQUET/*.parquet"This operation completes fastest of all–just 1 second to register and commit 12 Parquet files to Iceberg! That includes the work to create the table metadata in the first place.
Important note: When registering files in situ with –no-copy or –force-no-copy you need to think about file naming. If you add new files to the Iceberg table, they need to have different names or you’ll corrupt the table. This is yet another integration issue that Antalya’s ALTER TABLE EXPORT PART will address.
Let’s now check performance on the single part query. It’s not significantly different from the previous query on the blog.tripdata_copyobject table, using the month column that we added on export. This is a good trick for partition specs that have expressions that Iceberg does not support.
SELECT avg(passenger_count), avg(trip_distance)
FROM ice.`blog.tripdata_nocopy`
WHERE month IN (201602)
SETTINGS input_format_parquet_use_native_reader_v3 = 1
Query id: 66db4063-08a1-4020-a252-2e26303718d5
┌─avg(passenger_count)─┬─avg(trip_distance)─┐
1. │ 1.6552078901097491 │ 5.060763086054928 │
└──────────────────────┴────────────────────┘
1 row in set. Elapsed: 0.346 sec. Processed 11.38 million rows, 91.06 MB (32.85 million rows/s., 262.80 MB/s.)
Peak memory usage: 40.09 MiB.The performance is the same as before thanks to the same partition pruning mechanism discussed above.
Important safety note! If you delete the above table using the ice delete-table command, you’ll notice that it does not remove the Parquet files. This is intentional. Among other things, it prevents accidental removal of our files from the staging location. You must either remove them manually or use the ice delete-table –purge option. (The Apache Spark DROP TABLE command has similar semantics as it turns out.)
Loading and Registering Files Automatically to Iceberg
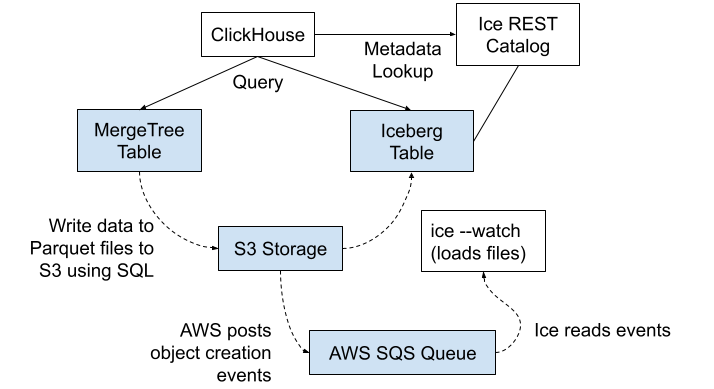
Issuing manual commands to load Parquet data can be a bit fiddly. Wouldn’t it be nice if ice could somehow just load files automatically for you?
Ice has an option that does exactly that: ice –watch. It works by monitoring S3 object creation events, which AWS S3 generates and logs to an SQS queue as shown in the following picture.
To set up, go to the antalya-examples/kubernetes/ice/README.md file and complete the instructions for setting up the AWS SQS queue. Ensure that the bucket and SQS locations are stored in environment variables as follows. The instructions put them in tf.export so you can source them easily in the shell.
export CATALOG_BUCKET=mybucket-ice-rest-catalog-demo
export CATALOG_SQS_QUEUE_URL=https://sqs.us-west-2.amazonaws.com/…002Let’s now use ice to watch for files in S3 and load them automatically. We will write them directly into the proper location. For now do not use –force-no-copy, at least until Ice issue #66 is fixed.
Ice will start printing messages like the following, which means it’s working:
2025-10-18 20:46:35 [main] INFO c.a.i.c.i.cmd.InsertWatch > Pulling messages from https://sqs.us-west-2.amazonaws.com/434208318714/ice-s3watch20251019031756351400000002
2025-10-18 20:46:35 [main] INFO c.a.i.c.i.cmd.InsertWatch > Processing 1 message(s)You can now connect to ClickHouse in another terminal window and insert some data into S3. Here’s the command I’m using.
SET max_insert_threads = 4;
INSERT INTO FUNCTION s3('s3://mybucket-ice-rest-catalog-demo/blog/tripdata_watch/{_partition_id}.parquet', 'Parquet') PARTITION BY concat('month=', month)
SELECT *, toYYYYMM(pickup_date) AS month FROM tripdata;This takes a minute or so on my test rig. After it completes you’ll see a burst of messages from the ice log, that ends with a message like the following:
2025-10-18 20:56:13 [main] INFO o.a.i.SnapshotProducer > Committed snapshot 4286122751557636882 (MergeAppend)That’s it! The data is loaded. We can now analyze the data with queries like our other tables.
SELECT count(), avg(passenger_count), avg(trip_distance)
FROM ice.`blog.tripdata_watch`
WHERE month IN (201602)
SETTINGS input_format_parquet_use_native_reader_v3 = 1Conclusion
The Altinity Ice toolset provides a flexible, simple way to manage Iceberg tables built on Parquet files. This article has illustrated several options for moving Parquet data from MergeTree into Iceberg. If you would like to try them out on your own data, you can set up your own cluster using the instructions in the Project Antalya Examples project on GitHub.
Along the way we touched on a number of issues related to seamless integration of MergeTree and Iceberg data models. There is still work to move data efficiently between locations and query it transparently using a single table. The Altinity blog already digs into this topic and shows how two new Antalya features, ALTER TABLE EXPORT PART and the Hybrid table engine, help you achieve full integration of MergeTree and Iceberg storage in your ClickHouse servers. In an upcoming blog we’ll show how to automatic the process fully.
If you have questions please contact us at Altinity. Antalya builds are also available in Altinity.Cloud. Sign up here for a trial and take them out for a spin.
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.
In 25.8 we can use hive partitioned writes:
https://clickhouse.com/docs/sql-reference/table-functions/s3#partition-strategy
https://github.com/ClickHouse/ClickHouse/pull/76802