ClickHouse® MergeTree on S3 – Intro and Architecture

If you love ClickHouse®, Altinity can simplify your experience with our fully managed service in your cloud (BYOC) or our cloud and 24/7 expert support. Learn more.
As ClickHouse increases in popularity, the volume of analytic data in individual databases is expanding rapidly. It’s not uncommon to see applications that start with a petabyte of data and grow from there. This raises questions about how to store large volumes of data inexpensively and flexibly.
Fortunately, ClickHouse MergeTree tables can store data on S3 object storage, which is cheaper and free from the size limitations of block storage. Virtually all public clouds now offer S3-compatible storage services. MergeTree is the workhorse engine for large tables, and S3 support is an important extension of its capabilities. We have accumulated substantial experience helping customers use it effectively. We are also actively working on improvements to S3 capabilities, along with many other community members.
This blog series provides an overview of managing S3-backed MergeTree tables. The first article describes the S3 storage architecture and how to create a MergeTree table that uses S3. The second article summarizes current best practices for object storage with MergeTree. The third and final article covers how to keep S3 storage healthy. In particular, we’ll show how to clean up orphan S3 files, which arise when ClickHouse table metadata gets out of sync with data stored in S3.
The examples that follow use ClickHouse Official Build version 24.3.2.23 running on AWS EKS managed by Altinity Kubernetes Operator for ClickHouse version 0.23.5. Sample code is located here. You can apply these practices to other public clouds as well as to ClickHouse clusters running outside Kubernetes.
High-level overview of S3-backed MergeTree Storage
Let’s start with a 10,000-foot view. S3-backed MergeTree tables keep the MergeTree file structure on local storage but use object storage to store actual bytes of data. We’ll review how this works in three different cases.
Using S3 in a single ClickHouse server
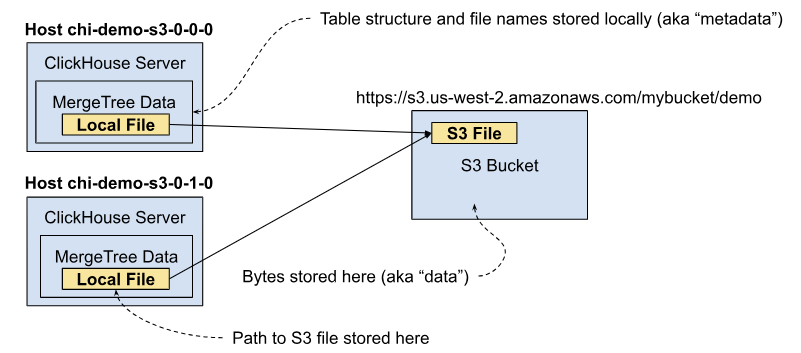
MergeTree tables have the following logical organization. Within a named table we have parts, which are sections of the table that are split according to a partition key. Within each part, we have files, which hold indexes, column values, and descriptive information about the part like file checksums. Files contain the actual data and are stored on the local disk. Here’s a simple diagram of the hierarchy.

When using S3, the bytes are stored in S3 files rather than locally. Here’s a simplified picture that illustrates how it works in a cluster with a single replica.

We call local files “metadata” because they provide the directory structure and file names in which the MergeTree data lives. The actual bytes we call “data.” The mechanisms to store MergeTree data on local storage work essentially the same when you store data in S3. This is an important property of S3-backed MergeTree tables. We’ll talk about why it’s advantageous in a later section.
Using S3 with replicated MergeTree tables
In production ClickHouse deployments it is common to deploy replicas. In this case we have multiple servers each with their own copy of data stored in S3. The following picture illustrates.

Let’s briefly look at the replication process. When you insert a block of data into a MergeTree table, ClickHouse constructs one or more MergeTree parts with file structures (aka metadata) on local storage along with the actual bytes of table information (aka data). It also records the part in [Zoo]Keeper. Other table replicas can look at Keeper to see which new parts they need to fetch. They contact a replica that has the part, download it, and store a copy of the part locally.
The process works the same way when storing MergeTree data in S3, except that we need to download the data bytes from S3 instead of reading them from local storage. Here’s an illustration that tracks the process to transfer a part. Keeper is omitted for clarity.

As this picture shows replication works almost exactly as it would for a locally stored MergeTree table. The key point is that each replica table has its own copy of files in S3, even though they might be written to the same S3 bucket as in this example. The fact that bytes are located in S3 does not affect the process of fetching parts.
Zero-copy Replication
Alert readers (and many ClickHouse users) often point out that it is wasteful for every ClickHouse replica to store its own copy of MergeTree files in S3. After all, they all refer to the same data. Wouldn’t it be more efficient to store a single copy of each file on S3 and have everyone point to it?
There is such a feature, and it’s called zero-copy replication. It is is controlled by a MergeTree setting that turns off replication of S3 files and instead points each ClickHouse server to the same files. Zero-copy replication is experimental. Altinity does not recommend using it unless you are skilled in ClickHouse and understand the risks of use. It’s out there, though, hence worth understanding how it works. Zero-copy replication allows multiple ClickHouse servers to share the same files in S3. Here’s what that looks like.
There’s another benefit–it makes replication faster. Without zero-copy replication ClickHouse must copy files down from S3 to share them with another replica, which then writes the data back to a new S3 file. Zero-copy replication avoids this round-trip overhead.
So why don’t we recommend zero-copy replication? Besides being experimental, it turns out that having multiple servers use the same remote files creates a lot of complexity. ClickHouse must coordinate between servers to keep accurate reference counts of S3 files across all servers. This includes special cases generated by operations like ALTER TABLE FREEZE, just to pick one of many. There are still a number of bugs and more will be found. In addition to having more ways to lose track of files, zero-copy replication puts extra load on [Zoo]Keeper.
There’s also another risk beyond bugs: Zero-copy replication might not be supported in future releases. There are alternative design approaches such as enhancing s3_plain disks, for example by making them writable. This may solve the problem in a better way by combining metadata and data in S3 itself.
The teams we know who use zero-copy replication successfully have their own ClickHouse contributors who can assess risks and fix problems. Check with us if you would like further information.
File names, hard links, and S3 data
We mentioned above that there are advantages to MergeTree accessing S3 storage in a way that imitates local storage as much as possible. The design makes sense if you understand how ClickHouse manages MergeTree storage internally.
ClickHouse uses Linux file system hard links to allow multiple file names to reference underlying data stored in inodes. For example, ClickHouse can instantly and safely rename a table by creating a new file name with its own hard link to the underlying table. ClickHouse uses the same trick for operations like freezing tables, detaching or attaching parts, and altering columns. Thanks to hard links, ClickHouse can perform many table restructuring operations almost instantly without touching the data.
Here is an example of hard links in action. Let’s say two file names reference a file in a part and a frozen version of the same file. The latter would appear if we ran ALTER TABLE FREEZE to create a snapshot of the table data for backup. They both have hard links to the same binary data in a single inode.

The above links represent two views of the same file: one in the active database, and another in a shadow view that is frozen while we run a backup.
The S3 disk implementation extends the MergeTree local storage implementation as shown in the following diagram. Instead of putting data on local storage, ClickHouse stores a reference to a location in S3.

With this approach, operations like table renaming “just work” even when the table data is in S3. This extends to all operations including replication.
The downside is that ClickHouse depends on metadata stored on the local file system to identify S3 files. If the metadata gets lost or out of sync with S3 contents, it can lead to what are known as “orphan” S3 files. We’ll discuss orphans in the third blog of this series.
Setting up an S3-backed MergeTree table
Let’s move away from pictures and look at actual tables. To illustrate, we’ll set up a ClickHouse cluster with two replicas like the picture shown previously. (Sample code is here if you want to follow along.) The cluster runs on Kubernetes, but the principles apply to any ClickHouse cluster that uses object storage.
S3 storage is specified using a storage configuration. The configuration includes a disk to define where storage is located and a policy to combine the disks into volumes with a name. (Storage configuration code is here.)
Important note: In this example we’re going to keep things very simple and store table data directly on S3 only. In real deployments you will normally add a disk cache to reduce API calls to S3. You’ll also use tiered storage to put hot data on block storage. Using block storage allows recently inserted parts to merge without the performance overhead and extra API calls of continuously re-writing the same data on S3. We’ll cover caching and tiered storage in the next article of this series.
<clickhouse>
<storage_configuration>
<disks>
<s3_disk_with_replica>
<type>s3</type>
<endpoint>https://s3.us-west-2.amazonaws.com/mybucket/clickhouse/s3_disk/{installation}/{replica}</endpoint>
</s3_disk_with_replica>
</disks>
<policies>
<!-- S3-backed MergeTree without a disk cache -->
<s3_disk_with_replica_policy>
<volumes>
<main>
<disk>s3_disk_with_replica</disk>
</main>
</volumes>
</s3_disk_with_replica_policy>
</policies>
. . . Note the {installation} and {replica} macros in the S3 endpoint definition. They are generated automatically by the Altinity Kubernetes Operator. It is a best practice to separate the S3 storage used by each replica, and macros do the job nicely. This ensures that data for each server is written to a unique S3 endpoint and will not be mixed with other replicas. If you do not use Kubernetes, you can set these macros yourself and achieve the same effect.
To store data in S3, create a ReplicatedMergeTree table and use the storage_policy setting to choose the above policy.
CREATE TABLE IF NOT EXISTS test_s3_disk_with_replica_local ON CLUSTER `{cluster}`
(
`A` Int64,
`S` String,
`D` Date
)
ENGINE = ReplicatedMergeTree PARTITION BY D
ORDER BY A
SETTINGS storage_policy = 's3_disk_with_replica_policy';
CREATE TABLE IF NOT EXISTS test_s3_disk_with_replica ON CLUSTER `{cluster}`
AS test_s3_disk_with_replica_local
ENGINE = Distributed('{cluster}', currentDatabase(),
test_s3_disk_with_replica_local, rand());The {cluster} macro is another creation of the Altinity Operator. If you do not use Kubernetes, you can define your own cluster name as a macro. This is a good practice for all ClickHouse installations.
Tracking where S3 files are located
Now let’s step through the location of data in detail. The bytes of any file created for this table will be stored in S3. However, the metadata for the table will be in local storage. Let’s add some data so we have something to look at.
INSERT INTO test_s3_disk_with_replica select number, number, '2023-01-01' FROM numbers(1e8);
SELECT count()
FROM test_s3_disk_with_replica
┌───count()─┐
│ 100000000 │
└───────────┘We can now use the system.parts table to find the Linux path to a part that contains actual data. Here’s the query to find the path to the part.
SELECT name, path FROM system.parts
WHERE `table` = 'test_s3_disk_with_replica_local' LIMIT 1 FORMAT Vertical
Query id: d5628233-4c97-4868-b0ed-1237f388bc51
Row 1:
──────
name: 20230101_0_28_2
path: /var/lib/clickhouse/disks/s3_disk_with_replica/store/4b3/4b37a1d0-45fb-4439-a33d-85c744c695d7/20230101_0_28_2/The path is a real directory and it has real files that reference data belonging to the part. Let’s pick the checksums.txt file, which has the following path on the local file system.
/var/lib/clickhouse/disks/s3_disk_with_replica/store/4b3/4b37a1d0-45fb-4439-a33d-85c744c695d7/20230101_0_28_2/checksums.txtIf we looked at checksums.txt for a part for a MergeTree table stored on the file system, it would contain bytes for the binary checksum data. You would see something like the following if you printed it out with the Linux cat command.
checksums format version: 4
d�|ŵc̮ ���e����Q
��DҴ�ЧE������@D]��u�(���ǎ��T��k�����������7Qo2@D\��.��2�
. . .Pro tip: Printing binary data like this can break your terminal. Use the Linux hd command to print the bytes and translated strings in a safe way.
In an S3-backed table, the file contents are quite different. It’s now a reference to data stored in S3 with a path suffix ClickHouse can use to find the file.
3
1 510
510 qfe/xhfrscfqmpzdwcaqippyqmqlpvjsd
0
0SQL queries to locate MergeTree S3 files
We don’t actually have to chain through files on disk to find remote paths for S3-backed MergeTree data. ClickHouse exposes them in the system.remote_data_paths table. Here’s an example of finding the above file. It shows both the local and remote paths to the file.
SELECT *
FROM system.remote_data_paths
WHERE (disk_name = 's3_disk_with_replica') AND (local_path = 'store/4b3/4b37a1d0-45fb-4439-a33d-85c744c695d7/20230101_0_28_2/checksums.txt')
FORMAT Vertical
Row 1:
──────
disk_name: s3_disk_with_replica
path: /var/lib/clickhouse/disks/s3_disk_with_replica/
cache_base_path:
local_path: store/4b3/4b37a1d0-45fb-4439-a33d-85c744c695d7/20230101_0_28_2/checksums.txt
remote_path: clickhouse/demo2/s3_disk_with_replica/chi-demo2-s3-0-0/qfe/xhfrscfqmpzdwcaqippyqmqlpvjsd
size: 510
common_prefix_for_blobs:
cache_paths: []We can double check our work using the Amazon aws-cli. Notice that the actual size of the file in S3 matches the size shown in the file as well as the query to system.remote_data_paths.
$ aws s3 ls --recursive s3://rhodges-us-west-2-mergetree-s3/clickhouse/demo2/s3_disk_with_replica/chi-demo2-s3-0-0/qfe/xhfrscfqmpzdwcaqipp
2024-05-19 09:18:57 510 clickhouse/demo2/s3_disk_with_replica/chi-demo2-s3-0-0/qfe/xhfrscfqmpzdwcaqippyqmqlpvjsdHowever, we also don’t have to use outside tools like aws-cli. ClickHouse itself can read S3 file metadata directly with the s3() table function.
SELECT _file, _path, _size
FROM s3('https://s3.us-west-2.amazonaws.com/mybucket/clickhouse/demo2/s3_disk_with_replica/**', 'One')
WHERE _file = 'xhfrscfqmpzdwcaqippyqmqlpvjsd' FORMAT Vertical
Row 1:
──────
_file: xhfrscfqmpzdwcaqippyqmqlpvjsd
_path: rhodges-us-west-2-mergetree-s3/clickhouse/demo2/s3_disk_with_replica/chi-demo2-s3-0-0/qfe/xhfrscfqmpzdwcaqippyqmqlpvjsd
_size: 510
To wrap up there are three important points to understanding when storing data in MergeTree. For each S3 file that MergeTree uses:
- The MergeTree table directory and files names (aka metadata) are stored in the ClickHouse server local storage. This gives each file a proper name (or two or three…) so that ClickHouse can find it. The local file contains a pointer to an S3 location.
- The data is stored in S3. It’s just bytes in a file with an internal name.
- For each allocated S3 file, there is a row in system.remote_data_paths that contains the mapping from the local to remote file paths. You can also check S3 contents using the aws-cli or selecting data from the s3() table function.
In summary the file metadata is stored locally on ClickHouse and the file data is stored in S3.
Conclusion and more to come
In this first article about MergeTree tables on S3 object storage we showed how MergeTree manages S3 files, how to set up a table with S3, and how to track the location of files. We also briefly discussed zero-copy replication, which is an experimental ClickHouse feature that should only be used if you are very sure of what you are doing.
By the way, this is not the only documentation on how S3 works. You can also look at the following to find out more.
- How S3-based ClickHouse hybrid storage works under the hood – An excellent summary of S3 MergeTree internals, by Anton Ivashkin, DoubleCloud dev lead.
- ClickHouse MergeTree Table Documentation – Describes ClickHouse SQL syntax as well as storage policies, among many other topics.
You can also read the code, which is always good if you want to be sure what’s actually happening. Most of the implementation for S3 behavior is in the ClickHouse Storages directory on GitHub.
In the next article, we’ll provide practical recommendations for setting up S3 storage and managing MergeTree tables that use S3.
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.