Building A Better ClickHouse®
The Altinity development team started to work on ClickHouse server code back in 2018. Since then Altinity engineers have delivered many new features to ClickHouse. Apache 2.0 open source licensing allowed us to contribute improvements to security, object storage and other features that benefit every user, regardless where ClickHouse runs. In this article, we will give a short retrospective of Altinity contributions to ClickHouse and also introduce our view on how ClickHouse should evolve to be the best database on the planet!
If you love ClickHouse®, Altinity can simplify your experience with our fully managed service in your cloud (BYOC) or our cloud and 24/7 expert support. Learn more.
How it Began
In the beginning there was the word. A word from a ClickHouse user who wanted a feature. And this word gave birth to a new creation, a pull request.
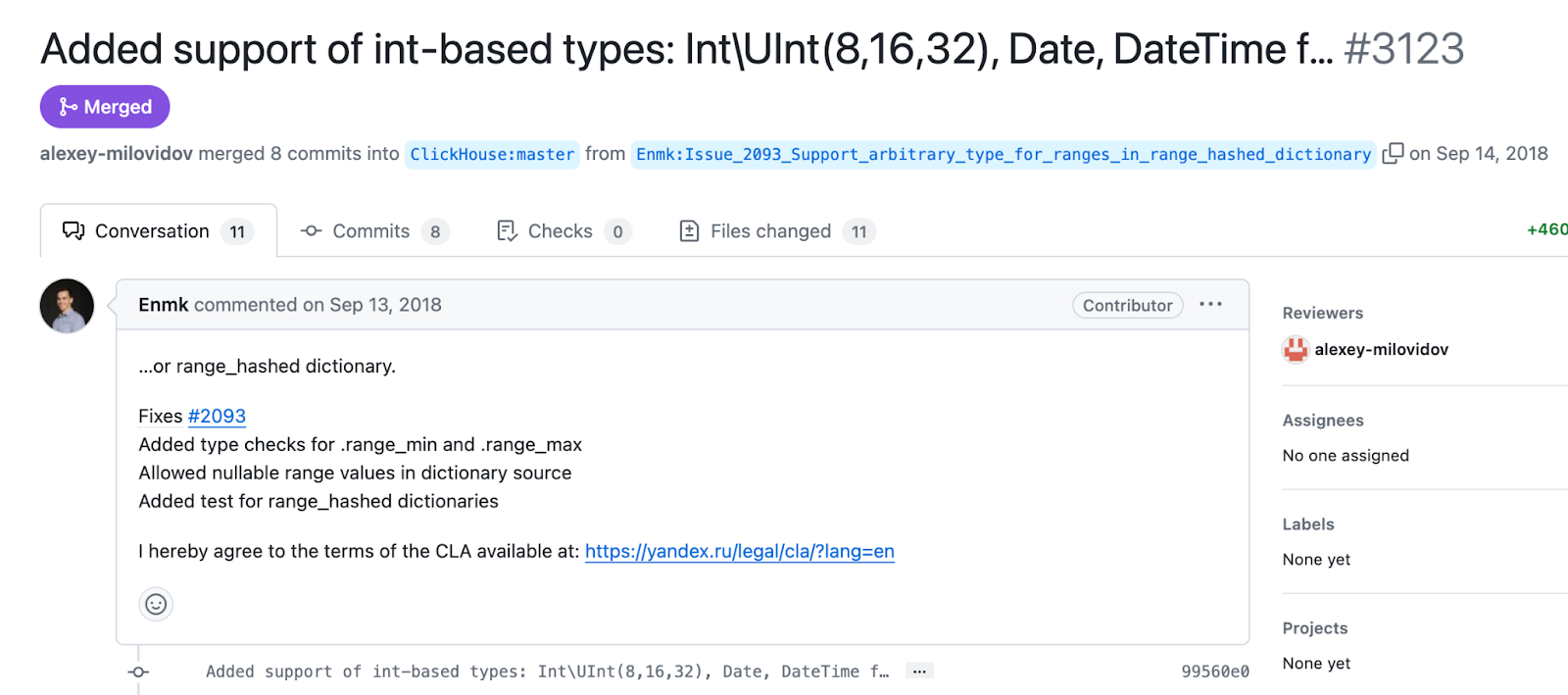
Altinity’s first pull request was lucky to be reviewed and merged in one day. Thanks to ClickHouse original creator Alexey Milovidov, who was extremely helpful and cared about all contributions.
It was a humble start, but it developed fast. In 2019 we contributed 99 pull requests, and in 2020 – 221! Altinity quickly became the number two contributor to ClickHouse after the original creators of it – Yandex. Most of the features that we developed in those years are still in active use by ClickHouse users. That includes TTL rules for moves, geohash functions, first column encodings – DoubleDelta and Gorilla, DateTime64 datatype, ILIKE operator, LIVE VIEW and many others.
More importantly, we started to focus on features that enable ClickHouse usage in enterprises. LDAP authentication, Kerberos authentication, a lot of work around Kafka engine stability, as well as S3 object storage support. We also got very serious about QA and testing. Comprehensive test suites for object storage, TTL and RBAC features ensured that new ClickHouse functionality was well tested. Since then, the Altinity QA team developed 40 test suites for various parts of ClickHouse.
That was an important foundation.
Enterprise ClickHouse
Starting in 2021 we began an ambitious project to create our own public releases for ClickHouse: Altinity Stable Builds. It’s impossible to be a trusted partner for ClickHouse users without the capability to ship binaries with full support extending over years.
By 2023 we could run all ClickHouse tests and produce builds for different platforms including ARM! That was very challenging (read our blog about running ClickHouse integration tests for instance) but it was worth the effort. Since then Altinity Stable Builds, featuring detailed release notes, upgrade instructions, and 3 years of support, became a default choice for many large enterprise ClickHouse users. Along the way we learned a huge amount about topics like operating build runners on cheap Hetzner servers, which we have documented in the Altinity Blog.
While working on builds, we of course continued contributions in the succeeding years. There were 160 pull requests in 2021, and 60 in 2022, though we were focused on build efforts at the time. The PRs continued to improve LDAP support, added partitioned writes to S3, OPTIMIZE DEDUPLICATE, SYSTEM RESTORE REPLICA, governance features, and many more.
In addition to ‘normal’ ClickHouse builds we also added FIPS-compatible versions. FIPS-compatibility is a requirement for regulated environments, so it allowed the use of ClickHouse in applications that previously could not use it.
Last but not least we focused a lot on the ClickHouse ecosystem projects that enable ClickHouse use in enterprises, such as production grade clickhouse-backup utility, maintaining ClickHouse ODBC driver and Tableau Connector, enhancing clickhouse-operator for Kubernetes and many others.
The Community ClickHouse Roadmap
In 2023 it became apparent that ClickHouse is entering a new era. Whereas in years past MergeTree tables might run to a few terabytes, current ClickHouse deployments often extend into petabytes and are growing fast. Many users use ClickHouse to query data residing in data lakes outside ClickHouse. The organizations that deploy such large applications want to operate in their own VPCs on data they control, not in vendor clouds. We took those concerns very seriously and started to think about how we can make open source ClickHouse align with users’ needs.
We initiated a community project to deliver better S3 support in ClickHouse. It was focused on improving object storage support in open source ClickHouse. We worked together with developers from multiple companies on the design, implementation, and testing, but it is not yet complete. We learned, however, that we need to structure community projects in a way that is easy to execute in small increments, and easy to distribute to multiple contributors.
We keep hearing from users that in order to be successful in a competitive space of DBMS options, ClickHouse needs to evolve in a few important areas. It should be able to handle petabytes of data efficiently, whether this data is stored locally or on object storage. It should be easy to operate, and easy to integrate with users’ analytic stacks. We were working on a roadmap targeted towards this vision that we will be executing with community efforts, and we are happy to share it now.
Object storage
Efficient integration with object storage is permission to play in the world of public clouds and big data. When dealing with petabytes of data other options are just too expensive and hard to operate. The current object storage implementation in open source ClickHouse has a lot of issues, and it does not properly solve the problem of separation storage and compute. Community needs to continue working on that. In particular, following seems to be doable in 2024:
- Execute on MergeTree Over S3 Improvements RFC. Phase I is still in progress, and we can start Phase II that is focused on more transparent and consistent implementation.
- Create compact metadata format (see unfinished PR #54997) that will save costs and improve performance for all object storage implementations.
- Provide a tooling to fix consistency issues of zero-copy replication
- Investigate an overlay over object storage as an alternative (some comparison can be found in https://github.com/yandex-cloud/geesefs)
Integration with data lakes
A lot of data is stored elsewhere already. In fact, most of the data is stored outside of ClickHouse and shared with other applications like machine learning. It is expensive to move it to ClickHouse or another database. Instead, ClickHouse should be able to query it accessing the remote storage directly. One of the most popular cross platform formats is Apache Parquet. ClickHouse can query external Parquet data but not very efficiently. it can be improved in small increments that will make it much better. The improvements that we are going to work on include:
- Fix issues with handling globs to make it efficient over large collection of files (#49929 and #53643 – fixed by #62120 in 24.4?)
- Implement parallel filtering on ‘_path’ virtual columns (continuation of #53529)
- Support Parquet bloom filters. (continuation of #52951)
- Logic similar to PREWHERE when processing queries over Parquet (#54977)
- Implement Parquet metadata cache, similar to the one that is implemented for Hive: #36082 (also see a cache for counts #53692)
Integration with external security systems
ClickHouse is rarely used alone, but as a part of the user’s infrastructure. That requires integration with authentication and authorization systems. We implemented LDAP and Kerberos while back, but those are old enterprise technologies that are currently replaced by new ones. So ClickHouse needs to support:
- OAuth 2.0 (continuation of #55199)
- Integration with external secrets management, like HashiCorp vaults, AWS KMS etc.
- Role-based access to AWS S3 buckets. This is an open source implementation of https://clickhouse.com/docs/en/cloud/manage/security/secure-s3#access-your-s3-bucket-with-the-clickhouseaccess-role
- Support AWS S3 VPC endpoints (#53761 – fixed by #62208 in 24.4)
Integration with Kubernetes
Kubernetes is the optimal infrastructure when running ClickHouse in the cloud. ClickHouse was originally developed long before Kubernetes started to be popular, so it lacks some features that make it easier to operate. Following tasks need attention:
- Define a separate endpoint for startup status. #41888
- Enable SYS_NICE capabilities in ClickHouse Docker image
- Investigate if it is possible to have object storage as a Kubernetes resource. https://container-object-storage-interface.github.io
We are also going to publish a clickhouse-operator roadmap separately.
How you can help
ClickHouse is open source. That means everybody can contribute and make it better. ClickHouse has a very solid foundation, thanks to original developers. Altinity contributed hundreds of features and improvements proving that the community may provide valuable contributions. We welcome all ClickHouse users and contributors to join our efforts on making ClickHouse the best open source database on the planet.
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.