Boosting ClickHouse® Data Lake Access: Better S3 and URL Function Proxy Support

If you love ClickHouse®, Altinity can simplify your experience with our fully managed service in your cloud (BYOC) or our cloud and 24/7 expert support. Learn more.
The ability of ClickHouse to interface with S3 data via HTTP/HTTPS is widely recognized and implemented in many systems to separate compute from storage. Yet, for those with ClickHouse clusters behind a network proxy, it hasn’t been smooth sailing. Until now.
Whether you use the S3 table engine, S3 as object storage or even simple URL functions, they all rely on HTTP/HTTPS under the hood. This means ClickHouse acts like a client and is required to initiate HTTP/HTTPS requests for every interaction with external sources.
Depending on the system architecture and where the ClickHouse instances are running, chances are good that external HTTP/HTTPS access is regulated by a proxy server. Up until v23.8.1.2992-lts, ClickHouse would not read proxy settings from the environment. It would only offer an incomplete implementation of proxy settings for S3 storage that did not allow the user to specify distinct proxy servers for HTTP or HTTPS.
Below you can find a few common scenarios that will be discussed throughout this article.
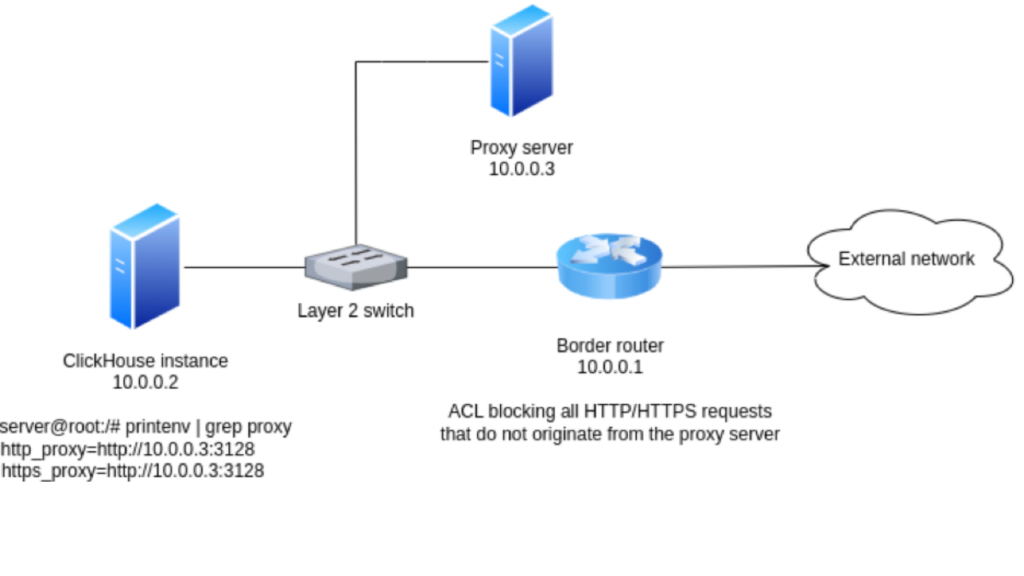
Border Router Blocks HTTP/HTTPS Requests That Do Not Originate From the Proxy Server
In this scenario, represented in the diagram below, the server where ClickHouse is running is configured (proxy environment variables set) to point HTTP and HTTPS requests to the proxy server on 10.0.0.3:3128. One could assume this is enough for requests initiated by ClickHouse to go through the proxy server just like any other common HTTP clients like curl and Google Chrome, but it is not.
Since the border router is blocking HTTP/HTTPS requests that do not originate from the proxy server, ClickHouse is unable to access external sources, and such features will not work.
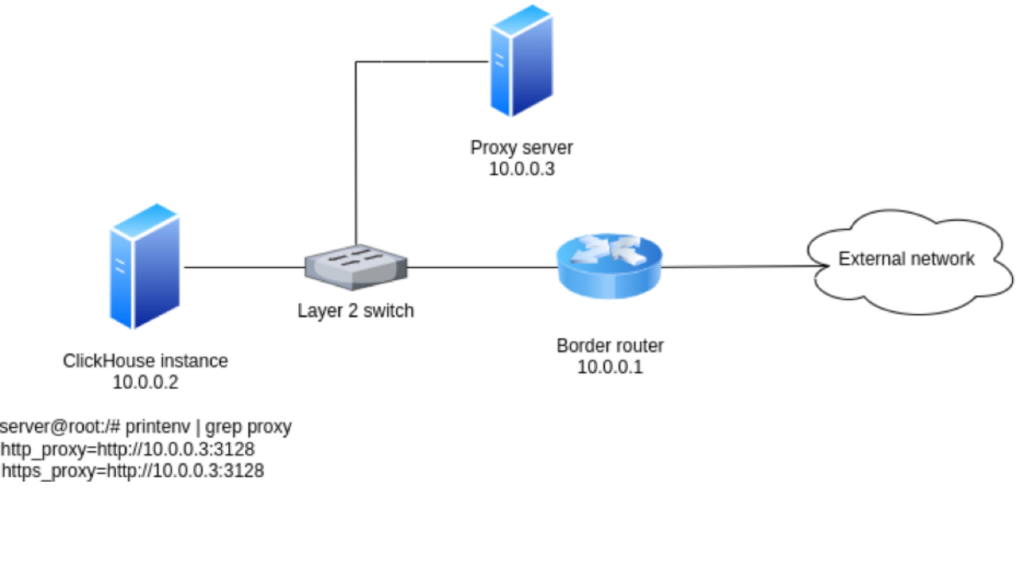
Border Router Allows HTTP/HTTPS Traffic Regardless of Origin
Luckily (or not), ClickHouse instances running with this setup will be able to access external sources. This happens because the proxy server is not a hard requirement since the border router does not impose any restrictions. Therefore, features like S3 storage and URL functions will work as expected.
On the other hand, this may not meet enterprise security requirements since ClickHouse is completely ignoring the system-wide proxy configuration and sending HTTP/HTTPS requests directly to the border router. As a matter of fact, it even creates a weird environment where some requests created by common HTTP clients like curl and Google Chrome go through the proxy, and the ones created by ClickHouse do not.
To fix this, Altinity has implemented complete proxy support for S3 and URL functions in #51749 and #55430.
New proxy settings
Environment Variables
First and foremost, ClickHouse now respects system-wide proxy settings. If you have the http_proxy and https_proxy environment variables properly set in your system, it should work seamlessly.
arthur@arthur:~$ printenv | grep proxy http_proxy=http://proxy1.com:3128 https_proxy=http://proxy2.com:3128
While leveraging environment variables is straightforward and covers the needs of many users, it may not always be sufficient for everyone. Particularly in larger setups with more intricate requirements or diverse infrastructure scenarios, a one-size-fits-all solution using just environment variables might be limiting. There might be a need for load balancing or simply a need to override system-wide settings for specific ClickHouse clusters or nodes.
For such advanced use cases, two additional methods of configuration were implemented: the proxy list and the remote resolver. Both of these methods allow for a higher degree of granularity and control, providing users with the flexibility to tune their proxy settings based on their requirements.
Proxy List
The proxy list configuration method allows the user to specify a list of proxy URIs for each protocol, HTTP and/or HTTPS. It is a great choice when the URI list is known and will not change over time. ClickHouse will round-robin the list, so load-balancing comes for free.
<clickhouse>
<proxy>
<http>
<uri>http://proxy1</uri>
<uri>http://proxy2:3128</uri>
</http>
<https>
<uri>https://proxy1:3128</uri>
</https>
</proxy>
</clickhouse>Remote Proxy Resolver
In case the proxy URI list is not static and might change over time, the remote resolver offers a more dynamic approach. By specifying a remote HTTP server, ClickHouse will send an empty GET request to retrieve proxy settings.
<clickhouse>
<proxy>
<http>
<resolver>
<endpoint>http://resolver/hostname</endpoint>
<proxy_scheme>http</proxy_scheme>
<proxy_port>80</proxy_port>
<proxy_cache_time>10</proxy_cache_time>
</resolver>
</http>
<https>
<resolver>
<endpoint>http://resolver/hostname</endpoint>
<proxy_scheme>http</proxy_scheme>
<proxy_port>80</proxy_port>
<proxy_cache_time>10</proxy_cache_time>
</resolver>
</https>
</proxy>
</clickhouse>Note: proxy_scheme is used to refer to the protocol (HTTP or HTTPS). For backwards compatibility, it has been kept that way. Throughout this article, both terms will be used, and they mean the same thing.
The remote server is responsible for returning the proxy host. Below is an example of a Python script that sets up a very simple remote proxy resolver.
import random
import bottle
@bottle.route("/hostname")
def index():
if random.randrange(2) == 0:
return "proxy1"
else:
return "proxy2"
bottle.run(host="0.0.0.0", port=8080)ClickHouse will form the proxy URI using the following structure: proxy_scheme://proxy_host:proxy_port. Notice proxy_scheme (aka protocol) and proxy_port are hard-coded on the ClickHouse side. It makes this approach a bit less versatile and exists for historical reasons.
It is important to note this method has a soft limit of one remote resolver per protocol. “Soft limit” means the user can specify multiple resolvers for each protocol, but only the first one of each will be picked. This was a design decision to simplify error handling.
Picking only one remote resolver per protocol also means load-balancing should be implemented on the remote server side. ClickHouse will not handle it.
Last but not least, it is obvious this method results in one extra HTTP call being made. Depending on the infrastructure and networking conditions, it might introduce extra latency. To minimize the side effects of this, ClickHouse will cache the remote server responses for the time specified in proxy_cache_time. Time unit is in seconds.
Understanding the Precedence Order
It is crucial to understand the order of precedence when multiple configurations are at play. ClickHouse uses a hierarchy to determine which proxy settings to prioritize, and the order is as follows:
- Remote
- List
- Environment
There is also an extra layer of intelligence in how ClickHouse determines proxy configurations. It’s protocol-based.
For instance, if only HTTP proxy is defined in the remote proxy resolver settings and a HTTPS request is being made, ClickHouse won’t just fail. Instead, it will move down the hierarchy to see if it finds valid proxy settings for HTTPS. This cascading effect adds extra flexibility and allows a mix of configurations to be used.
To better visualize this, consider the below scenario:
A remote resolver only for HTTP.
<clickhouse>
<proxy>
<http>
<resolver>
<endpoint>http://resolver/hostname</endpoint>
<proxy_scheme>http</proxy_scheme>
<proxy_port>80</proxy_port>
<proxy_cache_time>10</proxy_cache_time>
</resolver>
</http>
</proxy>
</clickhouse>A proxy list that contains proxies for both HTTP and HTTPS.
<clickhouse>
<proxy>
<http>
<uri>http://proxy1</uri>
<uri>http://proxy2:3128</uri>
</http>
<https>
<uri>http://proxy1:3128</uri>
</https>
</proxy>
</clickhouse>Environment variables specifying both HTTP and HTTPS proxies.
arthur@arthur:~$ printenv | grep proxy http_proxy=http://proxy1.com https_proxy=http://proxy1.com:3128
Now, if ClickHouse needs to make an HTTPS request, it will:
- Check the remote resolver and find it does not support HTTPS.
- Move to the proxy list, find a valid HTTPS proxy, and use it.
- If for some reason the proxy list also lacked HTTPS, it would then fall back to the environment variables.
However, it is pivotal to understand the caveats:
- The cascading logic is not employed for misconfigurations or proxy failures. If a higher-priority configuration (like the remote) is detected for the request’s protocol, but it’s incomplete (missing endpoint or proxy_port, for instance), ClickHouse will raise an exception without checking alternative methods.
- Similarly, if a well-configured proxy server fails to respond, ClickHouse will not look to lower-priority configurations. This prevents ambiguities and potential misdirections.
Wrap Up and Acknowledgements
Lack of proper proxy support made it difficult for users in locked-down environments to access S3, to the point where it was nearly impossible for those who could not lift up network restrictions. This is another crucial step forward in the community effort to ensure top-notch S3 support in ClickHouse.
The implementation adds three new ways to set proxy servers while keeping backwards compatibility with the limited old implementation. By default, if the proxy is properly configured in the operating system, it will just work out of the box. For users with special requirements like load-balancing and dynamic hostnames, two more advanced options were added: remote and list resolvers.
While the motivation and examples are S3-based, it is not exclusive to that. Simple URL functions also benefit from it. Not only that but it was designed with the mindset of making it a generic proxy resolver for ClickHouse. Any other existing features and future implementations that rely on HTTP/HTTPS communication should be able to plug in proxy support.
Even though it was not discussed in this article for the sake of simplicity, Altinity also implemented the ability to disable tunneling for HTTPS requests over HTTP proxies (#55033). This feature is important for users who want to leverage proxy caching and avoid TLS termination for performance reasons.
Looking ahead, there is more on the horizon. One of the primary developments in the pipeline is the introduction of no_proxy support. This feature will empower users to designate specific hosts that should bypass the proxy, which is important for those with local S3 / HTTP server instances.
The journey of enhancing ClickHouse proxy capabilities was a collaborative effort. Special thanks to @tavplubix, a CH core committer, for his insightful and quick PR reviews. I would also like to acknowledge Vasily Nemkov, who collaborated in all stages of the development. Last but by no means least, a shoutout to our customers, whose feedback and efforts to validate the implementation were instrumental.
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.