Setting up Cross-Region ClickHouse® Replication in Kubernetes

We are connected,
just beyond the silver moon,
rising up above the truth.
It is close and yet so far away
– David Bernstain
Sometimes ClickHouse® applications need to be accessible from multiple regions. The latency between regions may lead to increased application response times and therefore degraded user experience. In order to address it, it is possible to deploy web applications in different regions, but it does not always solve the latency issue. If a web application has to hop to a remote database, like ClickHouse, it is still slow. Having ClickHouse replicas in different regions would help in this case.
Our users often ask how to set up cross-region replication for their ClickHouse clusters, both for high availability and data locality. While it is fairly straightforward to do if one operates ClickHouse on dedicated servers, the Kubernetes deployment is not that trivial. In this article, we will try to fill the gap and explain how to configure a cross-region ClickHouse cluster in Kubernetes using the Altinity Kubernetes Operator for ClickHouse. The same can be done in Altinity.Cloud for our users as well.
Setup
Let’s consider that we want to set up a cross-region cluster in Region-A and Region-B. The main cluster is in Region-A, and this is where all new data is coming to. Reads may go to Region-A or Region-B.
In order for replication to work, we need to ensure that services in both regions can connect to each other. In particular:
- ClickHouse replicas in both regions can connect to the same ZooKeeper cluster on port 2181.
- ClickHouse replicas can connect to each other on replication port 9009
- ClickHouse replicas can connect to each other for distributed DDL queries on port 9000
ZooKeeper is very sensitive to network latency, therefore the ZooKeeper cluster should be deployed in one region. Such configuration does not provide high availability for writes. High availability for writes is discussed at the end of the article.
On the other head, ClickHouse replication is asynchronous by design. So the latency between datacenters does not matter much.
So the desired configuration looks like this:
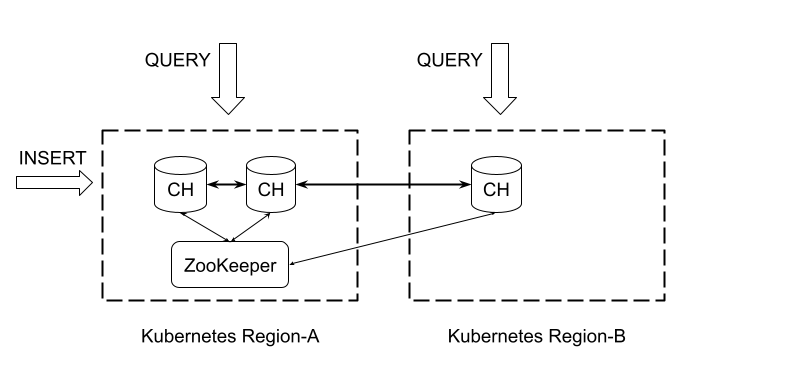
Let’s consider we have deployed a cluster my-cluster in Region-A Kubernetes, and want to attach a replica my-cluster-repl in Region-B Kubernetes.
If you love ClickHouse®, Altinity can simplify your experience with our fully managed service in your cloud (BYOC) or our cloud and 24/7 expert support. Learn more.
Configure Network Between Region-A and Region-B
The main challenge is to configure a network between two Kubernetes clusters. It is not secure to expose ZooKeeper and ClickHouse ports to the Internet, so clusters should be interconnected using a private network. We run a lot of workloads in AWS EKS and will use AWS EKS as an example. Other Kubernetes deployments may require different approaches, but the idea is the same.
In a typical Kubernetes cluster we use Kubernetes services for networking. The service has a name, and cluster DNS gives us an address for that name to connect to. But there is a problem: a typical Kubernetes service resolves to some cluster IP address that is an internal IP address. Unfortunately, cluster IPs don’t belong to a VPC and cannot serve as destinations to send the actual network packet. Kubernetes knows which pods correspond to which services, and configures its nodes to translate cluster IPs to pod IPs before packets leave the host into the VPC network. But there is no way to make it work across the clusters without all the burden of merging the information about all the pods and services from both sides.
The solution is to use headless services, ones with the clusterIP field set to None! Headless services resolve directly to pod IPs. The downside is that when a pod is rescheduled, its IP address changes. So if some application caches DNS, it may get errors until it refreshes the address. Recent ClickHouse versions automatically refresh DNS entries after a certain error threshold (see dns_max_connection_failures), so it is not an issue.
Therefore, we need to set up a shared network between two VPCs hosting AWS EKS clusters in two regions. There are multiple options that can be used. We considered Cilium, Linkerd, AWS VPC Lattice and some others. All those require quite a lot of upfront work. Therefore we opted for the simplest solution, using basic AWS and Kubernetes tools that can be applied to without major infrastructure changes: VPC peering. In addition to peering itself, routing tables and security groups on each side should be modified in order to allow traffic between pod IP addresses for both AWS EKS clusters.
What’s left is to establish DNS resolution for the headless services between clusters. To achieve that, we introduce an additional CoreDNS deployment that is essentially a copy of the kube-system CoreDNS configured to discover records only from the namespace where our ClickHouse pods live.
Then this peering DNS server is exposed as a LoadBalancer service, producing a domain name for the LoadBalancer that can be resolved to a list of IP addresses for the peering DNS service reachable from the peer cluster.
Finally, we updated the kube-system/coredns configmap so that requests that can not resolve with the local service discovery would fall through to the peer’s DNS server.
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough cluster.local in-addr.arpa ip6.arpa
}
prometheus :9153
forward cluster.local <peering-dns-ip-1> <peering-dns-ip-2>
forward . /etc/resolv.conf
Now it works! For example, consider ClickHouse pod in Region-B wants to reach ZooKeeper in Region-A. It makes a regular DNS request asking for zookeeper-headless-a, the local CoreDNS fails to discover it in the Kubernetes cluster in Region-B, and forwards the request to the peering DNS service in the cluster in Region-A, getting the IP address of a ZooKeeper pod from the cluster in Region-A.
Once configured, headless services will cross-resolve between the two environments, so name collisions must be avoided. In particular, ClickHouse installation names have to be different, even though they represent the same replicated cluster.
Setting up Headless Services to ClickHouse Pods
For ClickHouse nodes we can convert services to headless ones. Sometimes it is not convenient to change ClickHouseInstallation directly. Instead we can inject changes using configuration templates. Configuration templates are a unique feature that allows a user to specify extra pieces of configuration that will be merged to all or selected ClickHouseInstallations. For instance, if CHI uses replica-service-template-1 and replica-service-template-1 for node services, we can create template as follows:
apiVersion: "clickhouse.altinity.com/v1"
kind: "ClickHouseInstallationTemplate"
metadata:
name: headless-replica-service-template
spec:
templating:
policy: auto
templates:
serviceTemplates:
- name: replica-service-template-1
spec:
type: ClusterIP
clusterIP: None
ports:
- name: http
port: 8123
targetPort: 8123
- name: client
port: 9000
targetPort: 9000
- name: replica
port: 9009
targetPort: 9009
- name: replica-service-template-2
spec:
type: ClusterIP
clusterIP: None
ports:
- name: http
port: 8123
targetPort: 8123
- name: client
port: 9000
targetPort: 9000
- name: replica
port: 9009
targetPort: 9009
It will be merged by the operator with all ClickHouseInstallations and will convert replica services to headless ones.
Note that the operator does not re-create the service properly if the service has been created with clusterIP and later changed to None. This is a bug that will be fixed in newer releases. If the services are not updated, delete the existing ones and trigger reconciliation.
Attach Region-B cluster to Region-A ZooKeeper
By default, ZooKeeper is configured with a regular service, but a headless service is available as well. So consider ZooKeeper is defined as follows in Region-A cluster:
spec:
configuration:
zookeeper:
nodes:
- host: zookeeper-67668
port: 2181
root: /clickhouse/my-cluster_190775
In the Region-B cluster it should be defined as follows. Note the change of service to a headless version:
spec:
configuration:
zookeeper:
nodes:
- host: zookeeper-headless-67668
port: 2181
root: /clickhouse/my-cluster_190775
In Altinity.Cloud, it is a bit more complicated, since the ZooKeeper configuration for Region-B cluster needs to be overwritten. The custom configuration file overwriting ZooKeeper should be added to the cluster. Note the use of the replace attribute. (The original configuration snippet can be found at Region-A cluster conf.d configmaps, e.g. chi-my-cluster-deploy-confd-my-cluster-0-0):
spec:
configuration:
files:
config.d/zookeeper.xml: |
<clickhouse>
<zookeeper replace=”1”>
<node>
<host>zookeeper-headless-67668</host>
<port>2181</port>
</node>
<root>/clickhouse/my-cluster_190775</root>
</zookeeper>
<distributed_ddl>
<path>/clickhouse/my-cluster/task_queue/ddl</path>
</distributed_ddl>
</clickhouse>
Also, in Altinity.Cloud we need to change the default_replica_path setting on the Region-B cluster to correspond with the Region-A one:
spec:
configuration:
settings:
default_replica_path: /clickhouse/my-cluster/tables/{shard}/{uuid}
If you are running it outside of Altinity.Cloud the default is /clickhouse/tables/{uuid}/{shard}, so no changes are needed because the path does not contain a cluster name.
Create a Cross-zone Cluster Definition for DDLs
The configuration that has been performed so far is sufficient for replication to work, but we need to do a bit more. In order to run ON CLUSTER DDL statements we need the remote_servers configuration that spans across two regions, e.g. my-cluster-cross-zone would reference pods from both clusters.
spec:
configuration:
files:
config.d/my-cluster-cross-zone.xml: |
<clickhouse>
<remote_servers>
<my-cluster-cross-zone>
<secret>my-cluster-cross-zone</secret>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>chi-my-cluster-my-cluster-0-0</host>
<port>9000</port>
</replica>
<replica>
<host>chi-my-cluster-repl-my-cluster-repl-0-0</host>
<port>9000</port>
</replica>
</shard>
</my-cluster-cross-zone>
</remote_servers>
</clickhouse>
It is also possible to change the default cluster behavior (e.g. override the {cluster} macro), but we prefer to keep it separate.
Testing
Let’s test it all together. First, let’s create a replicated table using ON CLUSTER and check that table is created in both regions, and replica paths are correct:
CREATE TABLE test ON CLUSTER 'my-cluster-cross-zone'
(a String) Engine = ReplicatedMergeTree() ORDER BY a
SELECT table, hostName(), zookeeper_path, replica_path FROM clusterAllReplicas('my-cluster-cross-zone', system.replicas)
ORDER by 1,2
FORMAT Vertical
Row 1:
──────
table: test
hostName(): chi-my-cluster-my-cluster-0-0-0
zookeeper_path: /clickhouse/my-cluster/tables/0/0867de24-7a93-4d81-a50f-9eabfbf4e246
replica_path: /clickhouse/my-cluster/tables/0/0867de24-7a93-4d81-a50f-9eabfbf4e246/replicas/chi-my-cluster-my-cluster-0-0
Row 2:
──────
table: test
hostName(): chi-my-cluster-repl-my-cluster-repl-0-0-0
zookeeper_path: /clickhouse/my-cluster/tables/0/0867de24-7a93-4d81-a50f-9eabfbf4e246
replica_path: /clickhouse/my-cluster/tables/0/0867de24-7a93-4d81-a50f-9eabfbf4e246/replicas/chi-my-cluster-repl-my-cluster-repl-0-0
As we can see, ZooKeeper paths on both replicas are the same, including the UUID, and the only difference is the replica name in the replica_path. This is correct.
Now, let’s try inserting some data. On my-cluster we run:
INSERT INTO test SELECT 'region-a'
SELECT hostName(), a FROM clusterAllReplicas('my-cluster-cross-zone', default.test)
┌─hostName()────────────────────────────────┬─a────────┐
1. │ chi-my-cluster-my-cluster-0-0-0 │ region-a │
2. │ chi-my-cluster-repl-my-cluster-repl-0-0-0 │ region-a │
└───────────────────────────────────────────┴──────────┘
On my-cluster-repl we run:
INSERT INTO test SELECT 'region-b'
SELECT hostName(), a FROM clusterAllReplicas('my-cluster-cross-zone', default.test)
┌─hostName()────────────────────────────────┬─a────────┐
1. │ chi-my-cluster-my-cluster-0-0-0 │ region-a │
2. │ chi-my-cluster-my-cluster-0-0-0 │ region-b │
3. │ chi-my-cluster-repl-my-cluster-repl-0-0-0 │ region-a │
4. │ chi-my-cluster-repl-my-cluster-repl-0-0-0 │ region-b │
└───────────────────────────────────────────┴──────────┘
Replication works flawlessly both ways!
Other Options
As you can see, setting up cross-region replication requires quite a lot of manual work both on the cloud provider side and in Kubernetes. Of course most of that can be automated in a managed cloud, and we plan to do it. But what about in open source? Is there a way to make it easier to set up?
Cross-region ClickHouse replication in Kubernetes is not new. I ran an on-prem cross-region replicated cluster even before Altinity was founded back in 2016. But more interestingly, five years ago eBay published an article explaining how they implemented the same in their infrastructure. In order to make it easier to manage, they introduced a FederatedClickHouseInstallation custom resource and a corresponding operator that was responsible for maintaining ClickHouseInsallation resources properly in sync in two Kubernetes clusters. We call this approach “super-operator”, because the Federated operator is responsible for managing ClickHouseInstallations that are in turn managed by the Altinity Operator. Unfortunately eBay did not open source this work. So this spot is still open and waiting for a curious developer to come and implement a solution.
Another thing that is worth a discussion is how to make multi-region writes. As we mentioned in the beginning, ZooKeeper should be in a single region and therefore writes to another region are not possible due to high latency (writes require ZooKeeper coordination). There is, however, an elegant solution presented in the diagram below:
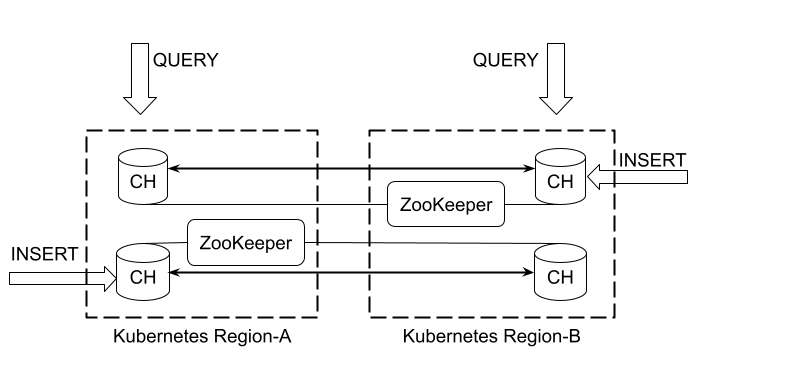
So the idea is to deploy two cross-replicated clusters, every one writing in one region with a dedicated ZooKeeper. Then use a regular Distributed table that would query both clusters together. That way writes may go to both regions and then get replicated to its peers. If any of the regions goes down for whatever reason, the other one contains a full dataset and may handle both inserts and selects. This approach makes even more sense when the ingestion pipelines are region specific.
Finally, one may wonder if the separation of storage and compute makes the problem go away? Is it possible to deploy only compute instances in two regions and attach ClickHouse nodes to shared object storage? While it is technically possible, this solution will face two problems. First, object storage is regional, so if one region connects to an object storage bucket in another region, performance will degrade due to higher network latencies. But more importantly, the network costs may become prohibitive in such a setup. Therefore having a regional data copy is a must for good performance and cost. It can be achieved by object bucket replication using cloud provider tools, but we have not tested this.
Conclusion
In this article we explained and discussed how to configure cross-region ClickHouse replication in Kubernetes. It can be done with the Altinity operator, and also deployed in Altinity.Cloud. There is not enough automation in place yet, so setting it up requires quite a lot of work. However, implementing a cross-region DR solution is usually a significant investment anyways, so this extra work is anticipated.
Making cross-region replication easy to manage is an interesting technical problem. There are several ways to address it. If you are interested to work on that – please contact us, we will be happy to join the efforts.
In closing words I would like to look at the problem from a different angle. We were talking about cross-region replication. But what about cross-region or even cross-cloud data processing? The source raw data is often produced and stored in different regions or clouds. Consider cloud logs, for example. Replicating everything to a single location is not needed in many cases. What is needed, however, is an ability to access data stored in multiple clouds from a single query endpoint. We will discuss this scenario in the next article. Stay tuned!
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.
“So the idea is to deploy two cross-replicated clusters, every one writing in one region with a dedicated ZooKeeper. Then use a regular Distributed table that would query both clusters together. That way writes may go to both regions and then get replicated to its peers. If any of the regions goes down for whatever reason, the other one contains a full dataset and may handle both inserts and selects. This approach makes even more sense when the ingestion pipelines are region specific.”
Super unclear.
If you do as such, how would replicas between DCs know that they have anything to replicate, they dont use the same keepers ensemble.
Furthermore, if you use a distributed engine for writing to both, it’s not “replication” its writing to both. Even if, inconsistency is a matter of time.
Check the picture, it explains better than words.