Performance impact of materialized views in ClickHouse®

TL;DR: ClickHouse materialized views are insert triggers, not traditional views. They fire on every insert to the source table, copying and transforming data into a target table. They do not recalculate at query time. Each MV adds overhead proportional to the amount of data written to the target. In benchmarks, a single MV with no aggregation reduced MergeTree insert throughput by around 55% at small batch sizes, though the impact narrows significantly at larger batch sizes. Performance degrades nearly linearly as you add more MVs, whether chained or parallel. The Null engine results show that the trigger mechanism itself carries minimal overhead. The cost is almost entirely the data written. Keep the total rows written across all MVs in check, and you can run quite a few of them on the same table.
When working with customers, we often encourage customers to use materialized views (or better called insert triggers) to achieve special requirements without much effort. In most common use cases there isn’t a great amount of materialized views in use at the same time.
Typically there’s just one or two materialized views on any given table, so you don’t have to think about the performance impact the views have very often.
But one day, I read a question in the official ClickHouse Slack channel, about some performance problems a user experienced with materialized views. He had around a hundred (yes 100!) materialized views, on one table filling several subsequent tables with them, and the insert performance became quite slow.
So after giving some general tips on how to decrease the impact on his cluster for his specific use case, I decided to a deeper investigation, about how strong materialized views can impact your write performance.
What are materialized views?
First, if you’re not yet familiar with materialized views (MVs) in ClickHouse, here’s a brief explanation.
The key point, as I mentioned earlier, is that the wording can be a bit misleading when comparing ClickHouse materialized views (MVs) to those in other SQL DBMSs. In ClickHouse, MVs are not traditional materialized views but rather insert triggers that activate when data is ingested into a table. This is the most important thing you have to understand when working with MVs in ClickHouse. MVs only get activated when inserting new data to an existing table where the MV sits on top and watches for inserts. Data in the table before the creation of the MV will not be handled by any new created MV.
In newer versions of ClickHouse, Refreshable Materialized Views got introduced which behave more like the imagined classical Materialized Views, but in this article, we want to talk only about the MVs which have been in ClickHouse since the beginning
The second main difference is that the trigger logic and the target are separated.
This means, you have a source table, you will create a target table, looking as you want it to look, and then create the materialized view (the insert trigger) to move (and transform) data from source to target. You can even have multiple triggers from different sources writing into the same target.
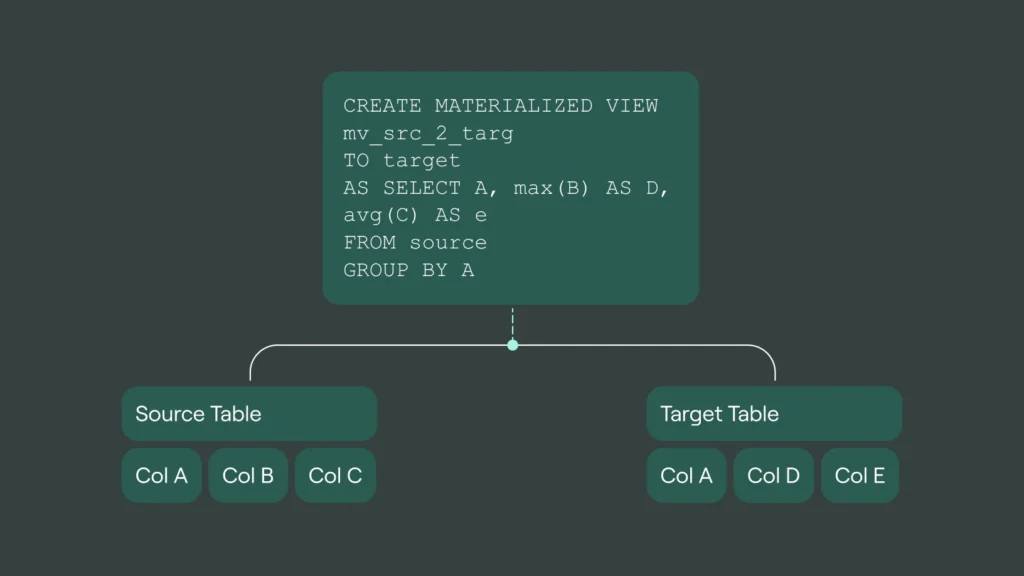
It is very important to understand thatMVs in ClickHouse operate only on the data blocks being inserted at that moment. When performing aggregation, you have to keep in mind that a single group from the original dataset may have multiple entries in the target table since grouping is applied only to the current insert block.
So for an example if you group by column A having the values 1 and 2 within the first insert block into the table, and having values 2 and 3 in the second bunch of the insert, you will still end up with two rows of the value 2 in the target table, as they have been in different insert bunches and therefore not grouped together within the materialized view.
Benchmark Setup
Knowing that materialized views are actually a trigger logic, copying data when inserted into a source table into a separate target table, we can assume that writing data to the target table takes the same amount of time as writing data to the source table.
So each MV would at least double the amount of data written and therefore reduce the insert queries per second by a factor of 50%, as the resources behind ClickHouse will have to write the data twice.
Of course depending on what operations or calculations you do on your MVs, this can change dramatically, as the target rows might be a factor of 100 less depending on aggregations etc, so we keep it simple by not doing any compute intense data transformations in our tests.
To be able to differentiate between IO performance and general overhead, all tests will be made on two different table engines, one will make use of Table-Engine Null (it writes data to /dev/null but still triggers materialized views with the correct data inserted), so we can eliminate the impact of disk performance, the other engine will be the ClickHouse working horse MergeTree.
The second test will be done with two bulk sizes of inserts, inserting 100 rows and one million rows.
All tests are made on a Dell Latitude laptop with a 6 core processor and a consumer nvme disk. As the absolute values are not the goal of the benchmarks, but only the relative difference counts, the exact specs are not relevant.
To get the final benchmark data I made use of the clickhouse-benchmark cli tool.
Baseline
First of all we need our baseline for the measurements. Therefore I created these two tables which will be the source table:
CREATE TABLE raw_mt (
dCol Date,
iCol UInt32,
strCol String
) Engine = MergeTree
PARTITION BY tuple()
ORDER BY (dCol, iCol);
CREATE TABLE raw_null (
dCol Date,
iCol UInt32,
strCol String
) Engine = Null;To generate the data to insert, I make use of rand() and table function numbers():
INSERT INTO raw_null
SELECT toDate('2022-11-01') + number % 30,
rand() % 100000,
repeat('a', rand(1) % 40)
FROM numbers(x)When inserting in batches of x = 100, I could easily get up to 1,730 inserts per second on the Null engine, and also the MergeTree table could get up to 920 inserts per second.
When I increased the batch size to one million rows, the Null table engine reached 32 inserts per second, while MergeTree got down to 5.8 inserts per second (Which still means 5.8 million rows per second inserted on a laptop, so not so slow at all…).
Adding a materialized view
As we have our baseline for inserts without any materialized views impacted, let’s see how the performance of inserts will change when a MV is involved.
First of all we need a target table where the MV should send its data to. To keep things fair in comparison we’ll create everything again in a set of Null and MergeTree engines:
CREATE TABLE mv_mt_0 (
dCol Date,
iCol UInt32,
strCol String
) Engine = MergeTree
PARTITION BY tuple()
ORDER BY (dCol, iCol);
CREATE TABLE mv_null_0 (
dCol Date,
iCol UInt32,
strCol String
) Engine = Null;We keep all columns exactly the same, to just measure the performance of the insert in the views, without being affected by any functions at all.
This also means that our view declaration looks quite simple:
CREATE MATERIALIZED VIEW mt_0_trig TO mv_mt_0 AS
SELECT * FROM raw_mt;
CREATE MATERIALIZED VIEW null_0_trig TO mv_null_0 AS
SELECT * FROM raw_null;Now after clearing the raw_mt table, I restarted the insert process benchmark.
When inserting with a batch size of 100, the Null engine still handled 1,007 inserts per second, while the MergeTree table achieved 412 inserts per second.
This means around 42% less inserts for the Null table while the impact on MergeTree with 55% is a bit higher, but still not very harmful.
When increasing the batch size to one million, the Null engine achieved 30.7 (4% slower) inserts per second, while MergeTree reached 3.6 (38% slower) inserts per second.
| Batch Size | Engine Null — Direct Insert | Engine Null + 1 MV | MergeTree Direct Insert | MergeTree + 1 MV |
| 100 | 1733.6 | 1007.5 | 923.3 | 411.9 |
| 1 Million | 32.1 | 30.8 | 5.8 | 3.7 |
These results are already quite interesting.
Especially for MergeTree, adding a single materialized view leads to a reduction of insert queries by half. But on the other hand it also results in double the rows written to disk as both tables get their data, so the total amount of rows per second written has not changed.
Meaning adding a single MV to a table will normally not hurt your performance at all, but what if we need more of them.
Chaining multiple views
When building ClickHouse pipelines, you may want to chain multiple materialized views in a row. Maybe the first step is to filter out malformed data, the second step is adding to hourly aggregates and the third step fills a daily aggregation.
Of course normally the Data would change in between two MVs, and most likely will be reduced regarding size or rows, but to keep measurement easier, we will just move the same data around even more.
Let’s just create a bunch of target tables for MVs like we did before:
CREATE TABLE mv_mt_X (
dCol Date,
iCol UInt32,
strCol String
) Engine = MergeTree
PARTITION BY tuple()
ORDER BY (dCol, iCol);
CREATE TABLE mv_null_X (
dCol Date,
iCol UInt32,
strCol String
) Engine = Null;Just replacing the X with 1 to 50 depending on how long our chain should be.
Then we create our triggers accordingly to move the data through the chain:
CREATE MATERIALIZED VIEW mt_X_trig TO mv_mt_X AS
SELECT *
FROM mv_mt_(X-1);
CREATE MATERIALIZED VIEW null_X_trig TO mv_null_X AS
SELECT *
FROM mv_null_(X-1);So I did the same insert benchmarks, using chain length of 5,10 and 50. For better readability I’ll put them in two tables and add the result of the previous benchmarks without MV and a single view. Unit is still inserts per second:
Null Engine:
| Batch Size | No View | Length 1 | Length 5 | Length 10 | Length 50 |
| 100 | 1733.6 | 1007.5 | 459.5 | 273.3 | 67.3 |
| 1 Million | 32.1 | 30.8 | 29.9 | 28.8 | 21.8 |
Mergetree Engine:
| Batch Size | No View | Length 1 | Length 5 | Length 10 | Length 50 |
| 100 | 923.3 | 411.9 | 188.9 | 95.9 | 16.7 |
| 1 Million | 5.8 | 3.7 | 1.3 | 0.7 | 0.15 |
For better visualization, I put the values of the MergeTree Benchmark on a Graph, based on a double logarithmic scale, to better show the linearity of inserts per second and amount of MVs involved:
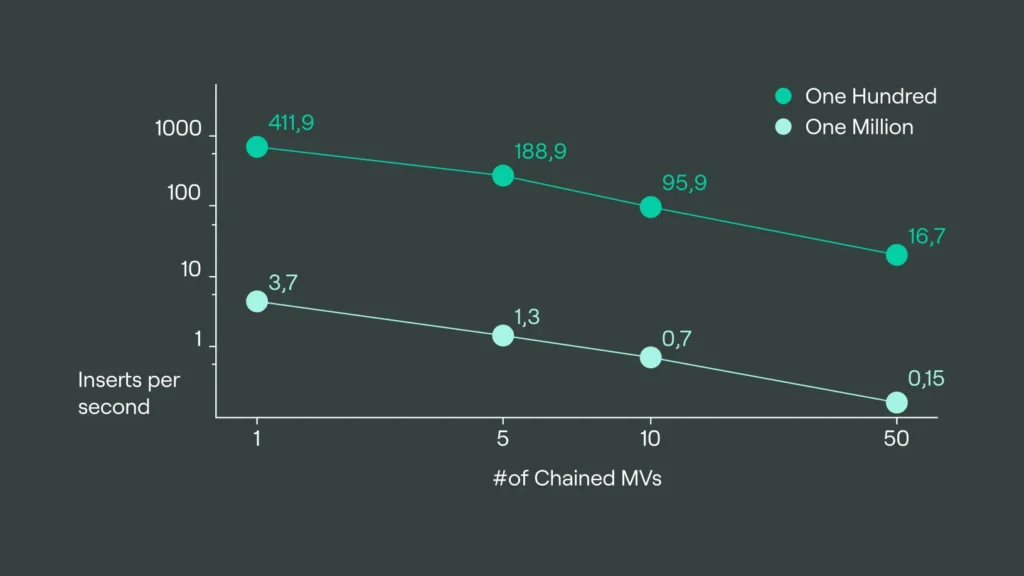
MergeTree Inserts (Chained MVs)
As you can see, the performance of the Inserts degrades nearly linearly, meaning the impact of the trigger itself is negligible. When we look at the results from the Null engine, where writes have no impact, we can still see some sort of degradation, which of course is some overhead from starting the insert process etc.
Multiple views at once
Okay, so we saw that chaining a lot of views slows down insert performance nearly linearly. Which makes sense, when you think of it as a cascade, filling one table after another. But what about having one source table, and insert data into multiple target tables at once.
For tables mv_mt_X and mv_null_X the definitions will stay the same as they have been in the chaining benchmark, but we will adjust the Materialized view creation (i already deleted the old ones):
CREATE MATERIALIZED VIEW mt_X_trig TO mv_mt_X
AS SELECT *
FROM raw_mt
CREATE MATERIALIZED VIEW null_X_trig TO mv_null_X
AS SELECT *
FROM raw_nullAgain I ran clickhouse-benchmark for 5,10 and 50 target tables, and put the result into the following tables:
Null Engine:
| Batch Size | No View | Para 1 | Para 5 | Para 10 | Para 50 |
| 100 | 1733.6 | 1007.5 | 472.2 | 272.2 | 66.3 |
| 1 Million | 32.1 | 30.8 | 29.7 | 29.0 | 21.9 |
Mergetree Engine:
| Batch Size | No View | Para 1 | Para 5 | Para 10 | Para 50 |
| 100 | 923.3 | 411.9 | 169.5 | 89.4 | 18.2 |
| 1 Million | 5.8 | 3.7 | 1.2 | 0.7 | 0.16 |
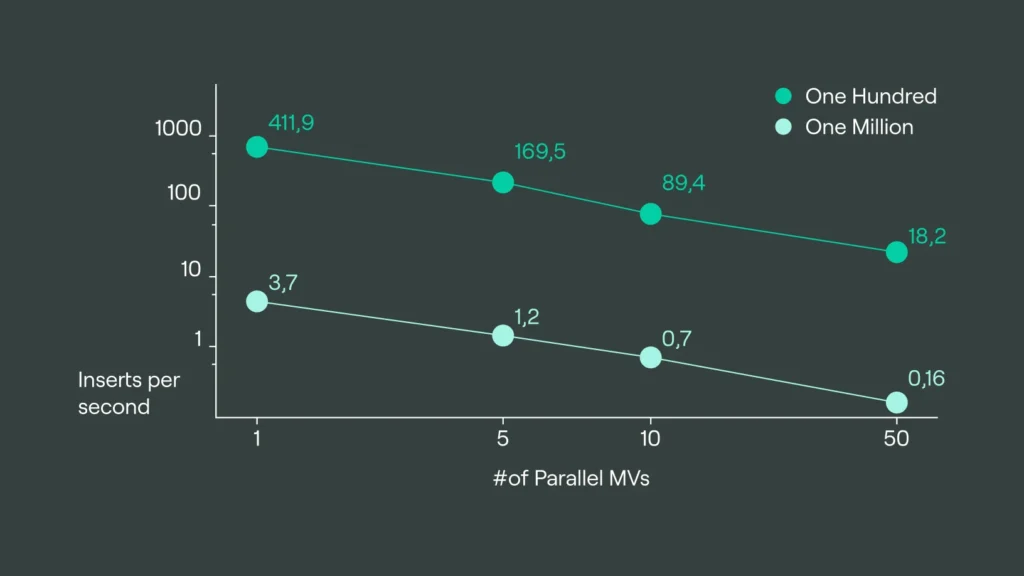
As you can see the numbers and graphs are nearly identical. If you think only about the data inserted, this totally makes sense, as the limiting factor will be IOPS and disk bandwidth anyways, but if your target tables are strongly aggregated, it might be worth thinking about parallelization here (wink @ clickhouse devs).
On the other hand, always keep in mind, we are talking about inserts per second in these benchmarks, but for optimal results you should not have too many inserts per second, but rather increase batch sizes of your inserts.
Multiple views with filters
As we saw in the last two benchmarks, it doesn’t really make a difference if you chain views or have them directly on the source table.
At least when working with all the data in the target. But how much impact does the amount of data really have?
So we clean our tables again, drop all trigger definitions and create another bunch of materialized views:
CREATE MATERIALIZED VIEW mt_X_trig TO mv_mt_X
AS SELECT *
FROM raw_mt
WHERE iCol % maxX = X;
CREATE MATERIALIZED VIEW null_X_trig TO mv_null_X
AS SELECT *
FROM raw_null
WHERE iCol % maxX = X;This time we add a filter condition on the integer column, using modulo of the total number of views per run. As all values are random, this should split the data approximately equally between all target tables.
These are the results (again No View and 1 View are only for Comparison, as nothing changes).
Null Engine:
| Batch Size | No View | Filter 1 | Filter 5 | Filter 10 | Filter 50 |
| 100 | 1733.6 | 1007.5 | 360.1 | 200.3 | 49.1 |
| 1 Million | 32.1 | 30.8 | 20.0 | 15.5 | 6.9 |
Mergetree Engine:
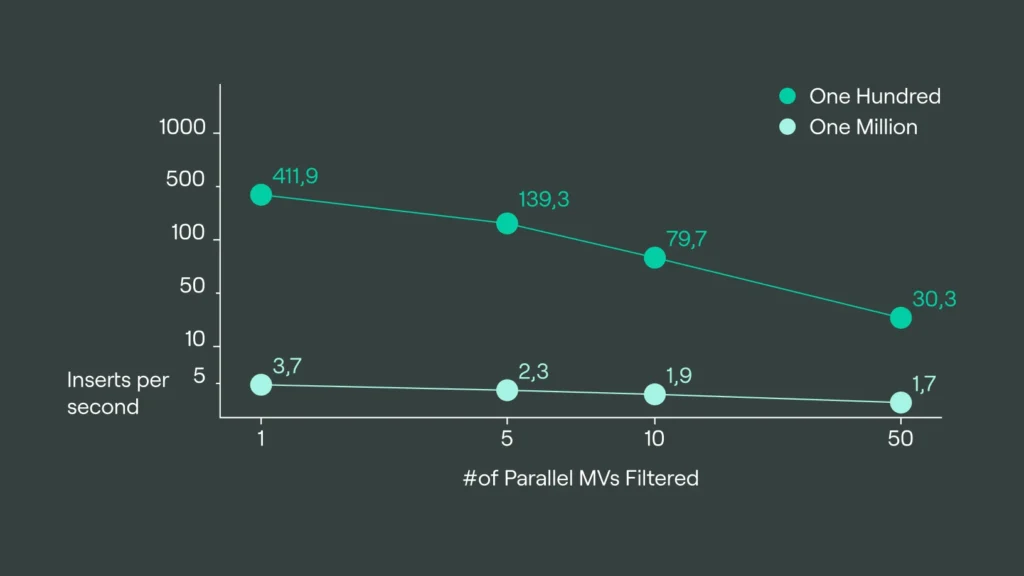
| Batch Size | No View | Filter 1 | Filter 5 | Filter 10 | Filter 50 |
| 100 | 923.3 | 411.9 | 139.3 | 79.7 | 30.3 |
| 1 Million | 5.8 | 3.7 | 2.3 | 1.9 | 1.7 |
Now we see a very interesting result. The absolute insert speed goes down on the Null engine, because it has to apply the filter for every target table, and therefore the compute makes things a little bit slower, but still stays nearly linear in the long run.
But for MergeTree tables, when we use a batch size of one million rows, we see that the degradation of the insert speed becomes a lot smaller compared to the parallel views without filters. It nearly has the same amount of inserts with 50 targets as with 10. So the amount of Materialized Views does not have a large impact anymore, and it solely relies on the amount of data written.
Conclusion
So, what does this mean for our customer with 100 materialized views?
As long as the data isn’t significantly reduced, the insert speed could degrade almost linearly, therefore hundred times less insert performance can be a deal breaker.
However, we observed that the mere existence of views doesn’t introduce significant overhead.
For that special question asked on the ClickHouse Slack channel, the person had those 100 MVs filling around 5 target tables with different logic.
I proposed the solution of introducing multiple layers of views:
The first layer should just reduce the data written, so collecting only the data needed for a special kind of target table. Then the second layer can apply the logic he needed in his view only on the subset of the data, which results in a lot less overhead.
In the end, Materialized Views are a very powerful tool to implement pipelines in ClickHouse and keep your application clean. And as long as you don’t over exaggerate on the total rows written, you can have quite a lot of them running on the same table.
Originally published by Stefan while he was at Double.Cloud.
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.