Fast MySQL to ClickHouse® Replication: Announcing the Altinity Sink Connector for ClickHouse


Transactional Databases like MySQL and PostgreSQL routinely process hundreds of thousands of transactions per second on busy web properties.
For analyzing those transactions in real-time an analytic database like ClickHouse is a perfect fit as it provides a lot of benefits like columnar storage, efficient data compression and parallel query processing. These benefits translate to cost savings and performance improvements for the end-user.
Real-time Streaming Analytics
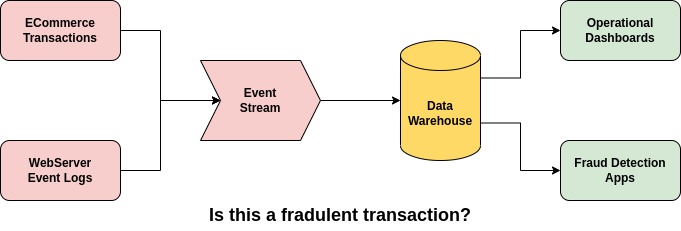
A lot of organizations need to be able to analyze and visualize the metrics in near real-time on a dashboard. A traditional ETL process runs overnight after the end of the business day and transfers the data from Transactional databases to Analytical Databases. Then aggregation is performed so that the metrics can be visualized in BI tools like Superset, Tableau, and others.
The major drawback with this approach is that decision-makers like C-level executives are not able to visualize metrics in real-time. Given the current supply chain shortages due to the pandemic, inventory management is a key metric that will be beneficial if it’s tracked in real-time. Businesses that are able to make key decisions quickly can adapt better than businesses where metrics are available after a day.
Industries that need to track fraudulent transactions can also hugely benefit from streaming analytics. Imagine getting flagged for a suspicious credit card transaction in near real-time.
For this requirement, dumper tools which provide a one-time dump of data from MySQL/PostgreSQL would not be very useful. An ETL solution that constantly streams changes from the transactional databases to OLAP(ClickHouse) would be ideal.
Existing Solutions
Now that we have discussed the benefits of real-time analytics, let’s analyze some of the existing options to transfer data from MySQL to ClickHouse.
MaterializedMySQL: This is part of ClickHouse which enables connecting directly to a MySQL instance and transferring the data real-time. Some of the drawbacks are it does not support shards/replicas and does not provide flexibility in choosing the tables that need to be replicated. Also, it is still in the experimental stage.
Kafka Connect – JDBC: This is another option where the following components can be used to transfer data.
- MySQL Debezium source connector.
- Kafka Connect Process
- Kafka Connect JDBC Sink connector
Drawbacks with this approach are that the Data types are not correctly mapped from MySQL to ClickHouse. For example, the DateTime range in MySQL is longer than the DateTime range in ClickHouse. Also the JDBC driver does not support Exactly once semantics(which we will explain below) and does not support Inserts and Updates, no support for Schema Evolution.
eBay Block Aggregator: This solution developed by eBay addresses the key concerns of data duplication/loss and recovery in case of Kafka failures. Possible data duplication is identified using a standalone component called ARV which analyses the Kafka offset information and flags anomalies. Data from Kafka are buffered in blocks before they are persisted in ClickHouse. Metadata of the block are maintained in a separate Kafka topic. In case of failure of the Block aggregator component, a new component can read the metadata to re-create the block of data. This solution is only aimed towards reading data from Kafka.
A New Solution
To address the drawbacks mentioned above, we decided to implement a new replication solution for transferring data from MySQL to ClickHouse. Say hello to the Altinity Sink Connector for ClickHouse.
The work is completely open-source and is licensed under Apache 2.0. We encourage you to try the project and participate in the development. Participation could include testing (issues), ideas (discussion), and code contribution (Pull Requests). It’s the same pattern Altinity follows for all open source projects we run or maintain.
Project Objectives
Even though the main goal was to replicate data from MySQL to ClickHouse we also wanted to develop a solution that will make it easier for Engineers to configure, deploy, maintain and operationalize this solution in an easy way. The following is the list of objectives for developing this new solution.
- Replication: Our core objective is to replicate/mirror data from MySQL to ClickHouse. Users will be able to leverage the benefits of ClickHouse to perform analytics at scale.
- Performance: We have users who need to load millions of rows per second. High performance was therefore a key requirement. We have added metrics to monitor throughput, CPU, and memory usage.
- No Data Loss or Duplication: This is another key requirement for any customer running financially critical data workloads. It is not fun when the dashboard shows incorrect numbers because of data duplication or data loss. Whenever this happens it forces Data Engineers to do a back-fill or re-run an entire pipeline which could take hours/days.
- High Availability/Fault Tolerance: Our clients maintain production environments that are expected to run 24/7. They cannot afford to have any down-time. Our core objective is to design this solution so that in case of a failure it is easily recoverable without any side effects.
- Schema Evolution: Data from source systems are constantly changing/evolving because of either new data fields captured from the user (Example: Sentiment analysis of survey responses). We need to be able to support this new data field without affecting the SLA.
- Transactions Support: MySQL’s strength is support for transactions. Even though ClickHouse does not have full support for transactions, we wanted to design a solution which will allow that transactional information to be persisted in ClickHouse so that it’s easier for troubleshooting and Data Lineage.
- On-Prem/Cloud/Kubernetes Support: Depending on the industry, clients might be running their workloads on-premises or on the cloud. Our primary objective is to design a solution that works everywhere and is easily maintainable with monitoring capabilities.
- Extensibility: Even though our initial goal is to support MySQL we would like to leverage the effort to support other transactional databases like PostgreSQL, MariaDB, and MongoDB.
Architecture:
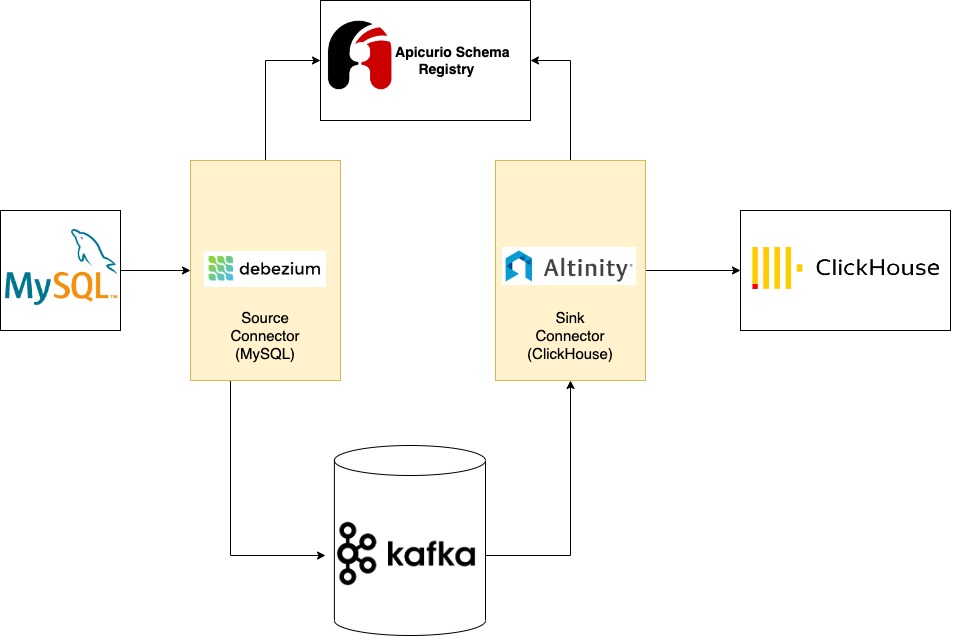
Debezium: (CDC) Change Data Capture is a well established technique to read row-level changes from the database (MySQL). It is usually performed by reading the binary logs which record all the operations and transactions performed in the database. Debezium MySQL source connector can connect to MySQL (primary or secondary) and consume the changes. These changes are then converted to Avro and stored in Kafka.
Kafka Connect: Kafka connect framework is an extension of Kafka which provides a good abstraction layer for the data that is received from the source database. With the built-in converter functionality, the source connectors convert the data received from the source database to a unified Kafka connect data schema. This makes it easier to develop the sink connector as the sink only needs to transform the Kafka connect data schema to the destination sink data type.
Kafka connect framework also provides horizontal scaling functionality in distributed mode. This increases the throughput and also provides high availability.
Apicurio Schema Registry: As mentioned before Schema evolution is a common requirement in modern data pipelines. Schema registry makes schema evolution easy by storing the different versions of the schema and it also helps with reducing the size of the payload. Source connectors store the schema of the data in the Schema registry and include the version number in the payload. In this way, the schema is not included in the payload which reduces the size of the payload and increases the throughput.
ClickHouse Sink Connector: ClickHouse sink connector was developed as a component on top of Kafka connect framework. Sink Connector reads data from Kafka and uses the ClickHouse JDBC Driver to perform operations in ClickHouse. Kafka connect framework provides high availability and parallelism features.
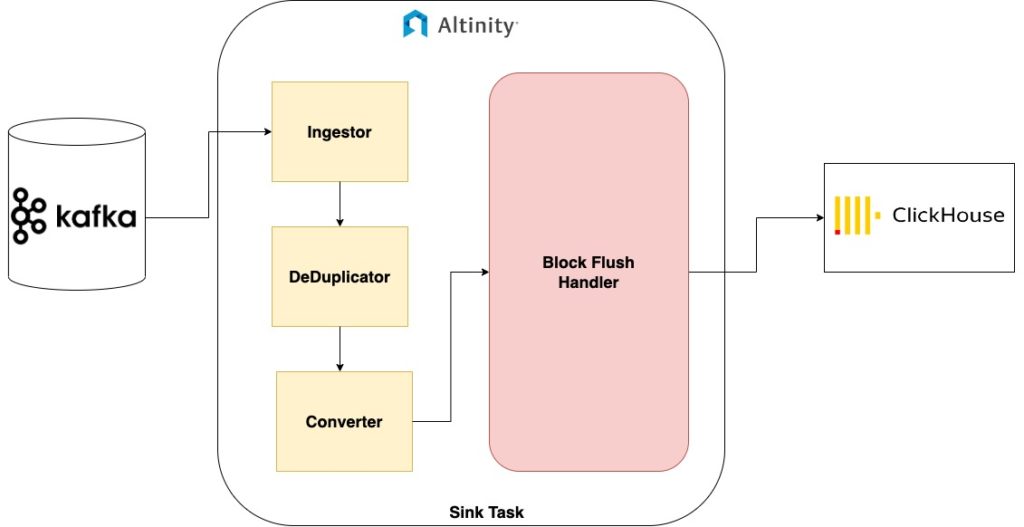
These are the high level components of the Altinity Sink Connector for ClickHouse:
Ingestor: Ingestor is responsible for ingesting messages from Kafka. In addition to the ingestion functionality, the user configuration is also parsed by this component. Here is the list of all the configuration parameters supported by the connector – Sink Configuration.
DeDuplicator: We have explained in detail the drawbacks of duplicated data in the pipeline. This component creates a session window of messages and removes duplicates in that window based on the primary key. The window duration is configurable by the user.
Converter: This component very similar to the converter functionality of Kafka connect is responsible for mapping the data types from Kafka Connect/Debezium to Clickhouse data types.
Block Flush Handler: This component creates blocks of data that is then passed on to a background thread which flushes the data to ClickHouse using the JDBC Driver. The block can be configured by either the size in bytes or time duration.
We will discuss the architecture components and the core functionality of the connector in detail in the next blog post.
Setup – Docker compose
All the components of the Altinity Sink Connector for ClickHouse can be set up locally using Docker-Compose. Below are the instructions for setting up the Docker compose environment.
The following services are included in the Docker compose file
Pre-requisites: Docker and Docker compose need to be installed.
- MySQL Primary (Bitnami Image)
- MySQL Secondary (Bitnami Image)
- RedPanda
- Apicurio Schema Registry
- Debezium
- ClickHouse
- Altinity Sink Connector for ClickHouse
- Prometheus
- Grafana
Step 1: Clone the repo with the following command.
| git clone https://github.com/Altinity/clickhouse-sink-connector.git |
Step 2: Run docker-compose to start all the docker components.
| cd deploy/docker docker-compose up |

Step 3: Add MySQL connector: If you wish to connect to a different MySQL instance, you can update the connection information in the following file before executing it.
(deploy/debezium-connector-setup-schema-registry.sh)
| MYSQL_HOST=”mysql-secondary” MYSQL_PORT=”3306″ MYSQL_USER=”root” MYSQL_PASSWORD=”root” # Comma-separated list of regular expressions that match the databases for which to capture changes MYSQL_DBS=”test” # Comma-separated list of regular expressions that match fully-qualified table identifiers of tables MYSQL_TABLES=”employees” #KAFKA_BOOTSTRAP_SERVERS=”one-node-cluster-0.one-node-cluster.redpanda.svc.cluster.local:9092″ |
After the docker components are up/running, Kafka connectors(Source and Sink) need to be created. Execute the script to add MySQL connector to Kafka connect
| cd deploy ./debezium-connector-setup-schema-registry.sh |

If you plan to connect to a different ClickHouse server, then update the connection information in the following file.
(deploy/sink-connector-setup-schema-registry.sh)
| CLICKHOUSE_HOST=”clickhouse” CLICKHOUSE_PORT=8123 CLICKHOUSE_USER=”root” CLICKHOUSE_PASSWORD=”root” CLICKHOUSE_TABLE=”employees” CLICKHOUSE_DATABASE=”test” |
Step 4: Add Altinity Sink Connector for ClickHouse by executing the following command
| ./sink-connector-setup-schema-registry.sh |

More to come!
We will go in-depth with the architecture implementation and specific use cases in future articles.
Meanwhile, the Altinity Sink Connector for ClickHouse project is open for business. You can visit the Github project and try out the examples in this article. You can even run pipelines on Kubernetes. We encourage everyone to try out the code, write up issues, and submit PRs to make improvements you would like to see.
If you have feature requests you would like us to put in or need commercial support for replication projects, please contact us at info@altinity.com, via our Contact Us page, or the AltinityDB Slack workspace. We are working closely with our existing customers on this project and would be happy to help you.
References:
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.