Connecting ClickHouse® to External Data Sources using the JDBC Bridge

Like a bridge over troubled water
I will lay me down
Paul Simon
ClickHouse is a piece of art. It is very fast and efficient. In real applications, however, ClickHouse is never used as a standalone – it integrates with other data sources and exposes query results to applications. OLAP is often built on top of an organization’s IT infrastructure that may include different database systems. Data from those systems needs to be loaded into ClickHouse one way or another in order to be used in analytical queries.
ClickHouse provides several generic mechanisms to talk to other databases: table functions, integration engines and external dictionaries. Table functions are convenient to run an ad-hoc query to an external system. Table engines allow it to represent external data as it was loaded into the ClickHouse table. External dictionaries store a snapshot of external data in RAM or cache.
All external systems are different and require different protocols to communicate. For most popular sources, like MySQL, PostgreSQL or MongoDB, ClickHouse has built-in connectors. For others it allows the use of ODBC or JDBC drivers that gives virtually unlimited possibilities to integrate. The problem, however, is the following. How can ClickHouse safely load and use third-party drivers that are not known in advance? In the case of JDBC, let’s also remember that ClickHouse is written in C++ but JDBC is Java.
When we faced this problem in Altinity.Cloud we did some brainstorming and found an excellent solution. Dmitry Titov from the Altinity support team prototyped it in two hours, and we deployed it to our client immediately. The approach is very elegant. Since it has been little discussed in community channels, we decided to fill the gap and write an article about it.
Bridge Pattern
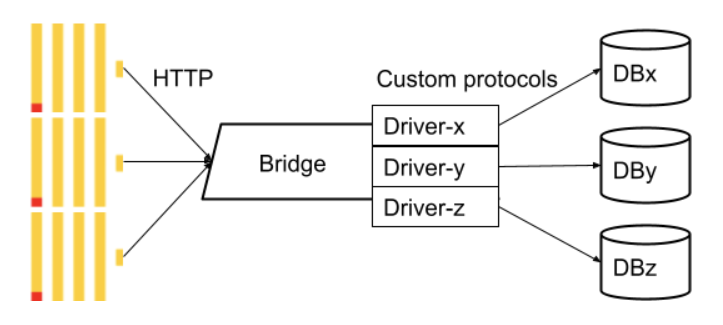
Altinity.Cloud runs in Kubernetes. Kubernetes runs apps from images. The image is supposed to have all dependencies and libraries already installed. It would be very inconvenient to extend ClickHouse images and add extra connectivity libraries in there. Also, running third-party code needs to be as isolated as possible, so a problem in the driver does not crash ClickHouse. Fortunately, ClickHouse has a solution that is called a “bridge”. The idea is very similar to a bridge pattern in software design but at a higher level.
The bridge is a separate process that handles all the connectivity to external systems and provides an endpoint for ClickHouse to connect to. You can think of it as a proxy. The main advantage is that the bridge can be modified, configured, updated and maintained independently from ClickHouse itself. It can be wrapped as an image and deployed in a separate pod or container in Kubernetes without any changes to the main ClickHouse image.
ODBC or JDBC
Both ODBC Bridge and JDBC bridge are available for ClickHouse. So the next question to decide was about the first letter: O or J? ODBC seemed closer to ClickHouse, since it is written in C/C++. Altinity made a lot of contributions to the ClickHouse ODBC driver, so we’ve got quite a lot of experience there. However, ODBC is cumbersome to set up and configure. It requires setting up a driver manager first, installing a proper driver or drivers, and configuring DSNs in special files. In Kubernetes it is even more difficult, since it would require building an image containing all popular ODBC drivers. And we have not even looked at ARM support yet.
ClickHouse JDBC bridge seemed to be easier for many reasons. It is an actively developed project with a major release in mid-2021 followed by several patch releases. There are some interesting features, like schema management, named data sources and others. There is also a well documented docker image already available. Also Java has a standard way to load external libraries, so we decided to give it a try. For those who are curious about CVE-2021-44228, the log4j dependency has been completely removed in the 2.0.7 release to be safe.
Setting up ClickHouse JDBC Bridge
Setting up the ClickHouse JDBC bridge in Kubernetes is very simple. Here is a sample bridge deployment with MSSQL JDBC driver, and a service for ClickHouse to connect:
apiVersion: apps/v1
kind: Deployment
spec:
replicas: 1
selector:
matchLabels:
app: clickhouse-jdbc-bridge
template:
metadata:
labels:
app: clickhouse-jdbc-bridge
spec:
containers:
- name: clickhouse-jdbc-bridge
image: "clickhouse/jdbc-bridge"
command: ["sh", "-c", "rm -rf /app/drivers/* ; ./docker-entrypoint.sh"]
livenessProbe:
failureThreshold: 10
httpGet:
path: /metrics
port: http
scheme: HTTP
env:
- name: JDBC_DRIVERS
value: "com/microsoft/sqlserver/mssql-jdbc/10.1.0.jre8-preview/mssql-jdbc-10.1.0.jre8-preview.jar"
ports:
- containerPort: 9019
name: http
protocol: TCP
resources:
limits:
cpu: 200m
memory: 2Gi
requests:
cpu: 200m
memory: 256Mi
apiVersion: v1
kind: Service
metadata:
name: clickhouse-jdbc-bridge
labels:
app: clickhouse-jdbc-bridge
spec:
type: ClusterIP
ports:
- port: 9019
targetPort: 9019
protocol: TCP
name: http
selector:
app: clickhouse-jdbc-bridgeNote that the driver library is specified in the JDBC_DRIVERS environment variable. Multiple drivers can be separated by a comma. JDBC bridge loads configured drivers automatically from the Maven repository, which defaults to https://repo1.maven.org/maven2 but may be overwritten to any other location with MAVEN_REPO_URL environment variable.
Kubernetes ConfigMap can be used as well if we want to keep the deployment manifest separate from the list of used drivers. The same jdbc image can be used for any driver or drivers! If the driver version is updated we only need to restart.
Another possibility is to map ‘/app/drivers’ container path to a persistent volume and manage drivers entirely outside of the JDBC bridge deployment.
Connecting ClickHouse to JDBC bridge
In order to let ClickHouse know that it needs to connect to JDBC bridge we only need to add a small configuration file:
config.d/jdbc_bridge.xml:
<clickhouse>
<jdbc_bridge>
<host>clickhouse-jdbc-bridge</host>
<port>9019</port>
</jdbc_bridge>
</clickhouse>Here, host and port should match those defined in the Kubernetes Service resource.
Once ClickHouse is configured, we can try it out. The connection can be tested with a trivial SQL statement using the jdbc table function:
SELECT * FROM
jdbc('jdbc:sqlserver://<server>:<port>;user=<user>;password=<pass>;encrypt=false', 'SELECT 1');Note: we use the actual address of the MSSQL server here, not the bridge anymore.
If we know the database and table names, we can query tables directly:
SELECT * FROM
jdbc('jdbc:sqlserver://<server>:<port>;user=<user>;password=<pass>;encrypt=false;databaseName=test_db',
'test_table')We can also create a table using JDBC engine:
CREATE TABLE jdbc_table
(
`col1` String,
`col2` String
) ENGINE = JDBC('jdbc:sqlserver://<server>:<port>;user=<user>;password=<password>;encrypt=false;databaseName=test_db;',
'', 'test_table')Finally, let’s create a dictionary, but… Apparently, JDBC dictionaries are not currently supported. Fortunately, with ClickHouse there is always a workaround.
We can use a table with JDBC engine, or create a VIEW, and use it in as a dictionary source:
CREATE VIEW jdbc_dict_source AS
SELECT * FROM jdbc('jdbc:sqlserver://<server>:<port>;user=<user>;password=<password>;encrypt=false;databaseName=test_db', 'test_table')
CREATE DICTIONARY default.jdbc_dict
(
`key` String,
`value` String
)
PRIMARY KEY key
SOURCE(CLICKHOUSE(
table 'jdbc_dict_source'
))
LIFETIME(MIN 300 MAX 300)
LAYOUT(COMPLEX_KEY_HASHED())Voila! We’ve got a dictionary connected to MSSQL server via JDBC.
Securing Database Credentials
In the examples above, user and password to MSSQL server were exposed in DDL and queries. Some DBAs would not be very happy exposing database credentials so easily. ClickHouse engineer Kseniia Sumarokova was not happy with that as well, so she added a new but not yet documented feature ‘named_collections’. Named collections allow defining a set of properties in the configuration file and use collection names instead of a connection string. This is how it could look like for a JDBC connection:
<clickhouse>
<named_collections>
<mssql_conn>
<driver>sqlserver</driver>
<host>my_host</host>
<port>my_port</port>
<user>my_user</user>
<password>my_password</password>
<database>my_db</database>
</mssql_conn>
</named_collections>
</clickhouse>With that we could query JDBC table with a much simple query:
SELECT * FROM jdbc(mssql_conn, 'test_table')Unfortunately, it does not work this way yet. Named collections are implemented only for MySQL, PostgreSQL, MongoDB, URL, S3 and Kafka connections, but not for generic JDBC. This looks like an easy feature to add in one of the future ClickHouse releases.
Is there another way to hide credentials? Of course, there is! It is possible to provide additional configuration to the bridge itself. Bridge supports named data sources that can be used instead of a full connection string. Data sources are loaded from the ‘/app/config/datasources’ folder. In Kubernetes we can store data source files in a ConfigMap, and map it directly to the folder:
apiVersion: v1
kind: ConfigMap
metadata:
name: clickhouse-jdbc-bridge-datasources
data:
mssql_con.json: |
{
"$schema": "../datasource.jschema",
"mssql_conn": {
"driverUrls": [
"https://repo1.maven.org/maven2/com/microsoft/sqlserver/mssql-jdbc/10.1.0.jre8-preview/mssql-jdbc-10.1.0.jre8-preview.jar"
],
"driverClassName": "com.microsoft.sqlserver.jdbc.SQLServerDriver",
"jdbcUrl": "jdbc:sqlserver://my_host:my_port;encrypt=false;databaseName=test_db",
"username": "my_user",
"password": "my_password"
}
}Corresponding changes need to be done to deployment as well.
...
spec:
template:
spec:
volumes:
- name: clickhouse-jdbc-bridge-datasources
configMap:
name: clickhouse-jdbc-bridge-datasources
containers:
- name: clickhouse-jdbc-bridge
...
volumeMounts:
- name: clickhouse-jdbc-bridge-datasources
mountPath: /app/config/datasourcesOnce configured, we can test that bridge picked up the datasource using a special command:
SELECT * FROM jdbc('', 'show datasources')\G
Row 1:
───────€
name: mssql_conn
is_alias: 0
instance: -651712816
create_datetime: 2021-12-28 14:37:44
type: jdbc
...And use it as follows:
SELECT * FROM jdbc('mssql_conn', 'test_table')This is secure but requires managing configuration in multiple places, which is not always convenient.
Conclusion
In this article we discussed how ClickHouse can connect to an external database, MSSQL in particular. Since ClickHouse does not have a native connector, we had to choose between ODBC and JDBC. ClickHouse can use both via a separate bridge process. JDBC was easier to set up in Kubernetes, so we followed this approach. ClickHouse JDBC bridge in Kubernetes allows plugging required drivers on demand with a simple configuration change. That extends ClickHouse connectivity options almost limitlessly. Stay tuned to learn more!
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.