ClickHouse® Continues to Crush Time Series
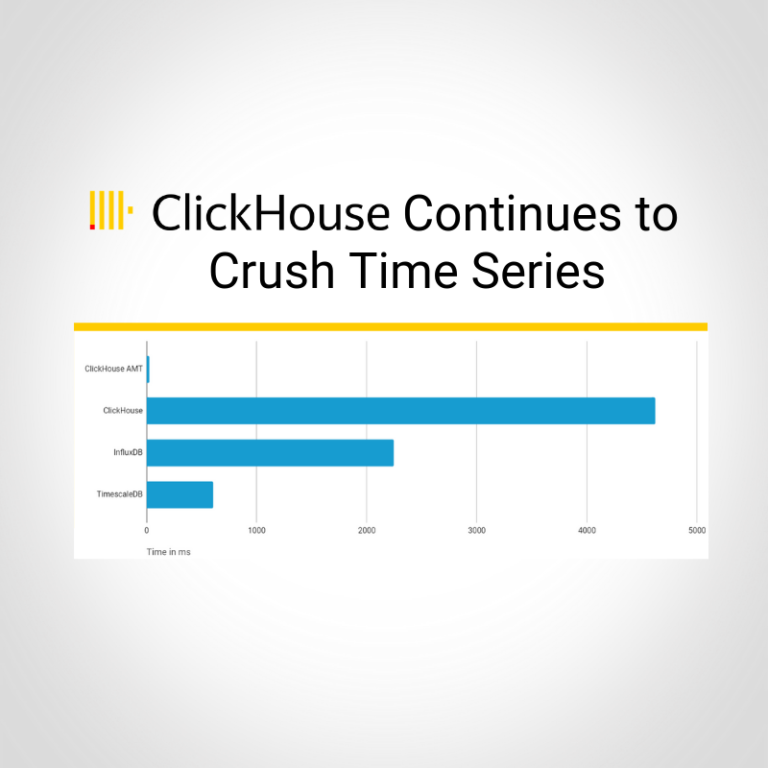
In our previous articles (ClickHouse Crushing Time Series, ClickHouse Timeseries Scalability Benchmarks) we demonstrated that ClickHouse — a general purpose analytics DB — can easily compete with specialized DBMSs for time series data: TimescaleDB and InfluxDB. There were, however, certain queries, pretty typical for time series, where ClickHouse seemed at first glance to be at a disadvantage. The most notable example is returning the latest measurement for a particular device. We will take this query and demonstrate how ClickHouse advanced features, namely materialized views and self-aggregating tables, can dramatically improve performance.
Last Point Query
When testing ClickHouse for time series we used table structures and data from the TSBS project. We generated 100M rows for 4000 devices, every row containing 10 different measurements. ClickHouse table has the following structure:
CREATE TABLE benchmark.cpu (
created_date Date DEFAULT today(),
created_at DateTime DEFAULT now(),
time String,
tags_id UInt32,
usage_user Float64,
usage_system Float64,
usage_idle Float64,
usage_nice Float64,
usage_iowait Float64,
usage_irq Float64,
usage_softirq Float64,
usage_steal Float64,
usage_guest Float64,
usage_guest_nice Float64
) ENGINE = MergeTree(created_date, (tags_id, created_at), 8192);The idea of the last point query is to return measurements for the latest point in time. In ClickHouse the query looks pretty simple and clear thanks to standard SQL syntax:
SELECT * FROM
(
SELECT *
FROM cpu
WHERE (tags_id, created_at) IN
(SELECT tags_id, max(created_at)
FROM cpu
GROUP BY tags_id)
) AS c
INNER JOIN tags AS t ON c.tags_id = t.id
ORDER BY
t.hostname ASC,
c.time DESCIt took relatively long to execute, reaching 4.6s in average.
The TimescaleDB query took only 0.6s and looked like this:
SELECT DISTINCT ON (t.hostname) *
FROM tags t
INNER JOIN LATERAL (
SELECT *
FROM cpu c
WHERE c.tags_id = t.id
ORDER BY time DESC
LIMIT 1) AS b ON true
ORDER BY t.hostname,
b.time DESCIn TimescaleDB there is correlated (lateral) join with LIMIT 1 inside — that returns the last row very quickly using the index. ClickHouse has to calculate the last record by tags_id first, which is pretty fast, but then apply index lookups on the full 100M rows dataset that takes some time.
Now let’s see how we can make ClickHouse much faster using its general purpose data warehouse capabilities…
ClickHouse AggregatingMergeTree Approach
The ClickHouse query can be rewritten in a number of ways. One option is to use argMax() aggregation function. The query may look like this:
SELECT *
FROM
(
SELECT
tags_id,
argMax(time, created_at) AS time,
argMax(usage_user, created_at) AS usage_user,
argMax(usage_system, created_at) AS usage_system,
argMax(usage_idle, created_at) AS usage_idle,
argMax(usage_nice, created_at) AS usage_nice,
argMax(usage_iowait, created_at) AS usage_iowait,
argMax(usage_irq, created_at) AS usage_irq,
argMax(usage_softirq, created_at) AS usage_softirq,
argMax(usage_steal, created_at) AS usage_steal,
argMax(usage_guest, created_at) AS usage_guest,
argMax(usage_guest_nice, created_at) AS usage_guest_nice,
max(created_at) AS max_created_at
FROM cpu
GROUP BY tags_id
) AS b
INNER JOIN tags AS t ON b.tags_id = t.id
ORDER BY
t.hostname ASC,
b.time DESCThe query does not become any faster, we see same 4.5-5s. However, since internal sub-query is a simple aggregating query with ‘group by’, we can use one of the killer features of ClickHouse — the AggregatingMergeTree (AMT) table engine. AMT allows you to aggregate data that is usually not directly aggregatable, e.g. uniques. argMax also works. Aggregation is performed automatically in the background, so once the new data arrives the table is automatically re-aggregated.
We will create a Materialized View for our ‘cpu’ table to store data in the AMT table. We keep structure similar to the source table.
CREATE MATERIALIZED VIEW cpu_last_point_mv
ENGINE = AggregatingMergeTree() PARTITION BY tuple() ORDER BY tags_id
POPULATE AS
SELECT
argMaxState(created_date, created_at) AS created_date,
maxState(created_at) AS max_created_at,
argMaxState(time, created_at) AS time,
tags_id,
argMaxState(usage_user, created_at) AS usage_user,
argMaxState(usage_system, created_at) AS usage_system,
argMaxState(usage_idle, created_at) AS usage_idle,
argMaxState(usage_nice, created_at) AS usage_nice,
argMaxState(usage_iowait, created_at) AS usage_iowait,
argMaxState(usage_irq, created_at) AS usage_irq,
argMaxState(usage_softirq, created_at) AS usage_softirq,
argMaxState(usage_steal, created_at) AS usage_steal,
argMaxState(usage_guest, created_at) AS usage_guest,
argMaxState(usage_guest_nice, created_at) AS usage_guest_nice
FROM cpu
GROUP BY tags_idThe ClickHouse Materialized View works like an insert trigger. It is fired on every insert to the source table, performs preliminary aggregation and stores the result into a internal table. Since we used AggregatingMergeTree as a engine for materialized view storage, ClickHouse will aggregate all columns that are not a part of the primary key, which is tags_id in our table. It does not store aggregation result, but the ‘state’ of aggregation instead, which can be later used in order to get the final aggregation result. If you are interested in more detail of how AggregatingMergeTree works, you can refer to this article (https://altinity.com/blog/2017/7/10/clickhouse-aggregatefunctions-and-aggregatestate).
In order to get the query result more easily, we will create a SQL View on top of the Materialized View, though it is not necessary.
CREATE VIEW cpu_last_point_v AS
SELECT
argMaxMerge(created_date) AS created_date,
maxMerge(max_created_at) AS created_at,
argMaxMerge(time) AS time,
tags_id,
argMaxMerge(usage_user) AS usage_user,
argMaxMerge(usage_system) AS usage_system,
argMaxMerge(usage_idle) AS usage_idle,
argMaxMerge(usage_nice) AS usage_nice,
argMaxMerge(usage_iowait) AS usage_iowait,
argMaxMerge(usage_irq) AS usage_irq,
argMaxMerge(usage_softirq) AS usage_softirq,
argMaxMerge(usage_steal) AS usage_steal,
argMaxMerge(usage_guest) AS usage_guest,
argMaxMerge(usage_guest_nice) AS usage_guest_nice
FROM cpu_last_point_mv
GROUP BY tags_idOnce we have a view, we can rewrite last point query as simple as:
SELECT *
FROM cpu_last_point_v AS b
INNER JOIN tags AS t ON b.tags_id = t.id
ORDER BY
t.hostname ASC,
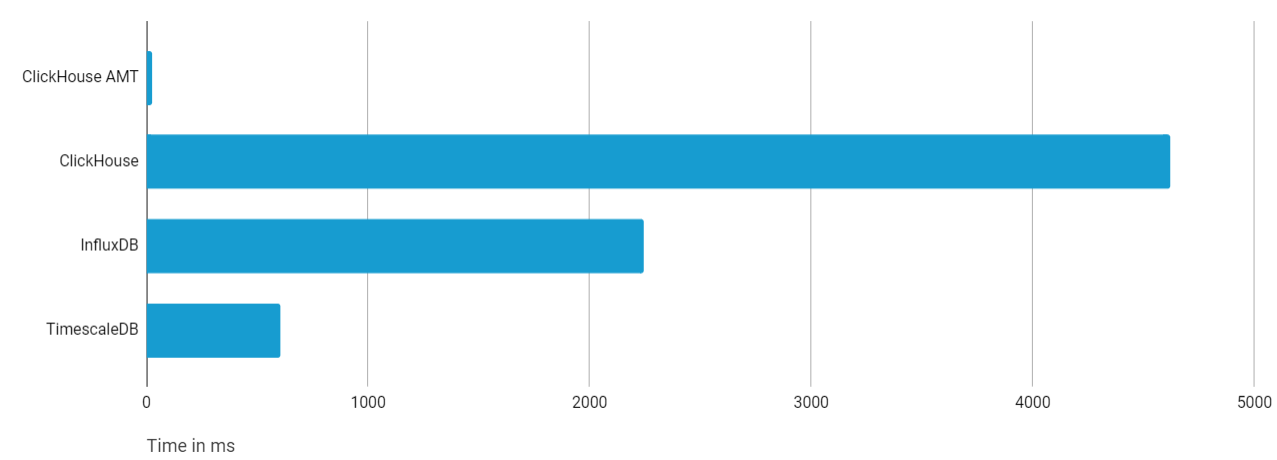
b.time DESCAnd it only takes 0.02s to complete! The new result is barely visible on the comparison chart if you wish to compare it with TimescaleDB and InfluxDB now:
Conclusion
ClickHouse is a general purpose DBMS for analytics, and it is not as heavily optimized for time series as specialized time series DBMS like TimescaleDB and InfluxDB are. Even so it performs very well against them, as we demonstrated in our previous article on this topic (https://altinity.com/blog/clickhouse-for-time-series).
TimescaleDB and InfluxDB may be faster out-of-box on certain types of queries thanks to more efficient index structure, and built-in time series specific optimizations. That said, ClickHouse is a general purpose data warehouse with special data structures that can pre-aggregate data in real-time, and this can be used to optimize common time series queries. Using ClickHouse AggregatingMergeTree technique we decreased response time of the last point query from 4.5s to 20ms — this is more than a 200x improvement! Such a design adds some extra complexity to the schema, but it pays out with orders of magnitude faster performance in comparison to other alternatives. ClickHouse is fun!
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.
Please, I tried your queries on my data and it was not working in way you are describing. Is the following statement correct?
“The ClickHouse Materialized View works like an insert trigger. It is fired on every insert to the source table, performs preliminary aggregation and stores the result into a internal table.”
As far I I know MV with the engine AggregatingMergeTree is not working like insert trigger but it merges the data just during the merge operation that is happening sometimes or possibly at all. It means in the MV you could still have multiple rows with the same tags_id.
In the VIEW you use second aggregation that filters out duplicates from MV. But is the time 0.02s for all runs of queries from this VIEW? In my experience when the data in MV are changed the query from VIEW can take much more time. Thanks for clarifications.