ClickHouse® as the Looking Glass for OLTP Data

“Look in thy glass and tell the face thou viewest”
–William Shakespeare
Quite often users come to Altinity.Cloud with what seems like legacy baggage from non-analytical databases like MySQL or PostgreSQL. In many cases, users are not trying to replace these databases. They just want to make their existing databases better by adding fast analytics.
In such cases, users want to migrate data to ClickHouse and keep it in sync with the database, just like a mirror. There are many different approaches to this problem, including the Altinity Sink Connector for ClickHouse, which we recently described in our “Using ClickHouse as an Analytics Extension to MySQL” article. But every situation is different.
In this article, we’ll discuss a “pure ClickHouse” approach, which highlights some interesting ClickHouse features but at the same time shows problems that require external tools to solve effectively.
Configuring the Connection to an External DB
Let’s consider the source database is PostgreSQL, but it can be anything else. ClickHouse talks natively to PostgreSQL, MySQL and MongoDB, for other databases a JDBC bridge is needed. The basic approach is the same.
The very first step is to configure ClickHouse to see the data in another DB. This will be used for initial load as well as consistency checks. ClickHouse allows the creation of “’external” databases using dedicated database engines. For PostgreSQL, it can be done as follows:
CREATE DATABASE my_data_pg Engine = PostgreSQL(<server>, <user>, ... )Since exposing credentials in the schema is not very secure, ClickHouse also allows storing credentials in a config file that can not be directly accessed from SQL. This feature is called named collections. Let’s create a configuration file my_postgresql.xml and place it into the ClickHouse server ‘config.d’ folder. In Altinity.Cloud it can be done via cluster settings.
<clickhouse>
<named_collections>
<my_postgresql>
<user>my_user</user>
<password>some_password</password>
<host>some host</host>
<port>5432</port>
<database>my_data</database>
<schema>public</schema>
<connection_pool_size>8</connection_pool_size>
</my_postgresql>
</named_collections>
</clickhouse>Once we have this file deployed to the server, we can create a PostgreSQL database that refers to an external source as follows:
CREATE DATABASE my_data_pg Engine = PostgreSQL("my_postgresql")Using this database connection, we can now check the schema and tables with SHOW TABLES, DESCRIBE and other standard DDL statements. We can even run queries, but those are going to be slow since the data needs to be fetched from PostgreSQL for every query.
Loading Tables from an External Database
Now let’s create a copy of the PostgreSQL database in ClickHouse. This requires some work. The basic algorithm is the following.
- Check the table on the PostgreSQL side, and decide if any partitioning or
ORDER BYis needed. Number of rows in the table and prior knowledge about typical queries would help here. - Create a table in ClickHouse using ‘
CREATE AS SELECT‘ statement, specifying engine parameters if needed. If you run a cluster with multiple replicas, you’ll have to create a tableON CLUSTERfirst and then runINSERT SELECTto populate the data. - If create fails due to timeout on the source side (e.g., too much data), then truncate the table and iterate by smaller portions.
Here is a sample SQL query that creates a table in ClickHouse using column definitions from PostgreSQL and populates it with data:
CREATE TABLE my_data.clients
Engine = ReplacingMergeTree
ORDER BY id
AS SELECT * FROM my_data_pg.clientsWe use ReplacingMergeTree, which allows us to handle row updates by re-inserting changed rows. We do not need to specify column names and datatypes, since ClickHouse can infer it from the source table.
If we need to alter ClickHouse table definition, we can do it in the same statement. For example, transactions table is probably a big one, so it can benefit from custom partitioning and different ORDER BY:
CREATE TABLE my_data.transactions
Engine = ReplacingMergeTree
PARTITION BY toYYYYMM(transaction_date)
ORDER BY (client_id, transaction_date, id)
SETTINGS allow_nullable_key=1
AS SELECT * FROM my_data_pg.transactionsNote ‘allow_nullable_key’ setting. Usually, all columns except the primary key in PostgreSQL and MySQL are nullable. Here we added ‘client_id’ and ‘transaction_date’ to the ClickHouse primary key, and need to allow nullable keys explicitly with the setting. Otherwise, table creation will fail.
After repeating this process for every table we get an (inconsistent) data snapshot in ClickHouse that can be immediately used for testing! Many users who tried this approach were blown away with ClickHouse performance compared to the source database!
Snapshots are great, but data often changes and ClickHouse snapshots age over time. How to reflect changes on the ClickHouse side? The easiest solution is to perform a snapshot regularly, for example once per day. However, it may not work if data should be available in ClickHouse with a little delay. Another problem is the data size – big tables do not allow to do a full snapshot too often. Let’s consider some other approaches.
Updatable External Dictionaries
We discussed ClickHouse external dictionaries in our blog before (see [1], [2] and [3]). Dictionaries can be used in order to sync data automatically with external databases as well.
CREATE OR REPLACE DICTIONARY my_data.client_dict (
`id` UInt64,
`name` Nullable(String),
`zip` Nullable(String),
`address1` Nullable(String),
`address2` Nullable(String),
`city` Nullable(String),
`state` Nullable(String),
modified DateTime
)
PRIMARY KEY id
SOURCE(POSTGRESQL(
NAME "my_postregsql"
TABLE 'client'
invalidate_query 'SELECT max(modified) from client'
update_field 'modified'
update_lag 15
))
LAYOUT(FLAT())
LIFETIME (MIN 300 MAX 360)Here we used the same named collection in order to connect directly to the source PostgreSQL database. Once created, the dictionary will query PostgreSQL and have the same content as my_data.client table. Moreover, it will refresh automatically and will be in sync with the source table! This is configured by several settings of dictionary definition:
LIFETIME (MIN 300 MAX 360)— this is an instruction to refresh dictionary every 5 to 6 minutesinvalidate_query 'SELECT max(modified) from client'— this is the query that ClickHouse will use in order to check if there are any changes in the table. It remembers the previous result of the query and compares it with the current one. If there are no changes, data will not be refreshed."update_field 'modified'" and "update_lag 15"— it turns on partial updates. ClickHouse will fetch only records with ‘modified’ after the previous fetch, and additionally add 15 seconds of overlap just in case.
As a result, “client_dict” will be automatically refreshed from the source table with a minimum overhead. It can be used in queries exactly as a table!
There are a few drawbacks with dictionaries though:
- The full table is stored in RAM. This is good for query performance but may not work well for big tables.
- When ClickHouse server restarts, dictionaries need to be loaded all at once, which takes time and generates high load on the source DBMS.
The empirical rule is that dictionaries work well for tables with less than 10 million rows (given that they fit in RAM). Usually those are so-called dimension tables. Bigger tables that constantly grow over time require a different approach.
Incremental Updates of Big Tables
Updatable dictionaries above give us a hint how to implement updates to bigger tables as well. Let’s consider that the ‘transactions’ table is a big one, all we need to do is to run periodically a query like the following:
INSERT INTO my_data.transactions
SELECT * FROM my_data_pg.transactions
WHERE modified >= (SELECT max(modified) FROM my_data.transactions)-30Here, we take the last modified timestamp from a destination table and query rows that have been modified since then in the source table. We can set up a simple cron script that would do it, but that would require an external service. It would be great if ClickHouse could run some jobs periodically. But wait – we have just configured periodic dictionary updates in the previous chapter! Can we use dictionaries in order to fire external jobs? In fact we can, and we will show how it can be done now.
At first, we could try using URL dictionaries for this purpose. Look how elegant it is:
CREATE OR REPLACE DICTIONARY my_data.transactions_update (
id Int8
)
PRIMARY KEY id
SOURCE(HTTP(
URL 'http://localhost:8123?query=INSERT INTO my_data.transactions SELECT * FROM my_data_pg.transactions WHERE modified >= (SELECT max(modified) FROM my_data.transactions)-30'
))
LAYOUT(FLAT(1))
LIFETIME (MIN 300 MAX 360)The idea is that we run INSERT SELECT using ClickHouse HTTP interface, and make a call to ClickHouse using ClickHouse itself! Since it is all running inside a host it is secure.
The main problem with this approach is that it does not work. URL dictionary performs a GET call, and ClickHouse does not allow data modifications for GET calls. Documentation suggests using CACHE dictionary for POST queries, but CACHE dictionaries have a totally different meaning of LIFETIME — it is cache expiration time. So it can not be used for making a call on a schedule.
The other approach that provides ultimate flexibility is Executable Dictionaries. Executable Dictionaries allow us to run external scripts from ClickHouse. So let’s write a simple shell script first.
incremental_update_table.sh
---------------------------
#!/bin/bash
# Parameters:
# * CLICKHOUSE_TABLE
# * SOURCE_TABLE
# * UPDATE_FIELD
# * UPDATE_LAG
#
# Output: id, rows
echo 0, `clickhouse-client --query="SELECT count() FROM $CLICKHOUSE_TABLE"`
clickhouse-client --query="INSERT INTO $CLICKHOUSE_TABLE SELECT * FROM $SOURCE_TABLE WHERE $UPDATE_FIELD>=(SELECT max($UPDATE_FIELD) FROM $CLICKHOUSE_TABLE) - $UPDATE_LAG"
echo 1, `clickhouse-client --query="SELECT count() FROM $CLICKHOUSE_TABLE"`This script performs incremental INSERT SELECT using table names as a parameter and returns row counts before and after the call as a result. This is not necessary, but convenient in order to track the progress.
In order to use the script in Executable Dictionary we need to put script file under a special path on a filesystem:
/var/lib/clickhouse/user_files/incremental_update_table.shThis is easy to do on-prem. In Altinity.Cloud users need to ask Support to do it, since it is a potentially unsafe operation that needs to be reviewed by a human being.
Once the file is in place on a server, we can create an Executable Dictionary:
CREATE OR REPLACE DICTIONARY ag_db_dev.transactions_update_dict
id Int8,
rows Int32
)
PRIMARY KEY id
SOURCE(EXECUTABLE(
COMMAND 'CLICKHOUSE_TABLE=my_data.transactions SOURCE_TABLE=my_data_pg.transactions UPDATE_FIELD=modified UPDATE_LAG=30 /var/lib/clickhouse/user_files/incremental_update_table.sh'
FORMAT 'CSV'
))
LAYOUT(FLAT())
LIFETIME (MIN 300 MAX 360)Well, another bump on the road! ClickHouse throws an exception:
Code: 482. DB::Exception: Dictionaries with executable dictionary source are not allowed to be created from DDL query. (DICTIONARY_ACCESS_DENIED) (version 22.8.10.29 (official build))Creating executable dictionaries with DDL is considered to be insecure. Goodbye handy DDL, welcome back XML for dictionary definition. Fortunately, it is not a problem in Altinity.Cloud. In order to define an XML dictionary we need to add two server level settings. You can add these in the CONFIGURE->SETTINGS dialog on the cluster dashboard page.
dictionaries_config: /etc/clickhouse-server/config.d/*_dictionary.xml— it allows ClickHouse to read dictionary definitions from the server config folder directlyconfig.d/my_data.transactions_update_dictionary.xml:
<clickhouse>
<dictionary>
<name>transactions_update</name>
<source>
<executable>
<command>CLICKHOUSE_TABLE=my_data.transactions SOURCE_TABLE=my_data_pg.transactions UPDATE_FIELD=modified UPDATE_LAG=30 /var/lib/clickhouse/user_files/incremental_update_table.sh</command>
<command_read_timeout>300000</command_read_timeout>
<format>CSV</format>
</executable>
</source>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
<layout>
<flat />
</layout>
<structure>
<id>
<name>id</name>
</id>
<attribute>
<name>rows</name>
<type>Int32</type>
<null_value>0</null_value>
</attribute>
</structure>
</clickhouse>Also, it makes sense to disable dictionary lazy loading, which is possible with just one more server setting:
-
dictionaries_lazy_load: false
Once this dictionary is defined, the “transactions” table will be updated every 5 minutes or so keeping ClickHouse in sync with PostgreSQL. The mirror is there, though it may reflect the source with some delay.
We added a 30-second lag in order to make sure updates are never missed. That may result in some data loaded multiple times if there are no changes. Fortunately, ClickHouse will de-duplicate identical data blocks for Replicated tables automatically. For non-replicated tables the non_replicated_deduplication_window merge tree setting needs to be turned on.
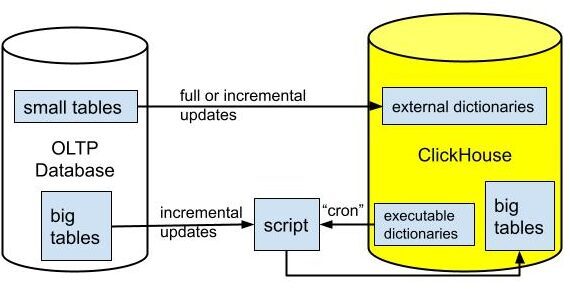
Operating Updatable Tables at Scale
The approach described above works quite well, but it requires a lot of manual work to set it up and maintain in a proper state. For example, every table requires a separate updatable or executable dictionary. This can be improved. We could define a list of source and destination tables in a separate ClickHouse table and adjust a script to refer to this table instead. That would eliminate the need for a separate executable dictionary for every table.
Another big problem is handling schema changes. if a new table arrives, the user needs to explicitly add it. If a new column is added to the table on the source side it will break the incremental update, because ‘INSERT .. SELECT‘ will start failing. So users will have to apply changes manually on both sides.
Ensuring that the data is fully consistent between source and destination is probably the most important challenge. So for updatable tables consistency monitoring is required, as well as some operations to load tables partially or fully.
Also note, that dictionaries are updated on their own schedule, so there is no guarantee that the ClickHouse snapshot is fully consistent. SYSTEM RELOAD DICTIONARIES can be used in order to force refresh, but it still can not guarantee transactional consistency.
Careful readers have probably noticed several assumptions that we made here:
- We required every table to have a “modified” column that reflects the update stamp, and every table to have an “Id” column. This is usually the case but not always.
- We used ReplacingMergeTree in order to handle row level changes in ClickHouse. It requires careful handling and use of ‘
FINAL‘ modified in the queries if you expect updates. To make it simpler, we have submitted a PR to ClickHouse that allows it to applyFINALautomatically. - We assume that data is never deleted in the tables that are updated using the script. Otherwise, the special handling to remove deleted rows is required.
Limitations described above may or may not be blocking for particular use cases, but those are definitely quite annoying. This is one of the reasons why we developed the Altinity Sink Connector for ClickHouse. It streams data, handles updates, and deletes automatically. Schema changes will soon be supported. It also provides monitoring and consistency checks. So far it only supports MySQL as a source, but it can be easily extended to other databases. (We’ve run prototypes with PostgreSQL already.) We have deployed the Sync Connector into Altinity.Cloud for some users and are working on a seamless integration next year.
Final Remarks
In this article, we showed how ClickHouse-rich functionality can be used in order to set up mirroring of external databases with ClickHouse. External dictionaries provide tooling to fetch the data from other DBMS efficiently, but do not work for big tables. Big tables require an incremental population to be run periodically. Here Executable Dictionaries come to the rescue.
Executable Dictionaries are a very powerful feature that gives absolute flexibility to ClickHouse users. We used it in order to run an external script that executes SQL query, but it can be applied to other scenarios where a ‘cron job’ is needed. For example, we might use it in order to load data periodically from an S3 bucket. Unfortunately, due to security concerns, Executable Dictionaries are often not available for ClickHouse users. Altinity.Cloud has no limits, and users can use all functionalities of our favorite analytical DBMS.
ClickHouse’s main power is the DBMS itself. Therefore despite its ultimate flexibility dedicated products may do certain things better. The Altinity Sink Connector for ClickHouse extends ClickHouse with consistent transaction mirroring from MySQL and PostgreSQL (soon). Stay tuned to see when this feature reaches GA in Altinity.Cloud!
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.