1 Trillion Rows in ClickHouse®, Part 1: Altinity.Cloud® Setup

A couple of months ago Data+AI Summit 2022 accepted one of my talk proposals. It describes how to give end users direct access to 1 trillion row datasets. There was just one problem: I didn’t have a dataset that large and needed to create one fast to vet samples for the presentation. Fortunately I had access to Altinity.Cloud.
This article covers Altinity.Cloud features you can use to set up large datasets quickly and at minimal cost. They include multi-volume storage, fast server rescaling, and scheduled operation. The article illustrates each in succession.
Enormous datasets are hardly unusual among ClickHouse users, and we have a lot of experience to share. Future articles in this series will cover schema design, loading, and query on trillion row datasets. We’ll share some of the special innovations that ClickHouse offers as well as the tricks to use them effectively to get cost-efficient, sub-second response for users.
Altinity.Cloud architecture overview
Before diving into features, let’s make a quick digression to discuss how Altinity.Cloud architecture delivers cost-effective scaling and high performance. Altinity.Cloud uses block storage provided by the cloud vendor, attaching one or more volumes using the ClickHouse JBOD (just a bunch of disks) volume configuration.
Here’s a picture to illustrate operation on AWS using EBS (Elastic Block Storage).
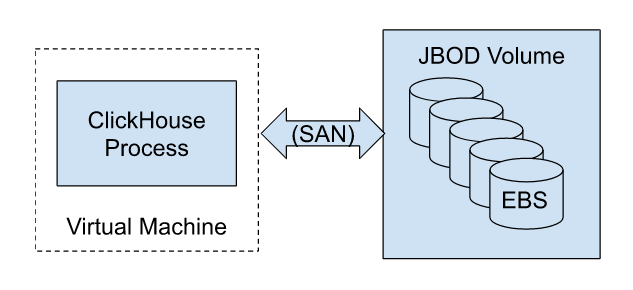
This architecture has three important properties.
- VM and storage resources are fixed. This means that your costs are bounded–you will never be charged for more than the allocated resources. Moreover, you can bend costs downward easily by allocating smaller VMs and less storage space.
- We can adapt to different scaling models across clouds. In AWS I/O bandwidth scales with the number of volumes, whereas GCP scales linearly with volume size. Altinity tests show that AWS EBS GP2 with multiple volumes achieve performance equivalent to local SSD storage.
- Block storage provides an effective model for data warehouse elasticity. Since the volumes are remote rather than local, we can rescale compute by trading the current VM for a new one attached to the same storage. This operation can occur in as few as a couple of minutes depending on available cloud provider resources. You can trade off between compute cost and capacity at any time.
All three properties make Altinity.Cloud ideal for quick, cost-effective exploration and testing on large datasets. Quick learning in turn is crucial to get applications to market quickly with economical operation after deployment.
Getting started
Let’s commence by logging into the Altinity.Cloud management plane at https://acm.altinity.cloud/login. If you don’t have an Altinity.Cloud account, you can get one here.
Find your way to the Clusters panel. If you don’t have any clusters running it will look like the following picture.
Create a ClickHouse server with adequate capacity
Let’s start by creating a cluster with adequate capacity for our trillion row dataset. For initial development efforts I recommend keeping things simple and using a single server. In ClickHouse terms that means one shard with a single replica. The single server is faster and cheaper. Also, a trillion rows can fit on a single server in many cases!
The first step is to start the LAUNCH CLUSTER wizard and fill in initial values.
Here’s our first developer tip. Normally I would use the ClickHouse 22.3 LTS but there are a couple of performance bugs that affect loading and querying large datasets (including this and this; fixes are expected soon). For now it’s best to stick with 21.8.15 Altinity Stable. Here’s the filled out screen.
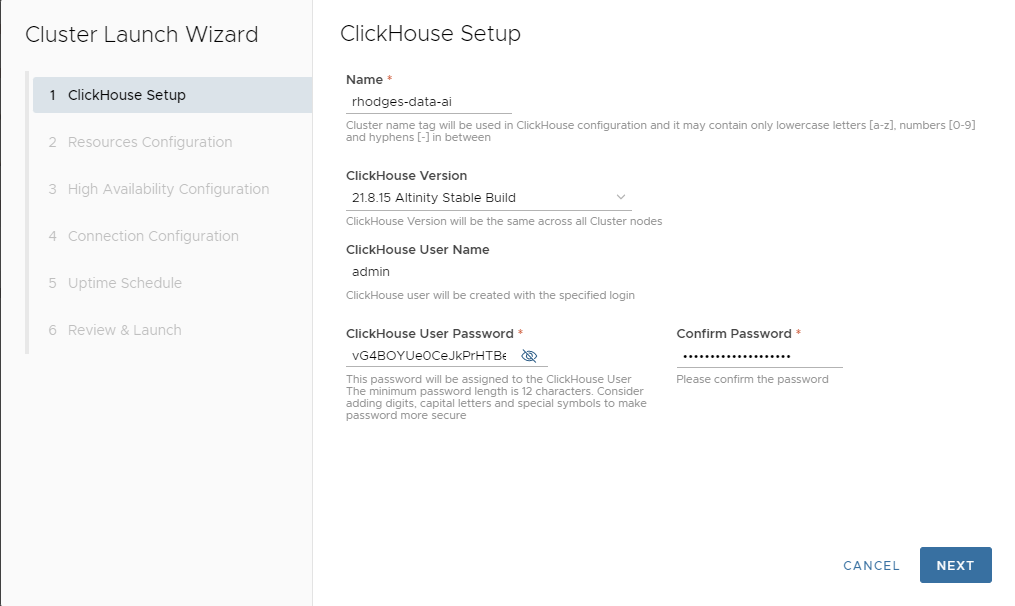
Press NEXT to proceed to the next screen.
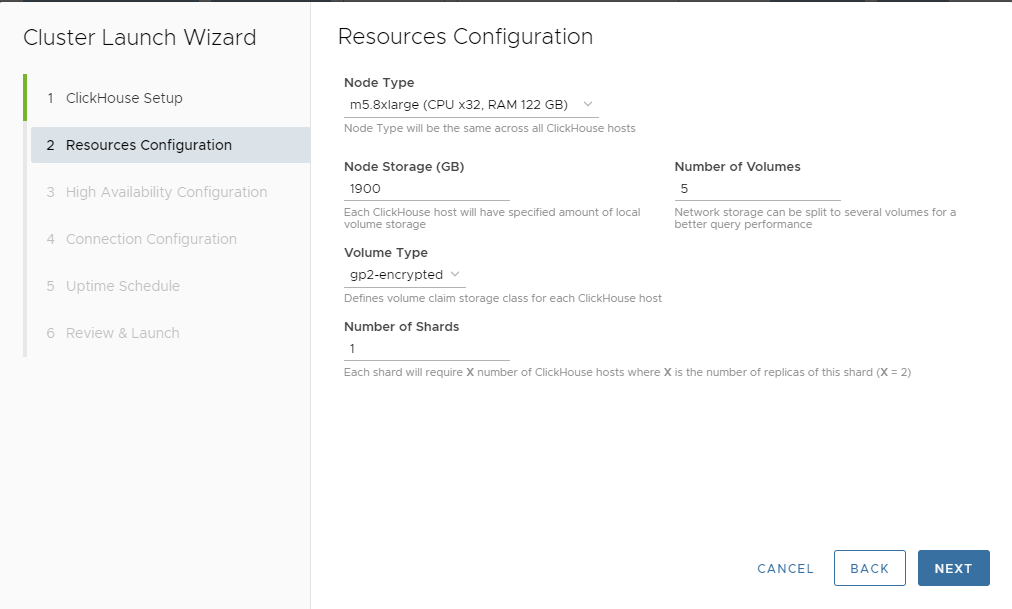
Here, we’ll allocate resources. To work with a trillion row dataset, we need a large server instance, such as an AWS m5.8xlarge VM. Altinity.Cloud can be configured to allow larger instances, but this size is plenty for our purposes.
You’ll notice that as you pick the instance size, Altinity.Cloud automatically adjusts the default storage size and number of volumes. The goal is to maximize I/O and keep an optimal ratio between RAM and storage size. You can adjust these to other values but for now we will go with the recommended default of 1.9 TB striped over 5 volumes. This will give us a read speed of 5 x 250 = 1250 MB/s on a large instance.
If you need more storage later you can always scale up the size of allocated storage. However, you cannot take storage away, once it is allocated.
We’ll also go with the default GP2 encrypted volumes and a single shard. This completes our resource allocations.
Press NEXT and proceed to the High Availability Configuration. This page is quick because we only want a single replica for now. Here is the configuration.
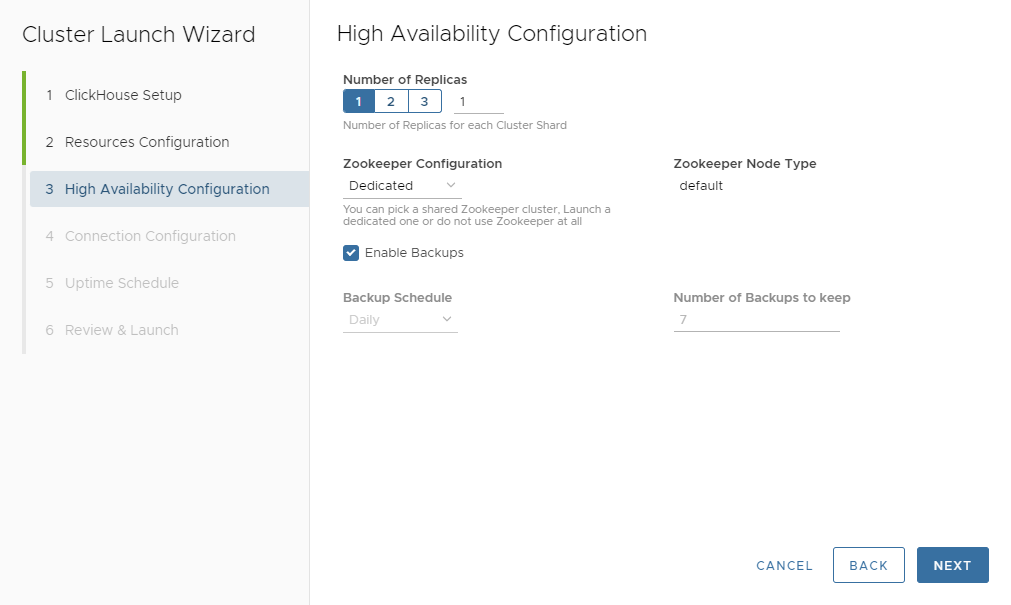
We’ll press NEXT to show the Connection Configuration, which we’ll leave untouched and hence do not show here. Pressing NEXT again brings us to the Uptime Schedule page. This is more interesting for large dataset development and one of my favorite Altinity.Cloud features.
As everyone who uses public clouds knows, it’s easy to run up an enormous bill by leaving idle instances running. Altinity.Cloud fixes this problem using uptime schedules, which automatically control when the data warehouse runs. There are three choices.
- ALWAYS ON – Never turn ClickHouse off. This would be standard for most production systems and is the default.
- STOP WHEN INACTIVE – You set a maximum number of hours, after which the Altinity pauses the cluster.
- ON SCHEDULE – You set the days of the week and times when the cluster should run. Altinity.Cloud automatically pauses it outside these times.
The STOP WHEN INACTIVE setting is the most useful for development. We’ll set a 2 hour timeout as shown below.
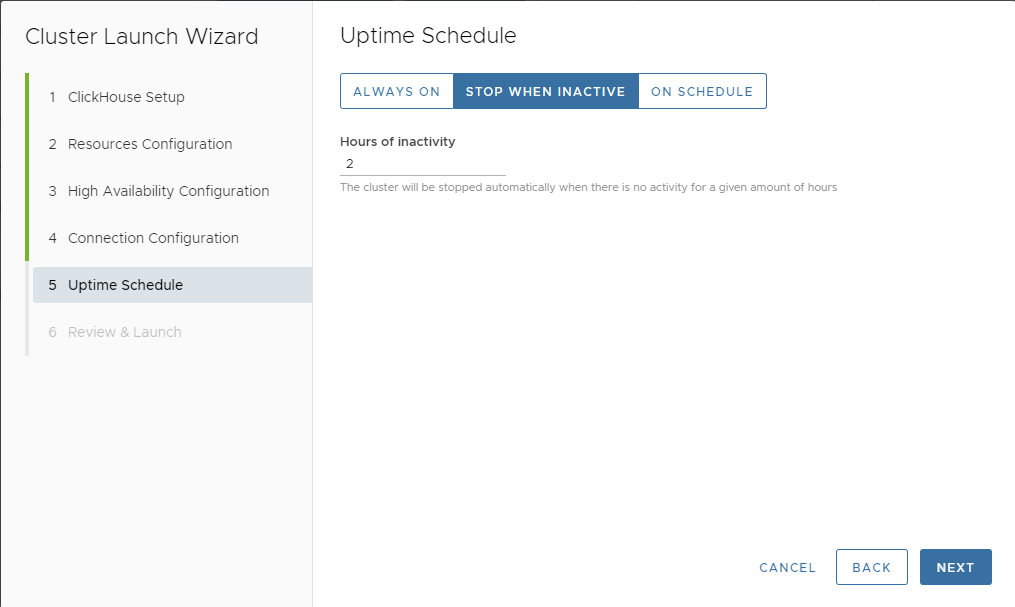
Press NEXT, where we can review our work. The screen looks like the following.
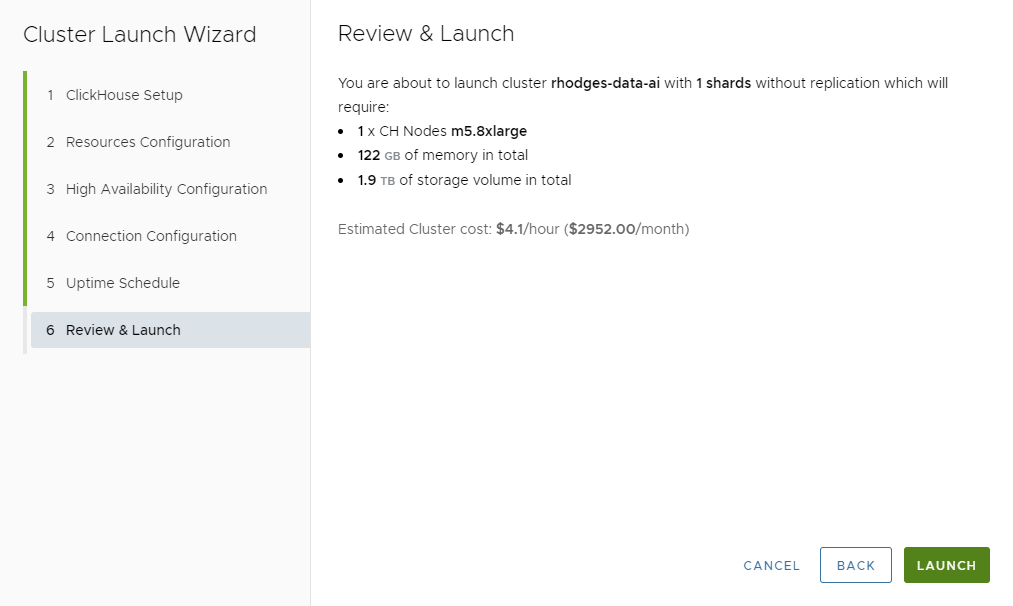
Note that this cluster will run almost $3000 per month or $4.10 per hour. That’s pricey for development. We’ll fix that shortly. In the meantime, let’s press LAUNCH and create the new cluster. After a few minutes you’ll see a dashboard in Altinity.Cloud like the following.
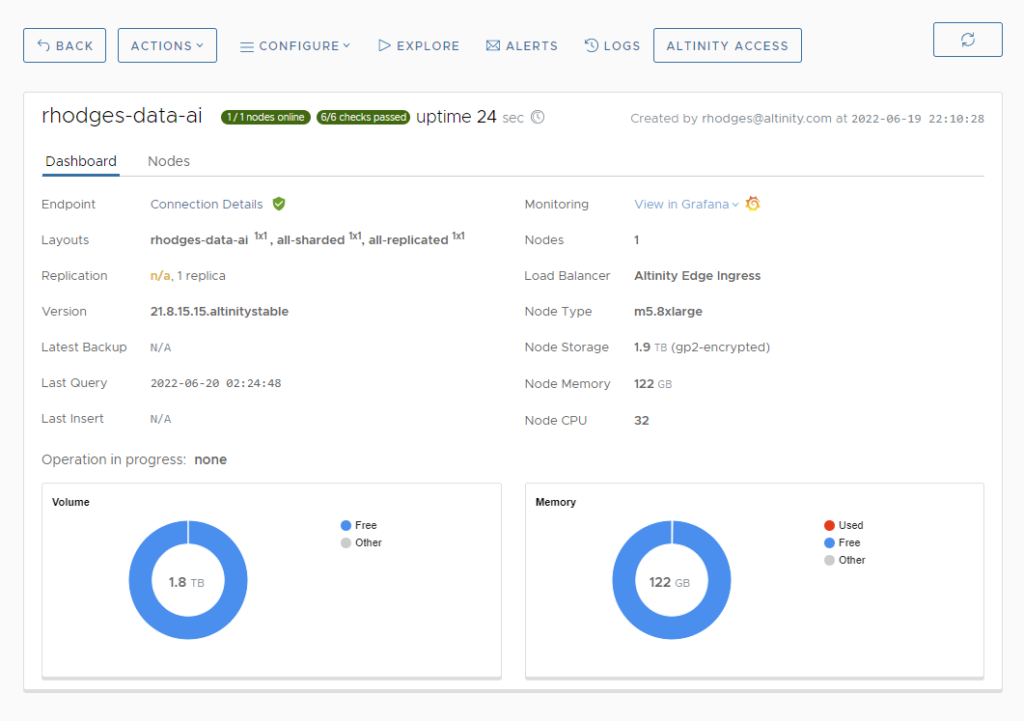
When you see the green buttons that show 1/1 nodes online and 6/6 checks passed, your cluster is ready.
Rescaling to switch between dev and prod configurations
We noted previously that at circa $4 per hour our cluster will rack up an on-demand bill of close to $3,000 per month. This is wholly unnecessary for development or even some production situations. Once the cluster is up, we can immediately rescale to a much more economical 2 vCPU configuration.
Select the ACTIONS->Rescale menu in the cluster dashboard. A Rescale Cluster dialog will pop up. In the Desired Node Size section, set the Node Type to m5.large.
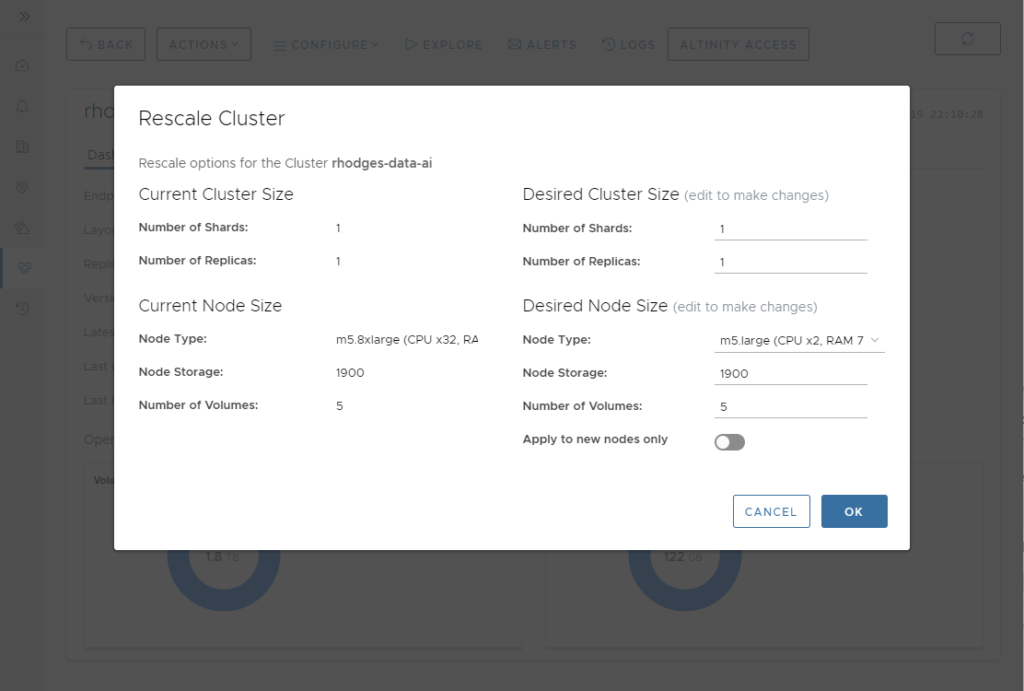
Press OK followed by CONFIRM in the Rescale Confirmation popup. Altinity.Cloud will restart your ClickHouse server to bring it up again with a smaller VM. The entire operation completes in a few minutes. You’ll now see a new dashboard that shows the m5.large type as the Node Type.
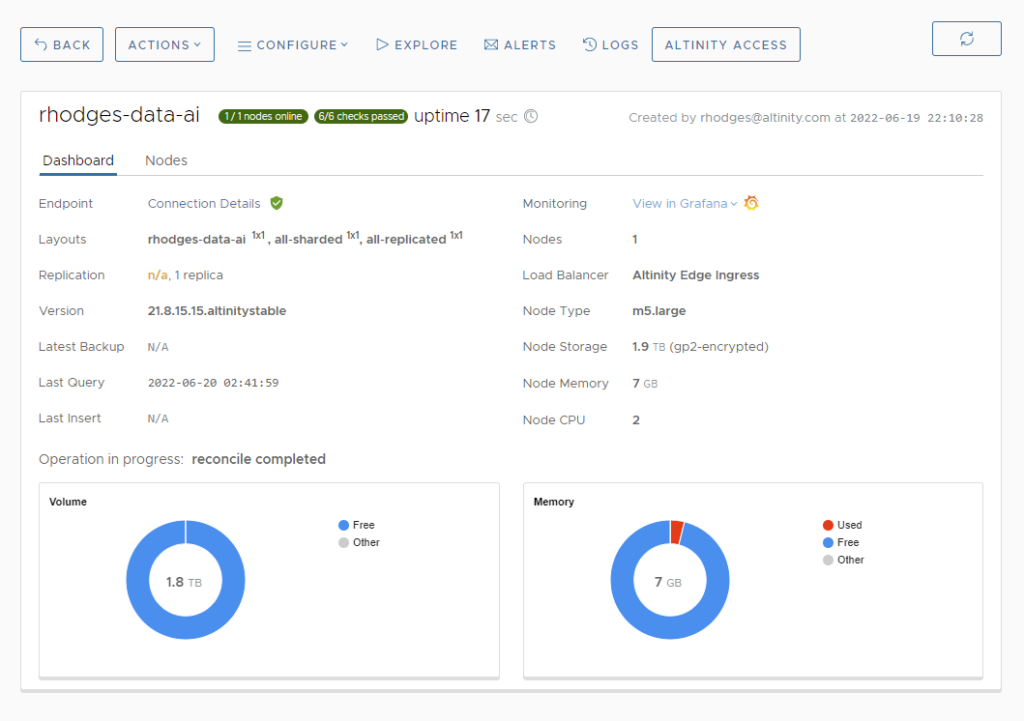
Two vCPUs is plenty for development. Let’s now create a test account that we can use for that purpose. Select CONFIGURE->Users from the cluster dashboard and press ADD USER. Fill out the User Details popup with details like those in the following example.
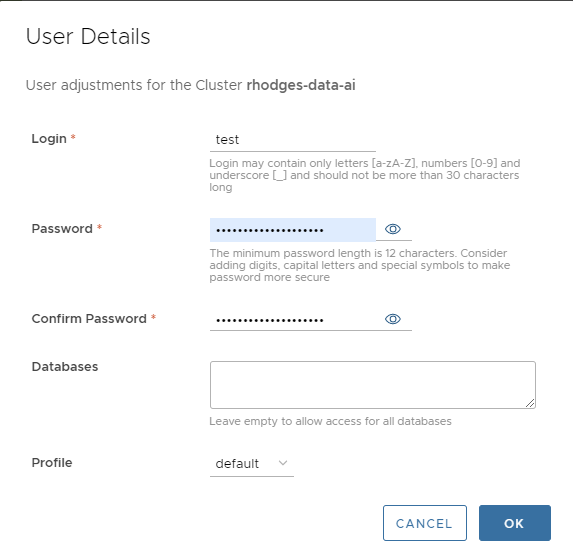
ClickHouse users take a minute or two to show up. As soon as the user is available, we can now test the connection using any ClickHouse client. Here’s an example using clickhouse-client.
$ clickhouse-client --host=rhodges-data-ai.tenant-a.staging.altinity.cloud --user=test --password --secure
ClickHouse client version 22.5.1.2079 (official build).
Password for user (test):
Connecting to rhodges-data-ai.tenant-a.staging.altinity.cloud:9440 as user test.
Connected to ClickHouse server version 21.8.15 revision 54449.
rhodges-data-ai :) select version();
┌─version()─────────────────┐
│ 21.8.15.15.altinitystable │
└───────────────────────────┘
OK! We’re ready for development. This is sufficient to design schema, develop queries, and check basic behavior. The cost of compute is 16x less than using the original 32 vCPU m5.8xlarge VM.
One final note: We can rescale our server to 32 vCPUs any time it is convenient simply by selecting ACTIONS->Rescale from the cluster dashboard. In fact you can choose any available node size. When you want to load real data or run queries at full power just rescale to your production node size. This allows you to test scaling and also try out different node sizes on real data. This enables you to zero in on a node size that has adequate performance without incurring unnecessary costs.
Stopping and resuming ClickHouse in Altinity.Cloud
You can stop ClickHouse clusters any time you wish using the ACTIONS->Stop operation. Just select this item from the cluster dashboard. You’ll see a popup like the following.
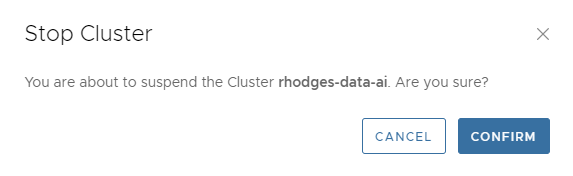
Stopping a cluster frees up all compute resources but leaves the storage idle. You do not pay for compute or support on a stopped cluster, just the idle storage. You can resume the cluster at any time by selecting ACTIONS->Resume. You’ll see a dialog like the following.
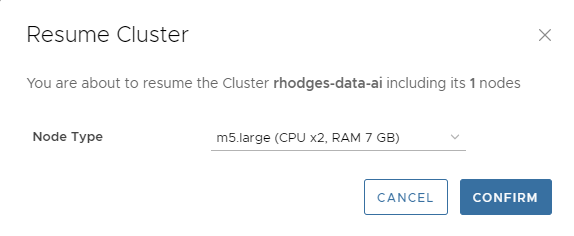
Note that you can rescale the Node Type on resume. This is handy if you want to resume a paused cluster at a different size, for example going straight to 32 vCPUs again for data loading or query testing at scale.
Finally, we mentioned uptime schedules earlier. These allow you to control when your cluster runs and shut it off automatically after a period of inactivity. You can change the uptime schedule at any time by selecting CONFIGURE->Uptime Schedule. The following dialog will appear for our cluster.
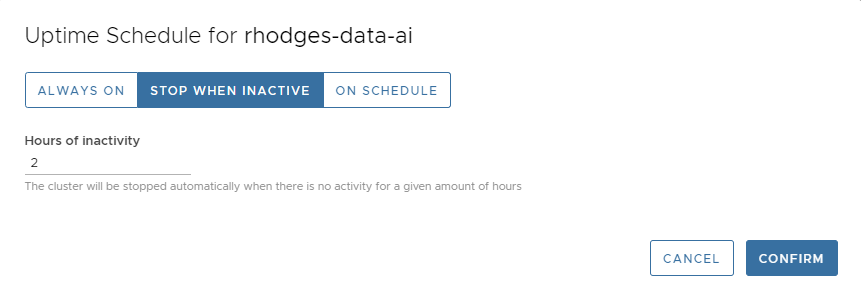
I find that 2 hours is a good period for development work, especially with 2 vCPUs. You will not incur much of a bill if you go to lunch and forget to turn it off. At the same time it’s long enough that the cluster won’t time out if you become temporarily engrossed in other activities and forget to send queries to the cluster.
Conclusion and more to come
This article has shown some of the Altinity.Cloud features that we lean on at Altinity for efficient development and operation of very large ClickHouse datasets. Multi-volume storage increases performance on block storage. Rescaling allows you to minimize compute during development but spin up to any node size required for data loading and query load testing. Finally, stop and resume operations as well as uptime schedules allow you to shut off compute completely when it is not needed.
In future articles in this series we’ll dig deeper into developing, loading, and querying trillion row datasets in ClickHouse. Stay tuned! There’s more to come shortly.
If you are inspired to try out Altinity.Cloud from this article, you can sign up for a free trial with a few clicks. Our customers run ClickHouse in every environment, not just public cloud. Feel free to contact us to discuss your analytic needs or join our Slack channel. Talk to you soon!
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.