Introducing Hybrid Tables: Transparent Query on ClickHouse® MergeTree and Iceberg Data

Your tsaritsa, sire, last night
Was delivered of a fright –
Neither son nor daughter, nor
Have we seen its like before.
– Alexander Pushin. The Tale of Tsar Saltan
Project Antalya aims to extend ClickHouse with an alternative storage model based on Iceberg and Parquet. However, Iceberg is more suited for cold data, as one can guess from its name. The hot data is best served by a regular MergeTree. How to make those two work together in a convenient way for the user? This is what the new Hybrid table engine stands for. It’s a key feature of the latest Altinity Antalya 25.8 build.
The Problem
In our previous article, we demonstrated how EXPORT PART can be used to move data from MergeTree to Iceberg. This is an important step towards the hybrid storage model. Using EXPORT PART and a bit of scripting one may implement of the following workflow:
- Load data into ClickHouse MergeTree
- EXPORT PARTS for old partitions to Iceberg
- DROP old parts from MergeTree (or use TTL DELETE)

However, it is missing one very important feature – how to query the data. We have part of the data in one table, and another part in a different table. Let’s call the “parts” segments. Segments may overlap. Therefore we need a “watermark” that divides the segments in order to avoid duplicated data. Our query can be expressed in pseudo-language as follows:
- IF date >= watermark_date, get data from the MergeTree table
- IF date < watermark_date, get data from the Iceberg table
But how to do it in SQL? Let’s look at possible options in ClickHouse, and explain why we had to develop a new one.
SQL View
The very first idea that comes to mind is using a regular VIEW and UNION ALL for two tables. For example:
CREATE VIEW my_view AS
SELECT * FROM my_mergetree_table
WHERE date >= watermark_date
UNION ALL
SELECT * FROM my_iceberg_table
WHERE date < watermark_date
It does not look too hard. Also it allows us to use parameterized views in order to set ‘watermark_date’ without changing the view. So it looked like an attractive prototype. However, actual tests showed unexpected problems.
As all of us know, ClickHouse is written in C++. Iceberg on the other hand is written in Java. That creates incompatibility between standard data types. For example, ClickHouse uses unsigned integers (UInt) extensively, while Iceberg only allows signed integers. There are others as well. Parquet can support unsigned data types. So when Parquet data files are loaded into Iceberg, the data types are inferred incorrectly. UInt becomes (signed) Int of the same scale. Now, if we query two tables, one having Int and another one having UInt, ClickHouse automatically does type casting to the bigger type. But only until you store UInt64. ClickHouse does not support type lifting to Int128 automatically, and throws an exception:
Code: 386. DB::Exception: There is no supertype for types UInt64, Int64 because some of them are signed integers and some are unsigned integers, but there is no signed integer type, that can exactly represent all required unsigned integer values. (NO_COMMON_TYPE) (version 25.8.9.20238.altinityantalya (altinity build))Of course, this problem can be solved when writing to Parquet. But there are other data type differences that confuse ClickHouse.
The biggest problem, however, is performance of aggregation queries. When one runs any aggregate function on a view with UNION ALL, ClickHouse will not push aggregation down to view subqueries, and instead unions results before applying the aggregation. This is very inefficient. While this issue could be potentially solved by rewriting the query, it looked like a path into a thicket of optimizer problems that we did not want to follow.
Merge Engine
The next idea was using the Merge table engine. This can be done as follows:
CREATE OR TABLE my_merge_table
AS my_mergetree_table
ENGINE = Merge(REGEXP('my_db|my_iceberg_db'),REGEXP('my_mergetree_table|my_iceberg_table'))This does not allow us to add watermarks directly, but we can add it with a VIEW using _table virtual column:
CREATE VIEW my_view AS
SELECT * FROM my_merge_table
WHERE (_table = my_mergetree_table AND date >= watermark_date)
OR (_table = my_iceberg_table AND date < watermark_date)This approach has an advantage that we explicitly define the schema for the Merge table (in the example above using AS statement) avoiding schema inference. However, other issues persist. The main problem is bad performance. It’s once again caused by the fact that the Merge engine does not push query execution steps down — such as aggregations or limits. In essence, a Merge table simply unifies data from multiple sources and applies most transformations afterward. The underlying tables are unaware that the data will be aggregated later, so they can’t apply optimizations like projections. The result can be significant performance degradation for analytical queries.
We also realized that SQL View and Merge table approaches do not work well when Distributed tables need to be used. Both View over Distributed and Distributed over View will lose standard ClickHouse optimizations essentially converting ClickHouse cluster into a slug.
So we continued to search for a better solution.
Distributed Engine
After several failed attempts to emulate queries to different engines using existing ClickHouse functionality, we started to think about what exactly the query to MergeTree and Iceberg means. We defined the following requirements:
- It should be possible to combine data from multiple sources
- No query rewrite should be needed when going from the existing table to a new one
- Existing ClickHouse optimizations should keep working: pushing down conditions, aggregations, limits, joins etc.
And then there was an Eureka! moment – this is very similar to Distributed engine query execution, especially if we consider swarm clusters. Distributed engine query works exactly as we need: it sends queries to multiple tables, does partial aggregation and merges results together in a node initiator. The only thing missing is the ability to query different tables, and not shards or replicas of a single table.
This is how the Hybrid table was born.
Hybrid Table Engine
The Hybrid Table Engine allows users to define multiple table segments that are selected by a condition. This is how we can define it for the original example:
CREATE TABLE my_hybrid_table AS my_mergetree_table
ENGINE = Hybrid(
cluster('{cluster}', my_mergetree_table),
date >= watermark_date,
my_iceberg_table,
date < watermark_date
)Normally there are two segments for hot and cold storage respectively, but there could be more for complex use cases.
If a user queries the above Hybrid engine table, ClickHouse will send queries to both MergeTree and Iceberg tables, adding a watermark condition. It also does a trivial expression analysis, and if a query contains a WHERE clause on ‘date’ that is fully in one segment, other segments will be ignored.
Note that Hybrid tables already work with multi-shard ClickHouse clusters. Hybrid table engine requires the first argument to be a distributed table, so we wrapped the MergeTree table in a cluster() table function.
The swarm extension is trivial as well. We just add the object_storage_cluster setting and that’s it.
There is one problem that has not been fully solved yet: data type compatibility for partial aggregation. As we discussed in the SQL View chapter above, data types in MergeTree and Iceberg have to be different sometimes. Say, MergeTree has a UInt64 column, and the corresponding Iceberg column is extended to Int128. If we try to query it with a uniq() aggregate function, for example, aggregate states between two storage types will be incompatible. In order to fix this, an extra type conversion needs to be applied automatically when sending queries to storage tables. This will be available shortly.
The Hybrid table engine opens up a lot of new capabilities for ClickHouse users. In addition to implementing tiered hybrid storage model, we can think of the following:
- Easier resharding: One can define a hybrid table with old and new (extended) cluster, re-shard in the background day by day and move watermark once data is resharded
- Canary deployments: One may route part of the traffic to a different cluster or sub-cluster
- Cache layer: One can load some data from Iceberg or data lake back to MergeTree for faster access
A New ClickHouse Architecture Is Coming
When designing the Hybrid engine we had a specific use case in mind. This use case is shared by many of our users who ingest a lot of data into ClickHouse but want to store it in an efficient way.
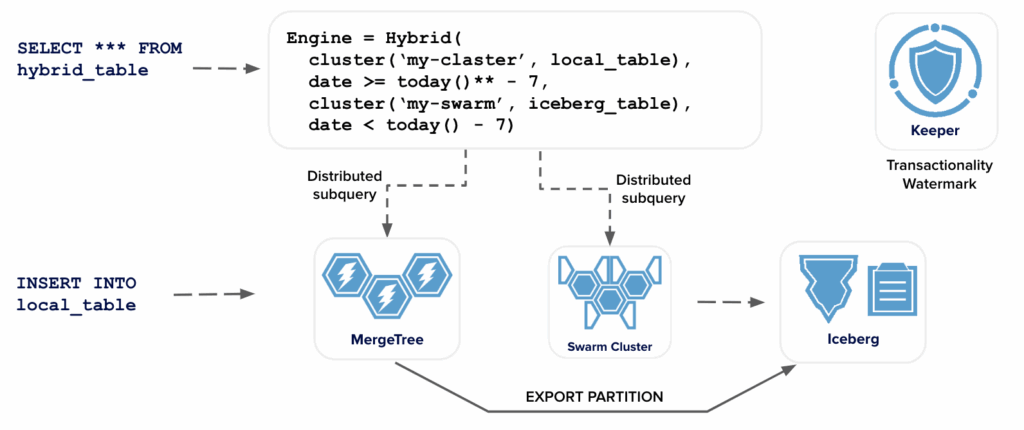
With the addition of the Hybrid table engine almost all pieces are in place. Only two features remain, but they are important:
- Transactional behaviour when moving parts from MergeTree to Iceberg requires more work and much more testing. Both ClickHouse and Iceberg are transactional systems, so an external mediator is required in order to keep them in sync.
- There is a similar challenge to manage watermarks properly, especially on a cluster with multiple shards. We are currently working on addressing those, so this architecture will go live very soon.
Important note: these features, including Hybrid tables, are not available in upstream ClickHouse builds.
The preview version of the Hybrid table engine is already available in the Altinity Antalya 25.8 version of ClickHouse. We plan a series of improvements in the minor releases to make it fully production ready.
Conclusion
In this article, we introduced a fundamental new feature of the Project Antalya version of ClickHouse – Hybrid table engine. Hybrid tables extend ClickHouse capabilities to seamlessly query data from multiple storage models together – native MergeTree and Iceberg. This is a big step towards the Project Antalya reference architecture that would allow users to extend their ClickHouse with data lake capabilities without compromising ClickHouse’s outstanding speed and performance.
Stay tuned, the future is here! And it’s distributed!
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.