Loading 100B Rows in Minutes in Altinity.Cloud®

O snail
Kobayashi Issa
Climb Mount Fuji
But slowly, slowly!
A few weeks ago the SingleStore team published interesting research in their blog. They demonstrated how to load 100 billion rows in a database in 10 minutes. While it did not seem outstanding for ClickHouse®, we were intrigued to learn how much faster we can accomplish the same task, so we conducted some experiments in Altinity.Cloud.
In this article we will discuss how to do bulk data load from S3 in the most efficient way and share our results.
TL;DR: Altinity.Cloud-managed ClickHouse can load 100 billion rows in 4 minutes using a fraction of resources!
SingleStore experiment
Let’s briefly describe the SingleStore setup. For this experiment, SingleStore launched the cluster with the following resources:
- 3 aggregator nodes (1 master, 2 child)
- 16 leaf nodes
- 128GB of memory per leaf node
- 16 vCPUs(8 CPU cores) per leaf node
- 2TB storage/leaf node
So in total it is 256 vCPUs, 2048GB of RAM and 32TB of storage. Additionally SingleStore also required 3 aggregator nodes, but they did not provide a spec for those.
The test data is extremely simple: it is a table with 3 integer columns. Here is a table definition from the SingleStore article:
create table trip_info ( distance_miles int, duration_seconds int, vehicle_id Int, sort key(distance_miles,duration_seconds) )
100 billion data points were generated with a bash script that required a giant EC2 instance with 64 vCPUs and 384GB of RAM running for 2 or 3 days to complete. The script produced 1000 CSV files that were compressed and uploaded to an S3 bucket.
The main part of the experiment was loading those files from S3 to a database. SingleStore provides a clear and convenient syntax to define loading pipelines. Once executed it loaded 100B rows from S3 into a SingleStore table powered by a 16 node cluster in 10min 56sec.
Please refer to the original SingleStore article for more detail.
Generating data in ClickHouse
As we explained in previous articles in our blog, ClickHouse can read from S3 very fast. We are going to confirm the results a bit later. Let’s remember that ClickHouse can also write to S3 buckets directly. We decided to use this feature in order to generate test data quickly and not spend 2-3 days and massive resources as the SingleStore team had to do.
Here is a sample query to generate 34.5B rows for vehicle_id = 6 and store it on S3:
INSERT INTO FUNCTION s3('https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/singlestore/data2/vehicle_6_{_partition_id}.csv.gz', '******', '******', CSV, 'miles UInt32, duration UInt32, vehicle_id UInt8', 'gzip') PARTITION BY rand() % 100
SELECT
miles,
duration,
vehicle_id
FROM
(
WITH
[1, 5, 10, 25, 50, 75, 100, 125, 150, 175] AS miles_driven,
6 AS time_for_mile,
arrayMap(x -> time_for_mile * x, miles_driven) AS duration_traveled
SELECT
miles_driven,
duration_traveled,
6 AS vehicle_id
FROM numbers_mt(3547500000)
)
ARRAY JOIN
miles_driven AS miles,
duration_traveled AS duration;Note the use of PARTITION BY extension for the s3 table function that has been developed by Vladimir Chebotarev from the Altinity server engineering team and available in ClickHouse 21.10 and above. This feature allows us to split a single insert into multiple files when writing to an S3 bucket. In this example it is split into 100 files.
For every vehicle_id the query with a different row count has been executed. The description of the data generation process in the SingleStore article is a bit cryptic, but we did our best to match the SingleStore algorithm. In total, generating data for all 10 vehicle_ids took us slightly above 2 hours on a 32 vCPU Altinity.Cloud instance, but only a fraction of instance resources were utilized for that.
Loading 100B rows into ClickHouse single node
Once we have data in S3 bucket, let’s start loading it into ClickHouse. We will use an Altinity.Cloud instance with 32 vCPUs, 128GB of RAM and 1.4TB of EBS storage.
First, let’s create the destination table:
CREATE TABLE default.insert_bench_part (
`distance_miles` UInt32,
`duration_seconds` UInt32,
`vehicle_id` UInt8
)
ENGINE = MergeTree
PARTITION BY duration_seconds
ORDER BY (vehicle_id, distance_miles)We will start with a small dataset for a single vehicle id in order to understand single server performance and decide what cluster size is required for a full dataset. ClickHouse does not provide pipeline functionality similar to SingleStore. So we will use standard SQL statements and the s3 table function. The query to load the data from S3 is very simple:
INSERT INTO insert_bench_part
SELECT * FROM s3('https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/singlestore/data/*',
CSV, 'miles UInt32, duration UInt32, vehicle_id UInt8', 'gzip')First results for 1,475,000,000 rows were encouraging.
​​0 rows in set. Elapsed: 38.359 sec. Processed 1.48 billion rows, 13.28 GB (38.45 million rows/s., 346.07 MB/s.)
1.5B rows were loaded in less than 40 seconds. That was good but we were not quite satisfied. Therefore we tuned ClickHouse parameters to use more threads for insert and bigger block size. Here is a custom configuration file that has been applied:
<clickhouse>
<profiles>
<default>
<max_threads>16</max_threads>
<max_insert_threads>16</max_insert_threads>
<input_format_parallel_parsing>0</input_format_parallel_parsing>
<min_insert_block_size_rows>5000000</min_insert_block_size_rows>
</default>
</profiles>
</clickhouse>With such settings bulk load performance has been increased more than twice:
0 rows in set. Elapsed: 17.325 sec. Processed 1.48 billion rows, 13.28 GB (85.14 million rows/s., 766.24 MB/s.)
So 1.5B rows have been loaded in 17 seconds. Let’s make very simple extrapolation:
- 17.325 / 1.475 * 100 = 1174.5
We can estimate that the full dataset will take below 20 minutes to complete on a single server.
The actual result was even slightly better – it loaded in under 19 minutes:
0 rows in set. Elapsed: 1115.393 sec. Processed 100.00 billion rows, 900.00 GB (89.65 million rows/s., 806.89 MB/s.)
This is twice as long as the SingleStore result, but we used a single server whereas SingleStore used 16 node cluster. Let’s see what it takes us to load 100B rows in under 10 minutes.
Loading 100B rows into ClickHouse cluster
We could scale a single instance vertically and get more performance but it is limited by storage. So let’s try to scale horizontally and see how we can load data ultra fast into the ClickHouse cluster. Since a single node could complete data load in 19 minutes, we expect that two nodes can do the same in under 10 minutes if the load is parallelized properly across cluster nodes. So let’s scale the cluster to two nodes, which takes just 5 minutes in Altinity.Cloud.
Once scaled, we need to create a distributed table:
CREATE TABLE default.insert_bench_part_dist (
`distance_miles` UInt32,
`duration_seconds` UInt32,
`vehicle_id` UInt8
)
ENGINE = Distributed('all-sharded', 'default', 'insert_bench_part', rand())Now we want to insert into a distributed table from S3 as fast as possible. We have already discussed some approaches in the article ‘Tips for High-Performance ClickHouse Clusters with S3 Object Storage’. So let’s try using the s3Cluster function. It retrieves a list of objects from the bucket first, and then dispatches load jobs to different shards of the cluster. It seems to fit perfectly for this purpose. As before, we start with a subset of the data and then continue with a full dataset:
INSERT INTO insert_bench_dist
SELECT * FROM s3Cluster('all-sharded', 'https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/singlestore/data/*',
CSV, 'miles UInt32, duration UInt32, vehicle_id UInt8', 'gzip')
0 rows in set. Elapsed: 56.433 sec. Processed 1.48 billion rows, 13.28 GB (26.14 million rows/s., 235.24 MB/s.)Oops! What has happened? Why is it so slow? In order to answer this question let’s look into processes on every shard when the query is being executed. In Altinity.Cloud it is easy to run a query on all cluster nodes at once and see results from multiple nodes together:
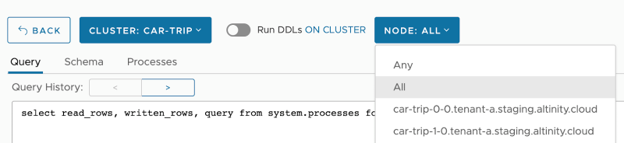
​​select read_rows, written_rows, query from system.processes format Vertical;
car-trip-0-0.tenant-a.staging.altinity.cloud:
Row 1:
───────€
read_rows: 220000000
written_rows: 225000494
query: INSERT INTO insert_bench_dist
SELECT * FROM s3Cluster('all-sharded', 'https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/singlestore/data/*', CSV, 'miles UInt32, duration UInt32, vehicle_id UInt8', 'gzip');
Row 2:
───────€
read_rows: 180000000
written_rows: 0
query: SELECT miles, duration, vehicle_id FROM s3Cluster('all-sharded', 'https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/singlestore/data/*', 'CSV', 'miles UInt32, duration UInt32, vehicle_id UInt8', 'gzip')
car-trip-1-0.tenant-a.staging.altinity.cloud:
Row 1:
───────€
read_rows: 45000000
written_rows: 0
query: SELECT miles, duration, vehicle_id FROM s3Cluster('all-sharded', 'https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/singlestore/data/*', 'CSV', 'miles UInt32, duration UInt32, vehicle_id UInt8', 'gzip')
Row 2:
───────€
read_rows: 0
written_rows: 2498749
query: INSERT INTO default.insert_bench_part (distance_miles, duration_seconds, vehicle_id) VALUESAt the first glance both shards are busy reading data from S3 and writing to a distributed table. But look at read_rows and written_rows for the insert part. You will see that on the second shard read_rows is zero! Here is a picture that illustrates the data flow:
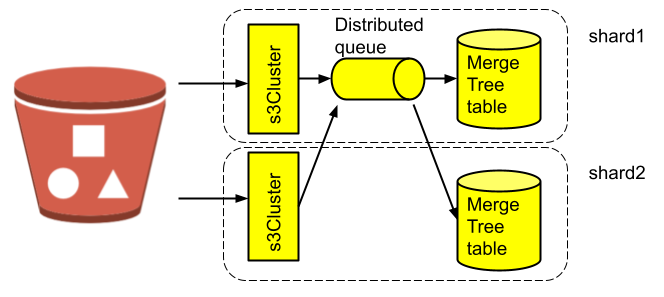
So, although s3Cluster retrieves data from S3 on multiple nodes in parallel, it still sends all the data to a distributed table queue on a single node for insert. This is definitely not efficient. Is there a way to insert data at the same shard where it is selected?
ClickHouse has a setting for that purpose – parallel_distributed_insert_select. When enabled it allows INSERT-SELECT data between distributed tables locally. Since s3Cluster works somewhat similar to a distributed table, can we use this mode for our purpose here?
Unfortunately, s3Cluster does not respect this setting yet. We have already filed an issue with the ClickHouse team, and hope it will be implemented soon. Before then, we’ll have to do a workaround.
First, we let’s create a view on every shard that filters half of the files from the S3 bucket:
CREATE VIEW default.read_s3 ON CLUSTER '{cluster}'
(
`miles` UInt32,
`duration` UInt32,
`vehicle_id` UInt8
) AS
SELECT * FROM s3(concat('https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/singlestore/data2/*_{',
replace(replace(toString(range(50 * toUInt32(getMacro('shard')), 50 * (toUInt32(getMacro('shard')) + 1))), '[', ''), ']', ''),
'}.csv.gz'),
CSV, 'miles UInt32, duration UInt32, vehicle_id UInt8', 'gzip')The key part here is a regular expression that maps shard number to a glob pattern unique for every shard. For example, for the first shard it results in following pattern:
https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/singlestore/data2/*_{0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49}.csv.gzFor the second shard it will cover a range from 50 to 99. Since for every vehicle id we generated files with partition suffix ranged from 0 to 99, this approach allows us to pick half of the files for the shard. Not exactly easy, but effective.
Then we create a distributed table on top of this view:
CREATE TABLE default.read_s3_dist ON CLUSTER 'all-sharded' (
`miles` UInt32,
`duration` UInt32,
`vehicle_id` UInt8
)
ENGINE = Distributed('all-sharded', 'default', read_s3)Now we can insert select using this distributed table as follows:
INSERT INTO insert_bench_dist SELECT * FROM read_s3_dist SETTINGS parallel_distributed_insert_select = 2; 0 rows in set. Elapsed: 552.631 sec. Processed 100.00 billion rows, 900.00 GB (180.95 million rows/s., 1.63 GB/s.)
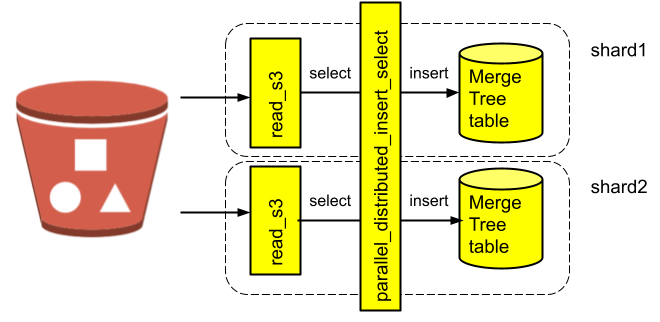
The load speed is exactly twice faster than a single node of the same size, 552s vs 1115s, so we have loaded 100B rows in slightly more than 9 minutes.
Let’s compare results side by side with SingleStore:
| SingleStore | Altinity.Cloud ClickHouse | |
| Cluster size | 16+3 nodes | 2 nodes |
| Total resources | 256 vCPUs, 2048GB RAM, 32TB storage | 64 vCPUs, 256GB RAM, 2.8TB storage |
| Load time | 10m 56s | 9m 12s |
As you can see we used 4 to 10 times less resources and yet loaded 100B rows 15% faster than SingleStore!
Ok, ClickHouse can load data faster than SingleStore. But how much faster? Let’s conduct a few more tests.
More nodes and more power
In real systems, two shard clusters are rare. So let’s load data into a 4 shard cluster. We will start with smaller 16vCPU nodes for that purpose, so total resources are the same as before, but distributed over 4 nodes.
Re-scaling of the 2 node cluster to a 4 node cluster with different node size takes less than 10 minutes in Altinity.Cloud. Once done, we need to re-do read_s3 view, since we need to partition data by different ranges:
CREATE VIEW default.read_s3 ON CLUSTER '{cluster}'
(
`miles` UInt32,
`duration` UInt32,
`vehicle_id` UInt8
) AS
SELECT * FROM s3(concat('https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/singlestore/data2/*_{',
replace(replace(toString(range(25 * toUInt32(getMacro('shard')), 25 * (toUInt32(getMacro('shard')) + 1))), '[', ''), ']', ''),
'}.csv.gz'),
CSV, 'miles UInt32, duration UInt32, vehicle_id UInt8', 'gzip')Once the view is altered we can repeat INSERT-SELECT.
0 rows in set. Elapsed: 583.651 sec. Processed 100.00 billion rows, 900.00 GB (171.34 million rows/s., 1.54 GB/s.)
So it is a tad slower than 2 nodes cluster, but still below 10 minutes and more than 1 minute faster than SingleStore.
Let’s now scale the 4 node cluster to bigger 32 vCPU nodes (128vCPUs in total) that we used before and re-run the load.
0 rows in set. Elapsed: 346.386 sec. Processed 100.00 billion rows, 900.00 GB (288.70 million rows/s., 2.60 GB/s.)
With bigger nodes we can load data in 5 minutes!
And for the very last experiment let’s scale the cluster to 10 nodes, 16 vCPUs each, that gives us 160 vCPUs in total. We need to adjust the view to match shard count and re-run the load:
0 rows in set. Elapsed: 252.868 sec. Processed 100.00 billion rows, 900.00 GB (395.46 million rows/s., 3.56 GB/s.)
4 minutes 13 seconds! This is 2.5 times faster than SingleStore can do at 60% of computing power! Note that we reached 400 million rows per second!
We could continue scaling the cluster even further, but we’ve already proved the point. Here is the summary chart that compares all results:

Conclusion
ClickHouse is known for extremely high query performance. It is less well known that ClickHouse can also insert bulk data very fast from external sources. When operating ClickHouse in Altinity.Cloud, S3 is a natural source for bulk data. In our article “Ultra-Fast Data Loading and Testing in Altinity.Cloud” we already demonstrated how fast ClickHouse can load from S3. Today, we showed how to scale loading from S3 to a cluster, and load 100B rows dataset in 4 minutes. This is way ahead of other analytical databases. ClickHouse in Altinity.Cloud rocks, as usual!
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.
True, Clickhouse can ingest data faster, but you did not explain what it takes to setup several nodes in Clickhouse. and that query to load data from S3 toUInt32(getMacro(‘shard’)) … seems to require some engineering, compare to Singlestore simple SQL query to load data from S3.
Now, i’d like to see how Clickhouse performs when you start joining tables.
Hi Franck,
It takes just a few minutes to start a cluster in Altinity.Cloud or using https://github.com/Altinity/clickhouse-operator/. As for the approach in the article — it is 1.5 years old. Since then ClickHouse improved usability and s3cluster() function can be used without extra effort.
Thanks,
Alexander