Announcing Version 2.0 of the Altinity ClickHouse® Sink Connector

Recently Altinity released version 2.0 of the Altinity ClickHouse Sink Connector. This open-source, Apache 2.0-licensed project lets you mirror changes from a MySQL or PostgreSQL database into ClickHouse. There are two variations of the project:
- The ClickHouse Lightweight Sink Connector – Provides Change Data Capture (CDC) support to use a single binary to synchronize MySQL or PostgreSQL with ClickHouse.
- The ClickHouse Kafka Sink Connector – Listens to CDC data published to a Kafka topic and writes the changes to ClickHouse.
We built the Sink Connector to make it easy to use ClickHouse to do analytics on data stored in MySQL or PostgreSQL. That lets you run analytics queries on the ClickHouse without impacting your production MySQL or PostgreSQL servers.
[BTW, we’re focusing on MySQL here, but the things we say about MySQL apply to PostgreSQL as well. To keep it simple, we’ll just say “MySQL” instead of “MySQL or PostgreSQL.”]
MySQL is great for transaction processing; with the right hardware it can execute more than a million queries per second and handle tens of thousands of simultaneous connections. But it’s not great for analytics queries, which typically scan large volumes of data and compute aggregates. Why is ClickHouse better for analytics? There are several reasons:
- ClickHouse stores data in columns, while MySQL stores it in rows. Analytics queries typically focus on a few fields, so the amount of data ClickHouse has to read to process a query is much smaller. And with compression, the amount of data ClickHouse reads can be four orders of magnitude smaller.
- ClickHouse stores table data in parts and scans them in parallel. MySQL, on the other hand, is mostly single-threaded and can’t usually parallelize query processing.
- ClickHouse computes aggregates much more efficiently, including sums, averages, counts, standard deviations, and other useful functions.
We discussed the synergy between ClickHouse and MySQL in more detail in our earlier blog post Using ClickHouse as an Analytic Extension for MySQL. (When you’re ready to see the Sink Connector in action, see our follow-on blog post Using Version 2.0 of the Altinity ClickHouse Sink Connector for examples you can run on your machine.)
The Lightweight Sink Connector
The major new thing in version 2.0 is an updated version of the Lightweight Sink Connector. This is now a single executable (aka it doesn’t need Kafka) that does Change Data Capture (CDC) for a MySQL database. As things change in MySQL, those changes are mirrored in ClickHouse. That includes creating or updating or deleting records or tables.
We won’t discuss this in any degree of detail here, but the Sink Connector uses the open-source Debezium library as a CDC engine. Most significantly, Debezium looks at MySQL’s binlog to get the details of every change to the database. That means Debezium doesn’t put any load on the MySQL server at all. (Well, not much of a load, anyway. Obviously Debezium uses some CPU and disk I/O resources, but that impact is minimal and can be minimized by sizing the MySQL server’s compute resources appropriately.)
(When you’re using the Sink Connector with PostgreSQL, the Sink Connector / Debezium combination uses PostgreSQL’s WAL (write-ahead logs) to do the same thing.)
(Apologies for the parenthetical phrases; we’ll try to keep those at a minimum going forward.)
New features in version 2.0
Version 2.0 has an updated lightweight connector. Our motivation to develop the lightweight solution focused on these requirements:
- A single executable: Don’t require a Kafka server, a schema registry, or source connectors.
- No data loss: Handle failures in MySQL, ClickHouse and/or the Sink Connector. The overall system should recover from failures without losing data.
- Replication across time zones: Replicate
DateTimevalues correctly when the MySQL server and ClickHouse are in different time zones. - Data consistency: Maintain order of execution of statements in ClickHouse; executing statements in a different order will create inconsistencies in the data.
- DDL support: DDL replication support has been enhanced, and the order of execution is now guaranteed to be correct.
We have been working towards a General Availability (GA) release in the last few months and wanted to highlight the features that were included in the release.
Checkpointing / Offset storage
Beginning with the 2.3.0.Alpha1 release of Debezium in May 2023, Altinity contributed to Debezium JDBC storage that enables the lightweight connector to store binlog offset information of MySQL (and Log Sequence Number information of PostgreSQL) in ClickHouse tables. This approach eliminates the need for Kafka.
MySQL offset storage:
> select * from altinity_sink_connector.replica_source_info;
Name |Value |
-----------------+----------------------------------------------+
id |cd491108-69d9-49b2-835c-a28dc2de85d5 |
offset_key |["company-1",{"server":"embeddedconnector"}] |
offset_val | {"ts_sec":1709329719,"file":"mysql-bin.000003","pos":197,"gtids":"62e275df-d815-11ee-914d-0242ac160004:1-56","snapshot":true |
record_insert_ts |2024-03-01 15:48:45 |
Record_insert_seq|33 |
PostgreSQL offset storage:
> select * from altinity_sink_connector.replica_source_info;
Name |Value |
-----------------+---------------------------------------------------------------+
id |311e02bb-e183-40ea-b3c9-5a2b8e701a1c |
offset_key | ["debezium-embedded-postgres",{"server":"embeddedconnector"} |
offset_val | {"last_snapshot_record":true,"lsn":27217352,"txId":733,"ts_usec":1709329842100920,"snapshot":true}|
record_insert_ts |2024-03-01 15:50:42 |
Record_insert_seq|1 |
Fault Tolerance / Atomic updates of checkpoint data
Monitoring a database for changes and updating a ClickHouse database in response is great, but downstream from the MySQL database is the Sink Connector and the ClickHouse database. Those can fail like any other software component, so it’s vital that any changes to the MySQL database eventually find their way into the ClickHouse database if either of those components are down.
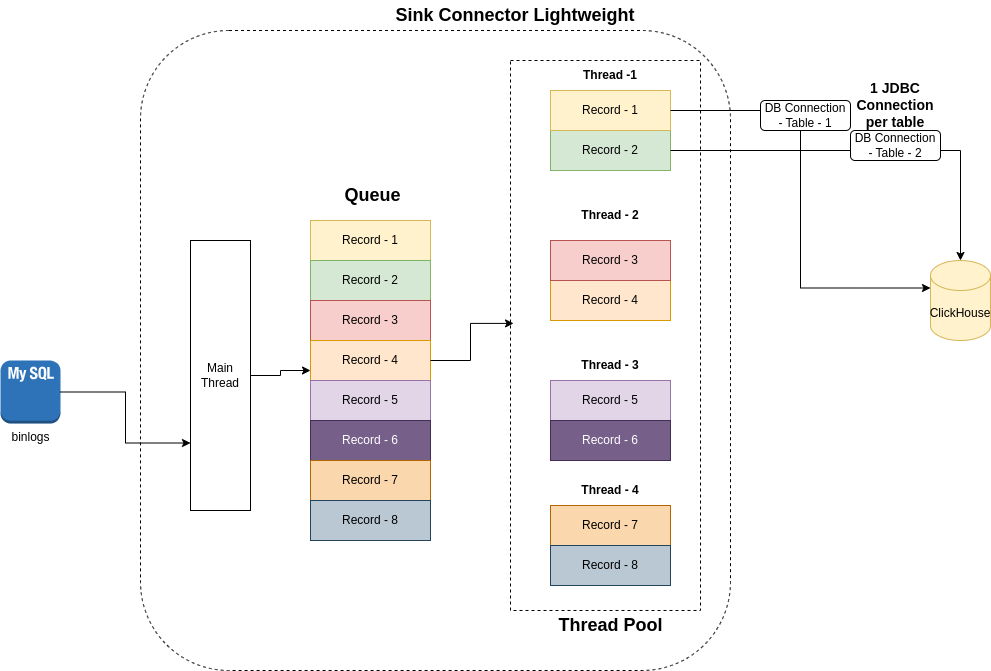
As seen in the flow diagram above, the CDC records that are read from MySQL binlogs (or PostgreSQL WAL logs) go through a sequence of steps before they get persisted to ClickHouse. Crash-safe replication is essential to guard against any data loss. There are always factors beyond our control (power failures, network outages, machines rebooting without a clean shutdown, etc.), so we need to make sure replication handles catastrophes correctly.
Even though the offset storage enables the Sink Connector to start replication from the last stored offsets, another key requirement is to update offsets only after the data is persisted to ClickHouse.
If the offsets are persisted before the data is written to ClickHouse, then we could experience a data loss. In a multi-threaded environment, with multiple threads persisting data to ClickHouse in parallel, synchronization between threads is a requirement to make sure the order of messages is maintained as it is received from the source database.
In the 2.0 release we have added functionality that will guarantee that the offsets are persisted to the offset storage only after the records are persisted to ClickHouse.
In case of failures of persisting to ClickHouse, the Sink Connector will keep retrying, giving an Engineer the opportunity to fix the original cause of failure and to restart replication. We take a quick look at how the Sink Connector handles failures in the blog post Using the Altinity ClickHouse Sink Connector version 2.0.
Replication across different time zones
There are possibilities that the MySQL server could be running in a different timezone than the host timezone. Also there is a possibility that the ClickHouse server could be running in a different timezone. In all these different variations, replication needs to guarantee that the data is preserved and the timezone information is retained.
The MySQL server’s timezone an be retrieved using the following command:
> SELECT @@system_time_zone;
@@system_time_zone|
------------------+
CDT |
The ClickHouse command looks like this:
> SELECT timezone();
Name |Value |
----------+---------------+
timezone()|America/Chicago|
In this example, MySQL and ClickHouse are set to CDT instead of UTC. Let’s see how this works by creating a new table in MySQL:
> CREATE TABLE `temporal_types_DATETIME6` (
`Type` varchar(50) NOT NULL,
`Minimum_Value` datetime(6) NOT NULL,
`Mid_Value` datetime(6) NOT NULL,
`Maximum_Value` datetime(6) NOT NULL,
`Null_Value` datetime(6) DEFAULT NULL
PRIMARY KEY (`Type`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
[2024-04-02 22:18:17] completed in 21 ms
The Sink Connector translates the MySQL DDL syntax to ClickHouse syntax and creates a new table:
> SHOW CREATE TABLE temporal_types_DATETIME6;
CREATE TABLE test.temporal_types_DATETIME6
(
`Type` String,
`Minimum_Value` DateTime64(6),
`Mid_Value` DateTime64(6),
`Maximum_Value` DateTime64(6),
`Null_Value` Nullable(DateTime64(6)),
`_version` UInt64,
`is_deleted` UInt8
)
ENGINE = ReplacingMergeTree(_version, is_deleted)
ORDER BY Type
SETTINGS index_granularity = 8192
Let’s insert a row into the MySQL table:
> INSERT INTO `temporal_types_DATETIME6` VALUES ('DATETIME(6)','1000-01-01 00:00:00.000000','2022-09-29 01:50:56.123456','9999-12-31 23:59:59.999999',NULL);
[2024-04-02 22:22:44] 1 row affected in 4 ms
The data in ClickHouse:
> SELECT Minimum_Value, Mid_Value, Maximum_Value FROM temporal_types_DATETIME6;
Name |Value |
-------------+--------------------------+
Type |DATETIME(6) |
Minimum_Value|1000-01-01 00:00:00 |
Mid_Value |2022-09-28 20:50:56.123456|
Maximum_Value|9999-12-31 23:59:59.999999|
Null_Value | |
Notice that the Mid_Value DateTime field is converted to the Chicago timezone (2022-09-29 01:50:56.123456 becomes 2022-09-28 20:50:56.123456). The Sink Connector reads the ClickHouse server’s timezone and converts DateTime values to the default server timezone. The reason for this behavior is that DateTime values are stored as epoch milliseconds in UTC. See the Debezium documentation on temporal types for more information.
If you want the Sink Connector to persist DateTime values in UTC, you can override the setting in the YAML file:
clickhouse.datetime.timezone: “UTC”
Restart the Sink Connector after adding the configuration, then let’s repeat the same set of statements to observe the behavior. After creating the table in MySQL as above, observe the table schema in ClickHouse:
> SHOW CREATE TABLE temporal_types_DATETIME6;
CREATE TABLE test.temporal_types_DATETIME6
(
`Type` String,
`Minimum_Value` DateTime64(6, 'UTC'),
`Mid_Value` DateTime64(6, 'UTC'),
`Maximum_Value` DateTime64(6, 'UTC'),
`Null_Value` Nullable(DateTime64(6, 'UTC')),
`_version` UInt64,
`is_deleted` UInt8
)
ENGINE = ReplacingMergeTree(_version, is_deleted)
ORDER BY Type
SETTINGS index_granularity = 8192
The columns have the timezone parameter set to UTC. This is a Sink Connector functionality that lets you override the default timezone of the ClickHouse server. So we can insert the same row into the MySQL table:
> INSERT INTO `temporal_types_DATETIME6` VALUES ('DATETIME(6)','1000-01-01 00:00:00.000000','2022-09-29 01:50:56.123456','9999-12-31 23:59:59.999999',NULL)
[2024-04-02 22:22:44] 1 row affected in 4 ms
And the data in ClickHouse is now in UTC:
> SELECT Minimum_Value, Mid_Value, Maximum_Value FROM temporal_types_DATETIME6;
Name |Value |
-------------+--------------------------+
Type |DATETIME(6) |
Minimum_Value|1000-01-01 00:00:00 |
Mid_Value |2022-09-29 01:50:56.123456|
Maximum_Value|9999-12-31 23:59:59.999999|
Null_Value | |
The value of Mid_Value is unchanged at 2022-09-29 01:50:56.123456.
DDL Replication:
Quite a few improvements/bug fixes were added to support DDL replication:
- Support for MySQL Generated columns: MySQL generated columns will be replicated as ClickHouse
MATERIALIZEDcolumns. - Partition columns:
CREATE TABLEstatements with partition by range will be replicated to ClickHouse.
Guaranteed order of execution of DDL (MySQL):
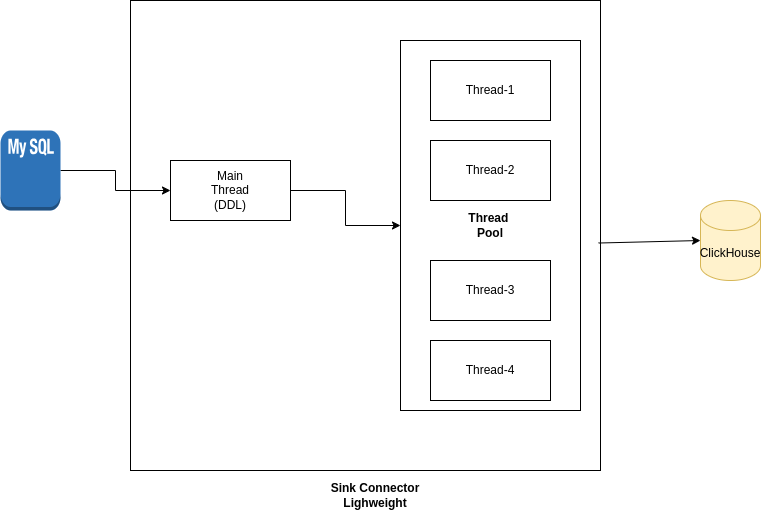
When DDL statements are executed, it’s essential that there are no other Batch inserts executed around the same time. This functionality is implemented in the Lightweight version by handling the DDL’s in the main thread and as soon as the DDL is received, there is a notification event the main thread sends to the other threads in the thread pool to finish the execution.
When all the threads have completed the execution of the batch inserts, the DDL is executed on the main thread.
Sink Connector Roadmap
You can find the project roadmap in our GitHub repo. Here are some of the highlights we’re planning for the near future:
- GA-level MongoDB support
- Support for multiple source databases in one Sink Connector process
- Column overrides
- Production Kafka connector
- Production Helm chart for Kubernetes
The project is completely open-source and open to contributions. Join us!
We also encourage you to start discussions or create feature requests on the project’s GitHub repo. You can also reach out to us directly on the AltinityDB Slack workspace if you have any questions.
Summary
The Altinity Sink Connector is a great way to add sophisticated analytics to your organization with minimal impact to your production MySQL or PostgreSQL system. With the data in ClickHouse, you get the advantages of a world-class, open-source analytics engine without losing transactions and other things that MySQL and PostgreSQL do so well.
We encourage you to get the code and work with it. The Docker and YAML files make it easy to get started, and you can modify those files to work with your own servers.
For more information
To learn more about the Altinity Sink Connector project, how ClickHouse and MySQL work well together, and the details of the ReplacingMergeTree engine, we highly recommend the following articles:
- Fast MySQL to ClickHouse Replication: Announcing the Altinity Sink Connector for ClickHouse (17 June 2022) – The article that announced the Sink Connector project and explained what it’s all about.
- Replicating Data from PostgreSQL to ClickHouse with the Altinity Sink Connector (25 July 2023) – Shows the project in action with PostgreSQL…we focused on MySQL here, but the principles are the same.
- Using ClickHouse as an Analytic Extension for MySQL (12 October 2022) – Explains the high-level reasons for using ClickHouse and MySQL together.
- ClickHouse ReplacingMergeTree Explained: The Good, The Bad, and The Ugly (10 May 2023) – A great explanation of how ReplacingMergeTree works.
- The Altinity Knowledge Base has an in-depth discussion of the ReplacingMergeTree engine.