Using Joins in ClickHouse® Materialized Views

ClickHouse materialized views provide a powerful way to restructure data in ClickHouse. We have discussed their capabilities many times in webinars, blog articles, and conference talks. One of the most common follow-on questions we receive is whether materialized views can support joins.
The answer is emphatically yes. This blog article shows how. If you are looking for a quick answer, here it is: materialized views trigger off the left-most table of the join. The materialized view will pull values from right-side tables in the join but will not trigger if those tables change.
Read on for detailed examples of materialized view with joins behavior. We also explain what is going on under the covers to help you better reason about ClickHouse behavior when you create your own views. Note: Examples are from ClickHouse version 20.3.
If you love ClickHouse®, Altinity can simplify your experience with our fully managed service in your cloud (BYOC) or our cloud and 24/7 expert support. Learn more.
Table Definitions
Materialized views can transform data in all kinds of interesting ways but we’re going to keep it simple. We’ll use an example of a table of downloads and demonstrate how to construct daily download totals that pull information from a couple of dimension tables. Here’s a summary of the schema.
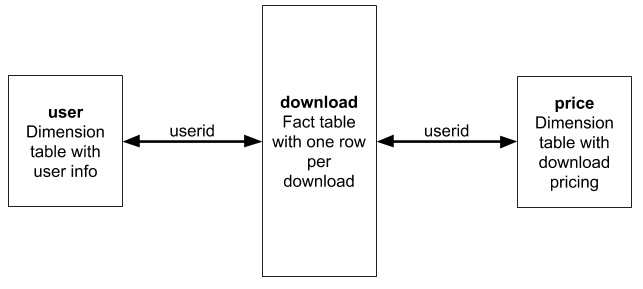
Let’s start by defining the download table. This table can grow very large.
CREATE TABLE download (
when DateTime,
userid UInt32,
bytes UInt64
) ENGINE=MergeTree
PARTITION BY toYYYYMM(when)
ORDER BY (userid, when)Next, let’s define a dimension table that maps user IDs to price per Gigabyte downloaded. This table is relatively small.
CREATE TABLE price (
userid UInt32,
price_per_gb Float64
) ENGINE=MergeTree
PARTITION BY tuple()
ORDER BY useridFinally, we define a dimension table that maps user IDs to names. This table is likewise small.
CREATE TABLE user (
userid UInt32,
name String
) ENGINE=MergeTree
PARTITION BY tuple()
ORDER BY useridMaterialized View Definition
Now let’s create a materialized view that sums daily totals of downloads and bytes by user ID with a price calculation based on number of bytes downloaded. We need to create the target table directly and then use a materialized view definition with TO keyword that points to our table.
Here is the target table.
CREATE TABLE download_daily (
day Date,
userid UInt32,
downloads UInt32,
total_gb Float64,
total_price Float64
)
ENGINE = SummingMergeTree
PARTITION BY toYYYYMM(day) ORDER BY (userid, day)The above definition takes advantage of specialized SummingMergeTree behavior. Any non-key numeric field is considered to be an aggregate, so we don’t have to use aggregate functions in the column definitions.
Finally, here is our materialized view definition. It is possible to define this in a more compact way, but as you’ll see shortly this form makes it easier to extend the view to join with more tables.
CREATE MATERIALIZED VIEW download_daily_mv
TO download_daily AS
SELECT
day AS day, userid AS userid, count() AS downloads,
sum(gb) as total_gb, sum(price) as total_price
FROM (
SELECT
toDate(when) AS day,
userid AS userid,
download.bytes / (1024*1024*1024) AS gb,
gb * price.price_per_gb AS price
FROM download LEFT JOIN price ON download.userid = price.userid
)
GROUP BY userid, dayLoading Data
We can now test the view by loading data. Let’s first load up both dimension tables with user name and price information.
INSERT INTO price VALUES (25, 0.10), (26, 0.05), (27, 0.01);INSERT INTO user VALUES (25, 'Bob'), (26, 'Sue'), (27, 'Sam');Next, we add sample data into the download fact table. The following INSERT adds 5000 rows spread evenly over the userid values listed in the user table.
INSERT INTO download
WITH
(SELECT groupArray(userid) FROM user) AS user_ids
SELECT
now() + number * 60 AS when,
user_ids[(number % length(user_ids)) + 1] AS user_id,
rand() % 100000000 AS bytes
FROM system.numbers
LIMIT 5000At this point we can see that the materialized view populates data into download_daily. Here’s a sample query.
SELECT day, downloads, total_gb, total_price
FROM download_daily WHERE userid = 25┌─────────€day─┬─downloads─┬────────────€total_gb─┬─────────€total_price─┐
│ 2020-07-14 │ 108 │ 5.054316438734531 │ 0.5054316438734532 │
│ 2020-07-15 │ 480 │ 22.81532768998295 │ 2.281532768998296 │
│ 2020-07-16 │ 480 │ 21.07045224122703 │ 2.107045224122702 │
│ 2020-07-17 │ 480 │ 21.606687822379172 │ 2.1606687822379183 │
│ 2020-07-18 │ 119 │ 5.548438269644976 │ 0.5548438269644972 │
└───────────┴───────────┴────────────────────┴─────────────────────┘So far so good. But we can do more. Let’s first take a detour into what ClickHouse does behind the scenes.
A Dive into the Plumbing
To use materialized views effectively it helps to understand exactly what is going on under the covers. Materialized views operate as post insert triggers on a single table. If the query in the materialized view definition includes joins, the source table is the left-side table in the join.
In our example download is the left-side table. Any insert on download therefore results in a part written to download_daily. Inserts to user have no effect, though values are added to the join.
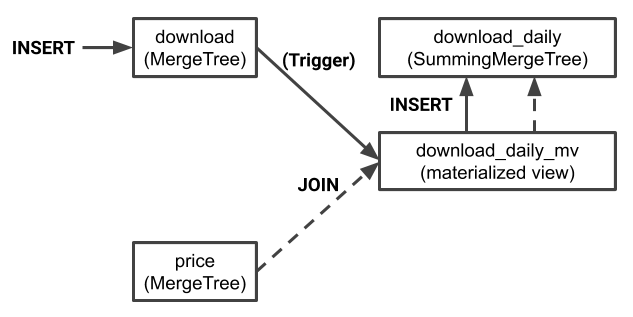
It’s easy to demonstrate this behavior if we create a more interesting kind of materialized view. Let’s define a view that does a right outer join on the user table. In this case we’ll use a simple MergeTree table table so we can see all generated rows without the consolidation that occurs with SummingMergeTree. Here’s a simple target table followed by a materialized view that will populate it from the download table.
CREATE TABLE download_right_outer (
when DateTime,
userid UInt32,
name String,
bytes UInt64
) ENGINE=MergeTree
PARTITION BY toYYYYMM(when)
ORDER BY (when, userid)CREATE MATERIALIZED VIEW download_right_outer_mv
TO download_right_outer
AS SELECT
when AS when,
user.userid AS userid,
user.name AS name,
bytes AS bytes
FROM download RIGHT OUTER JOIN user ON (download.userid = user.userid)What happens when we insert a row into table download? The materialized view generates a row for each insert *and* any unmatched rows in table user, since we’re doing a right outer join. (This view also has a potential bug that you might already have noticed. We’ll get to that shortly.)
INSERT INTO download VALUES (now(), 26, 555)SELECT * FROM download_right_outer┌─────────────────€when─┬─userid─┬─name─┬─bytes─┐
│ 2020-07-12 17:27:35 │ 26 │ Sue │ 555 │
└────────────────────┴────────┴──────┴────────┘┌─────────────────€when─┬─userid─┬─name─┬─bytes─┐
│ 0000-00-00 00:00:00 │ 25 │ Bob │ 0 │
│ 0000-00-00 00:00:00 │ 27 │ Sam │ 0 │
└────────────────────┴────────┴──────┴────────┘On the other hand, if you insert a row into table user, nothing changes in the materialized view.
INSERT INTO user VALUES (28, 'Kate')SELECT * FROM download_right_outer┌─────────────────€when─┬─userid─┬─name─┬─bytes─┐
│ 2020-07-12 17:27:35 │ 26 │ Sue │ 555 │
└────────────────────┴────────┴──────┴────────┘┌─────────────────€when─┬─userid─┬─name─┬─bytes─┐
│ 0000-00-00 00:00:00 │ 25 │ Bob │ 0 │
│ 0000-00-00 00:00:00 │ 27 │ Sam │ 0 │
└────────────────────┴────────┴──────┴────────┘You will only see the effect of the new user row when you add more rows to table download.
Joining on multiple tables
Like SELECT statements, materialized views can join on several tables. In the first example we joined on the download price, which varies by userid. Let’s now join on a second table, user, that maps userid to a username. For this example we’ll add a new target table with the username column added. Since username is not an aggregate, we’ll also add it to the ORDER BY. That will prevent the SummingMergeTree engine from trying to aggregate it.
CREATE TABLE download_daily_with_name (
day Date,
userid UInt32,
username String,
downloads UInt32,
total_gb Float64,
total_price Float64
)
ENGINE = SummingMergeTree
PARTITION BY toYYYYMM(day) ORDER BY (userid, day, username)Now let’s define the materialized view, which extends the SELECT of the first example in a straightforward way.
CREATE MATERIALIZED VIEW download_daily_with_name_mv
TO download_daily_with_name AS
SELECT
day AS day, userid AS userid, user.name AS username,
count() AS downloads, sum(gb) as total_gb, sum(price) as total_price
FROM (
SELECT
toDate(when) AS day,
userid AS userid,
download.bytes / (1024*1024*1024) AS gb,
gb * price.price_per_gb AS price
FROM download LEFT JOIN price ON download.userid = price.userid
) AS join1
LEFT JOIN user ON join1.userid = user.userid
GROUP BY userid, day, usernameYou can test the new view by truncating the download table and reloading data. We’ll leave that as an exercise for the reader.
Like this content? Subscribe to our newsletter to get the latest ClickHouse tips straight to your inbox.
Be careful what you wish for
ClickHouse SELECT statements support a wide range of join types, which offers substantial flexibility in the transformations enabled by materialized views. Flexibility can be a mixed blessing, since it creates more opportunities to generate results you do not expect.
For instance, what happens if you insert a row into download with a userid 30? This userid does not exist in either the user or price tables.
INSERT INTO download VALUES (now(), 30, 222)Short answer: the row might not appear in the target table if you don’t define the materialized view carefully. To ensure a match you either have to do a LEFT OUTER JOIN or FULL OUTER JOIN. This makes sense since it’s the same behavior you would get from running the SELECT by itself. The download_right_outer_mv example had exactly this problem, as hinted above.
View definitions can also generate subtle syntax errors. For instance, leaving off GROUP BY terms can result in failures that may be a bit puzzling. Here is a simple example.
CREATE MATERIALIZED VIEW download_daily_join_old_style_mv
ENGINE = SummingMergeTree PARTITION BY toYYYYMM(day)
ORDER BY (userid, day) POPULATE AS SELECT
toDate(when) AS day,
download.userid AS userid,
user.username AS name,
count() AS downloads,
sum(bytes) AS bytes
FROM download INNER JOIN user ON download.userid = user.userid
GROUP BY userid, day -- Column `username` is missing!Received exception from server (version 20.3.8):
Code: 10. DB::Exception: Received from localhost:9000. DB::Exception: Not found column name in block. There are only columns: userid, toStartOfDay(when), count(), sum(bytes). What’s wrong? Column username was left off the GROUP BY. ClickHouse is behaving sensibly in refusing the view definition, but the error message is a little hard to decipher.
Finally, it’s important to specify columns carefully when they overlap between joined tables. Here is a slightly different version of the previous RIGHT OUTER JOIN example from above.
CREATE MATERIALIZED VIEW download_right_outer_mv
TO download_right_outer
AS SELECT
when AS when,
userid,
user.name AS name,
bytes AS bytes
FROM download RIGHT OUTER JOIN user ON (download.userid = user.userid)When you insert rows into download you’ll get a result like the following with userid dropped from non-matching rows.
SELECT * FROM download_right_outer┌─────────────────€when─┬─userid─┬─name─┬─bytes─┐
│ 0000-00-00 00:00:00 │ 0 │ Sue │ 0 │
│ 0000-00-00 00:00:00 │ 0 │ Sam │ 0 │
└────────────────────┴────────┴──────┴────────┘┌─────────────────€when─┬─userid─┬─name─┬─bytes─┐
│ 2020-07-12 18:04:56 │ 25 │ Bob │ 222 │
└────────────────────┴────────┴──────┴────────┘It seems that ClickHouse puts in the default value in this case rather than assigning the value from user.userid. You must name the column value unambiguously and assign the name using AS userid. This is not what the SELECT query does if you run it standalone. The behavior looks like a bug.
Conclusion
Materialized views are one of the most versatile features available to ClickHouse users. The materialized view is populated with a SELECT statement and that SELECT can join multiple tables. The key thing to understand is that ClickHouse only triggers off the left-most table in the join. Other tables can supply data for transformations but the view will not react to inserts on those tables.
Joins introduce new flexibility but also offer opportunities for surprises. It’s therefore a good idea to test materialized views carefully, especially when joins are present.
We hope you have enjoyed this article. Please contact us at info@altinity.com if you need support with ClickHouse for your applications that use materialized views and joins. We will be glad to help!
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.
Robert,
Does ClickHouse pin the inner tables (user/price) in memory or does it query and rehash the table contents after every insert into download? It seems like the inner tables would be pinned if you used “engine = Dictionary” but that isn’t how you defined them so I’m curious about the performance implications.
Hi Jay, as you inferred the tables won’t be pinned. I chose normal joins to keep the samples simple. If you have constant inserts and few changes on the dimensions dictionaries sound like a great approach. Given features like dictionary query rewriting in 20.4 + ssd_cache in 20.5 I would expect more use of dictionaries in this type of situation.
Is there any way to create a materialized view by joining 2 streamings tables? There’s some delay between 2 tables, is there any tip to handle watermark? I mean wait data to be available to join.
Not directly. But you can implement ‘join’-like logic inside the target table with engine=AggregatingMergeTree.
Smth like
CREATE MATERIALIZED VIEW a_mv TO joined_a_b AS
SELECT
common_col,
argMaxState(col1,ts) as a_col1_state,
argMaxState(col2,ts) as a_col2_state,
argMaxState(null,ts) as b_col1_state,
argMaxState(null,ts) as b_col2_state
FROM a;
CREATE MATERIALIZED VIEW b_mv TO joined_a_b AS
SELECT
common_col,
argMaxState(null,ts) as a_col1_state,
argMaxState(null,ts) as a_col2_state,
argMaxState(col1,ts) as b_col1_state,
argMaxState(col2,ts) as b_col2_state
FROM b;
Hello, is there a way to join a table a second time to get all the data for the table, and not just what we just inserted? thanks