Altinity.Cloud Launches Managed Iceberg with Antalya Compute Swarms

The era of real-time data lakes has arrived. Today we’re proud to announce two new Altinity.Cloud features that enable users to combine sub-second ClickHouse® performance with the infinite scalability of Apache Iceberg storage. Managed Iceberg catalogs enable convenient access to Iceberg tables on cheap, infinitely scalable object storage. Compute swarms dramatically speed up queries on Parquet data stored in Iceberg tables, Apache Hive, and plain S3 files.
The new features are just the first of many emerging from Project Antalya, our project to eliminate the trade-offs between real-time analytic database performance and data lake scalability. Future releases will add AWS S3 table buckets, tiered Parquet storage, and many other features. It’s part of our plan to help customers build analytic systems not just for today but for the next decade.
Managed Iceberg catalogs and compute swarms are in preview and will move to production shortly. They are limited to AWS environments for now. You can contact Altinity support to enable both features in any environment and get credits to try them out. Once enabled, customers can access capabilities with a couple of clicks in the Altinity.Cloud UI. New users can launch a trial to get access.
Towards Ubiquitous, Real-Time Data Lakes with Cloud Ease-of-Use
Data growth is a critical problem for open source ClickHouse users. Storage is now the dominant cost in use cases ranging from financial market analytics to observability. Compute costs have also grown because ClickHouse forces over-provisioning of resources in large clusters to ensure performance for diverse workloads. The demand for AI access adds additional workloads and further exacerbates compute contention. Apache Iceberg theoretically offers a way forward: low-cost, high-volume storage that supports rapid compute scaling and simultaneous access to a single copy of data from many applications. The problem is integrating and managing the parts.
Altinity.Cloud is opening the door to a new architecture for real-time analytics that combines the performance of ClickHouse with the proven storage management and flexible compute access of Apache Iceberg tables. But we’re doing more than delivering real-time data lakes with cloud management. We also are giving our users the freedom to operate anywhere: from traditional SaaS model operation in the Altinity cloud account to Bring-Your-Own-Cloud models in user cloud accounts to self-managed, on-prem environments. Altinity.Cloud can now bring the power of real-time data lakes to all of them.
In doing so we’re building on our proven architecture of a centralized cloud management plane connected to decentralized data planes that operate anywhere Kubernetes runs.
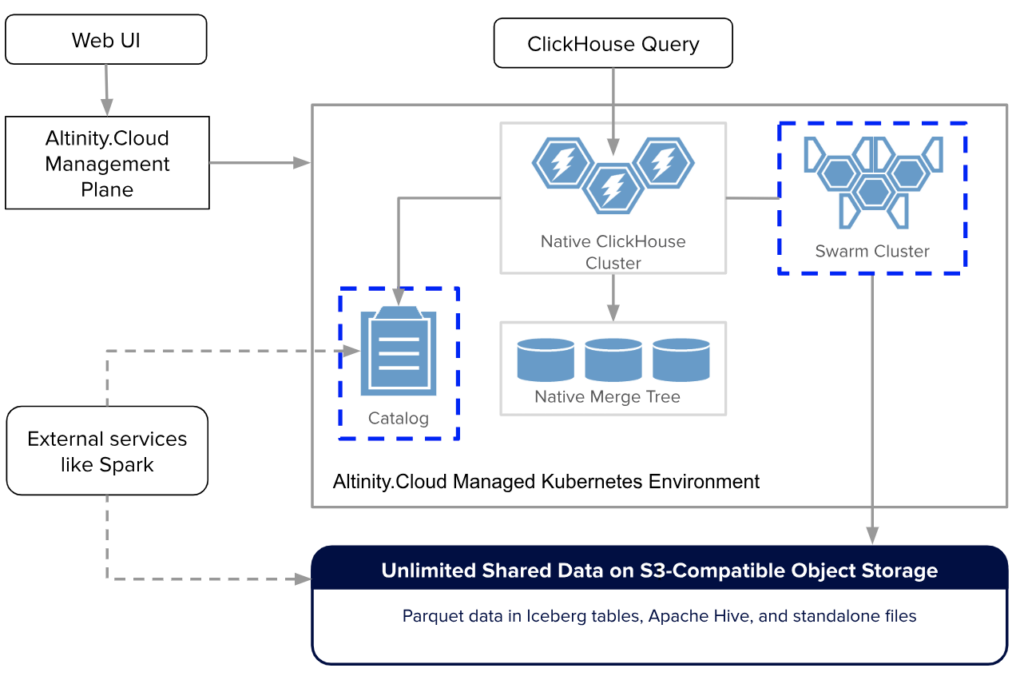
This architecture extends open source ClickHouse and leverages ecosystem tools like the Altinity Operator that are already used by tens of thousands of installations. The new additions–Iceberg catalogs and compute swarms – are fully managed services that deploy easily in any existing Altinity.Cloud environment. Like all software we manage in Altinity.Cloud, they are 100% open source with Apache 2.0 licenses. This upholds our guarantee that all building blocks of analytic applications will remain open.
Compute Swarms
Compute swarms deliver a breakthrough in the economics of compute for analytic systems. They allow you to add stateless ClickHouse compute nodes to scan Parquet data stored in Apache Iceberg, Hive, or plain S3 files. Swarms can scale up or down easily, and, as we showed in an earlier post, match or even exceed the query performance of ClickHouse MergeTree. Swarms thus enable users to choose storage based on properties other than performance, for example ease of changing data or ability to scale.
There are two steps to enable compute swarms. First, enable swarm access for the existing ClickHouse cluster using Cluster->Actions->Enable Swarms. This step will apply the necessary configuration and restart ClickHouse. Second, launch the swarm cluster itself using the button on the clusters’ dashboard.

Since compute swarms are stateless, they can also use spot instances to reduce the cost. You can configure spot instances when defining Node Types.
Important note: In order to run swarm queries from your primary ClickHouse cluster, you need to use an Altinity Antalya build for ClickHouse. Altinity Antalya builds are fully open source and 100% compatible with corresponding upstream versions. They have additional features for better Iceberg and swarm support. See the feature matrix for more detail. Altinity Antalya builds are leading edge builds, which means they prioritize rapid features rather than stability. Please consult with Altinity Support before upgrading production applications.
Compute swarms transform queries on any Parquet data stored in S3-compatible storage, not just those files stored in Iceberg tables. Consider them in the following cases.
- High-volume analytical workloads where you need both performance and cost efficiency
- Variable demand scenarios that benefit from scaling compute up and down
- Historical data analysis requiring occasional fast access to massive datasets
- Environments where spot instances can reduce costs
Managed Iceberg Catalogs
Catalogs hold the description of tables in open formats like Apache Iceberg. They are a key part of the procedures that applications use to locate, read, and change table data. Managed Iceberg catalogs in Altinity.Cloud provide an easy way to set up a catalog for Iceberg tables, which in turn enables you to set up real-time data lakes in any location.
It’s easy to enable an Iceberg catalog for any Altinity.Cloud environment running on AWS. Just navigate to the environment dashboard page and click on the Iceberg Catalog link. Once enabled, you will see access credentials that can be used by external clients.
Apache Iceberg shares many characteristics with ClickHouse MergeTree. Iceberg is fully open and vendor neutral. It also includes a built-in catalog specification, known as an Iceberg REST catalog. ClickHouse can connect to the catalog using a specialized form of the CREATE DATABASE command. At that point the tables managed by the catalog appear as a normal database and are available for SQL queries. This works quite well because of the similarity between Iceberg and MergeTree tables.
Unlike MergeTree tables, however, the Iceberg catalog can be used both by ClickHouse and external systems. This is one of the main benefits of using Iceberg in the first place and allows a wide spectrum of integrations, where different applications share the data. In order to use the catalog from ClickHouse in Altinity.Cloud, navigate to “Cluster->Configure->Data Lake Catalog”. That will list the available catalog options, including the Altinity.Cloud managed REST catalog. Once selected, it will automatically create a database in ClickHouse cluster that connects to the catalog.
Of course, the newly created catalog is empty. ClickHouse can not write data to Iceberg yet. You will need to use external tools such as Apache Spark or PyIceberg, or Altinity ice for that purpose. We are working on enabling writes, which will be available soon.
Managed Iceberg catalogs are only supported in AWS so far. Please reach out to us if you need them in other clouds.
What’s Next
Today’s launch is just the beginning of a new approach to analytics infrastructure. With managed Iceberg and compute swarms, Altinity is solving the integration complexity that has kept real-time data lakes at the idea stage for many organizations. You can now start to design production systems that help your organizations gain differentiation from fast insights on large datasets. The key is managed, real-time data lakes that combine the strengths of ClickHouse and Iceberg in any location.
The next releases will include managing multiple catalogs in the environment as well as AWS S3 Tables integration. We also keep working on adding more features into ClickHouse itself for better performance and Iceberg compatibility. Lastly, we’re actively working on adding support for writing data into Iceberg. Stay tuned and reach out to us if you want to learn more about how to apply these capabilities to your use cases.
Ready to build real-time data lakes? Contact Altinity support to enable preview features, receive testing credits, and start your evaluation. Don’t have an account yet? Start a trial today!
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.