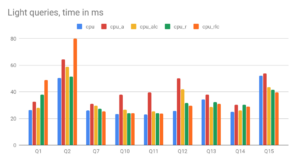
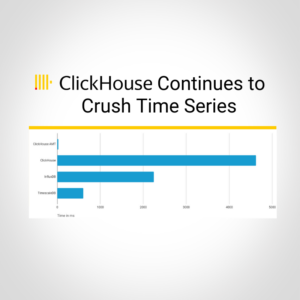
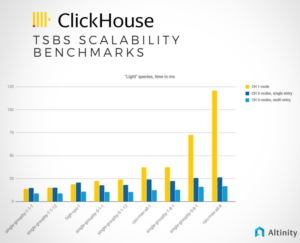
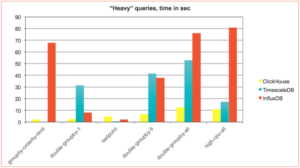
Harnessing the Power of ClickHouse® Arrays – Part 3
This final article completes our tour of array capabilities. We’ll survey functions for array map and reduce operations, demonstrating behavior and commenting on performance. This is an opportunity to dig further into lambdas, which are critical for using arrays effectively.