Database on Fire: Reflections on Embedding ClickHouse® in Firebolt

There’s no better place to learn about databases on the web than the awesome CMU Database Group YouTube channel maintained by Andy Pavlo. Fall 2021 was no exception with the Vaccination Database Talks, Second Dose series. One of the talks was especially relevant for ClickHouse users: Ben Wagner presenting How We Built Firebolt.
Here’s why: Firebolt embedded ClickHouse as their query engine!
Ben’s talk explains what Firebolt did and also digs deeply into the internals. He’s a query engineer at Firebolt, thus especially well-qualified for this presentation. The talk is so good that it’s worth a review in the Altinity blog. I’ll cover what Firebolt is up to, then add some thoughts on what it means for ClickHouse as well as analytic database users in general. There are useful lessons in both areas.
What is Firebolt doing?
Firebolt is a cloud SQL data warehouse that is picking up the gauntlet laid down by Snowflake and BigQuery. Unlike these databases, though, Firebolt is particularly focused on analytics for customer-facing applications like gaming and digital marketing where customers need to scan a lot of data and don’t want to wait for it. Ben framed the goals as follows:
- Low latency
- Predictable latency
- High QPS and concurrency
Ben made the point that this is a new kind of workload, especially for cloud data warehouses. The formulation is familiar to any experienced user of ClickHouse (or Druid or Pinot for that matter). The interesting question–of course–is how to achieve it in a way that continues to work as the amount of stored data scales. Most of the talk focused on that problem.
Firebolt splits compute and storage in a way that is at first glance similar to Snowflake. Here’s an adapted version of the architecture that Ben showed in the presentation.
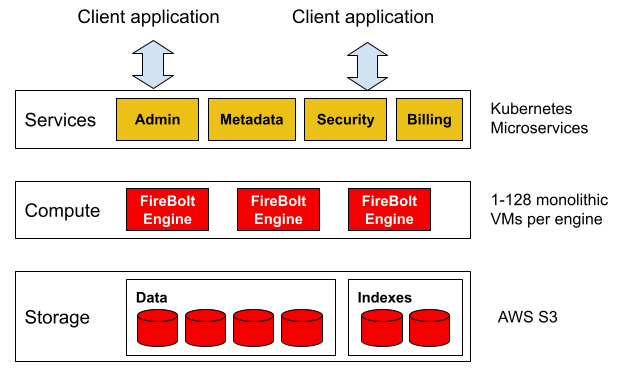
Starting at the bottom, the storage layer is in S3. It holds files for SQL table data as well as indexes. The next layer up is compute, which consists of “Firebolt Engines.” These are groups of VMs that function like Snowflake virtual warehouses. Multiple engines can feed off the same underlying data in the storage layer while preserving complete isolation between different use cases, such as ad hoc query or batch reports. Finally, the top level is various microservices to make the bottom two work. The most important service is metadata, which tracks SQL schema, authorization constructs like users or roles, and statistics, to name a few.
So where is ClickHouse? It’s hiding in the Firebolt Engine VMs. Here’s a more detailed picture to help show where it lives, again adapted from Ben’s diagrams.
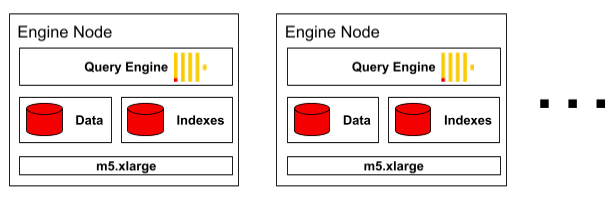
Firebolt uses a forked ClickHouse as the runtime query engine. Ben stated they chose it because it’s the fastest open source query engine. What they embedded is basically query execution on MergeTree with a number of important changes. Before explaining the alterations Ben included a great description of MergeTree. If you don’t know how MergeTree works it is worth a listen. Digging into Ben’s description of the implementation, three points stand out.
Buffering Data
Firebolt uses many of the key features of MergeTee, including the column format, table partitioning, sparse primary key indexes, secondary skip indexes, codecs, and compression. They also made a number of changes like adding an extra index type, another codec, and altering the file format. The most important alteration by far is adding a multi-layer buffer cache.
MergeTree accesses data by spawning a bunch of hardware threads that race down columns of the fact table. This is still not especially fast if the column files are stored in S3. (It’s not totally slow either, as we’ve shown on this blog, but there’s still work to be done) Firebolt therefore added a multi-layer cache that pulls data in from S3 and deposits it on fast, local SSD. They added a couple of clever optimizations in the process.
The first is to cache blocks of granules instead of complete files, which means it pulls in only the blocks required for particular queries instead of entire column files. The second is to allow different blocks from the same column file to be cached on different nodes. This is harder than it sounds. It requires a way to ensure low-level cache coherency across nodes in the FireBolt Engine or you will get different results depending on the state of the caches. Ben talked about how Firebolt uses an injective mapping to ensure granules map to one and only one cache. The talk did not provide the details about how this works. It is fast, which means it minimizes consensus between nodes.
Ben walked through an example to illustrate how the compute and storage layer communicate via the cache to process a local query. Kudos again for nice examples and a clear explanation. To repeat, this is very different from ClickHouse, which runs parallel scans down tables and depends on the OS buffer cache to speed up access to data.
Distributed Query Execution
ClickHouse implements distributed query using Distributed table engine. Distributed tables are like an umbrella table that knows the location of table shards and replicas within each shard. Queries on distributed tables use a form of distributed aggregation analogous to running map-reduce over local tables on each node. Processing of joins between distributed tables is controlled by variables like distributed_product_mode, which requires users to make explicit choices about location of data.
The Firebolt query model is completely different. Incoming queries (written in PostgreSQL dialect) are parsed and passed to a distributed query planner. The planner chooses execution plans based largely on fixed rules with some cost-based optimization. Join order is based on statistics, hence in the latter category.
Firebolt also has a shuffle operator, which is designed to move data quickly between query stages to handle joins efficiently. It sounds as if this is a work in progress that shares the same motivations as the shuffle process in BigQuery. The idea is to redistribute data in successive processing steps so that joins are localized wherever possible. This works without any input from users, which is quite different from ClickHouse as it exists today.
Once again, Ben provided an instructive example of distributed query execution with a nice diagram in the talk.
ClickHouse Features That Are Left Out
That would be pretty much everything else. I’ll just give a few prominent examples.
- Query language – Firebolt implements the PostgreSQL SQL dialect and has its own parser.
- Query planning – As discussed above, this is a completely different model. The query planner is adapted from Hyrise, an academic system that is self-contained and easy to integrate with the rest of the C++ system.
- Metadata management – Firebolt has its own metadata system that manages schema definitions, security, and transactions. It’s completely different from anything in ClickHouse.
- Ecosystem integration – Table Engines to integrate with Kafka and MySQL, table functions, and all that fun stuff are left out. Firebolt has its own integrations with a host of ecosystem tools.
Other Interesting Points
Firebolt runs the services layer entirely on Kubernetes. The Compute layer (i.e., the Firebolt Engines) are VMs provisioned using Terraform. From Ben’s description it sounds as if the team is reconsidering this choice and moving the compute layer to Kubernetes as well. This will allow Firebolt to take advantage of Kubernetes resource management for all layers, which is an increasingly standard design in cloud services. We have made the same choice in Altinity.Cloud.
Ben was reluctant to talk about performance but mentioned that query response tends to be in the “dozens of milliseconds.” We’ll have to wait for somebody else to publish query benchmarks to say more. Meanwhile, the discussion of joins was enlightening. Joins on distributed data require multi-stage query execution and may move large amounts of data between stages. ClickHouse would presumably need a shuffle operation as well to handle joins between large, sharded tables automatically for users.
What does the Firebolt implementation mean for ClickHouse?
In a feature sense, not much. The Firebolt code is a hard fork and it’s doubtful any of the changes will ever be contributed back to ClickHouse. Over time ClickHouse code will progressively lose its identity and be just another part of the Firebolt codebase. Firebolt is not the first company to fork ClickHouse code to create a new data warehouse offering. Hydrolix did this, as did ByteHouse.
The Firebolt integration does bring up an interesting point. Does ClickHouse have to use object storage to scale in the cloud? The Snowflake architectural pattern of separate compute clusters on object storage has been very influential. Ben’s talk shows that this pattern has tradeoffs. The biggest is a hard dependency on object storage that undermines one of the core ClickHouse strengths: ability to run anywhere, not just inside a public cloud service.
So what are the alternatives? Is there a way to get equal flexibility with attached storage?
The answer is yes. There are several options. It’s worth considering at least two of them.
One obvious approach is to split compute and storage within ClickHouse itself. Systems like Amazon Aurora split storage out into a separate service with its own nodes. Aurora’s experience demonstrates such a design works and can be extremely efficient. Interestingly, Hydrolix does something along these lines. Hydrolix replaces the MergeTree storage engine with an optimized service backed by object storage, but it could conceivably use something else, of course. ByteHouse takes a similar approach. Both are proprietary forks that cannot be easily integrated back to ClickHouse.
Another obvious approach is to stick with the traditional features of ClickHouse and see how to make them better. You can already create something like Firebolt Engines using Distributed Table Engine and ReplicatedMergeTree Engine. Here’s a setup that uses Distributed tables to create two separate pools of replicas sharded 3 ways.
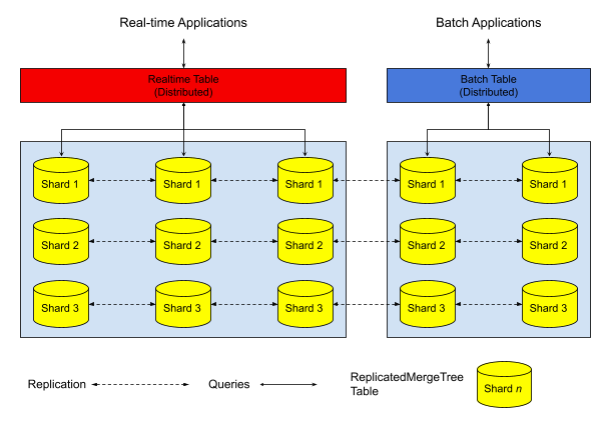
Anyone who knows ClickHouse can set this up. The real problem is scaling up and down over time, because ClickHouse does not rebalance data across shards automatically. If you add a new shard, ClickHouse does not copy data to it automatically from other shards. Worse, if you drop a shard ClickHouse does not automatically redistribute data back to the remaining shards and you lose your data. Requests to add rebalancing therefore pop up regularly. There have been several proposals to address it.
One of the most interesting proposals has been on the table since 2018. It’s called cloud tables. The idea is to split ClickHouse MergeTree table data into ranges that can be spread across multiple servers. The goal is similar to consistent hashing in DynamoDB and Cassandra but with more control over the way keys are divided to avoid performance bottlenecks from creating too many parts. Cloud tables would have some other nice properties, such as spreading out ranges in such a way that large queries can distribute over every replica instead of one replica in each shard.
I think we can learn from Ben’s description of Firebolt and suggest a couple of improvements to cloud tables.
- Add the ability to subdivide cloud table data into resource pools for queries. This would enable users to separate ingest, real-time analytics, and batch analytics, for example. The effect would be similar to Firebolt Engines. This could work off the same mechanism that would be needed force replicas to particular availability zones. (Which also has to be supported.)
- Think about how to correlate ranges between different tables to make distributed joins more efficient. The original cloud tables proposal lightly touches this issue. Also, ClickHouse placing data automatically has an interesting consequence. It will likely force the query planner to start making decisions about join order, because users will no longer be able to reason about join behavior for themselves. Ben’s Firebolt distributed query example illustrates the issues around joins and the cloud tables proposal acknowledges them.
Cloud tables seem like a great idea that would help make ClickHouse dominant in every operating environment. But they are not the only possibility.
The ClickHouse community has many other ideas about how to improve storage that also build on existing features. The ClickHouse 2022 Roadmap on Github laid out by Alexey Milovidov is full of them. The section on “Separation of Storage and Compute” has the following items:
- Parallel reading from replicas.
- Dynamic cluster configuration with service discovery.
- Caching of data from object storage.
- Simplification of ReplicatedMergeTree.
- Shared metadata storage.
I added pull requests where I could find them, so you can look up the state of the change and who is doing it. It’s clear that ClickHouse contributors will introduce some interesting new tricks in 2022.
What does the Firebolt implementation mean for analytic database users in general?
Well, it’s pretty clear more data warehouse choices are on the way.
In the early 2000s a number of proprietary analytic databases started by forking the PostgreSQL code. Greenplum, Netezza, and Truviso are examples. I doubt this will happen in the future. As Ben said, ClickHouse has the fastest open source engine around, so it’s now natural to fork ClickHouse instead. We will certainly see more products that leverage ClickHouse to create interesting proprietary as well as open source solutions. The Firebolt fork is just additional validation that ClickHouse is the standard for high performance analytics.
And it’s not just that there will be more solutions based on ClickHouse directly. The other thing that Ben’s talk shows is that companies like Firebolt are framing the real-time analytic problem the same way as pioneers like ClickHouse and Druid. Exactly as I mentioned above, to deliver:
- Low latency
- Predictable latency
- High QPS and concurrency
As we’ve pointed out before on this blog, there will be a number of cloud database services that deliver roughly comparable performance for real-time analytics. This goes beyond ClickHouse look-alikes. I predict we’ll also see responses from existing services like Amazon Redshift. The victors will win on developer friendliness, cost-efficiency, and portability across environments. ClickHouse is of course well-positioned in all of these areas.
Much as I enjoyed Ben’s talk, I do see a missed opportunity in the choice to use the PostgreSQL SQL dialect. ClickHouse SQL is quite user-friendly, which is partly a heritage of borrowing syntax from MySQL. More importantly, the ClickHouse SQL dialect is creative in a way that improves developer experience and evolves the language, echoing the major productivity advances in programming languages.
ClickHouse has dozens of useful extensions ranging from tuple return values from IN operators to functional programming on arrays to a cornucopia of table and database engines. It’s pretty obvious by now that SQL will not be replaced any time soon. The only way to make it better is to extend it. ClickHouse is doing that now. This is a good reason for new forks to include *all* of ClickHouse, not just specific parts like MergeTree.
Parting Words
Overall Ben’s talk is one of the most worthwhile database presentations I have seen in a while. The path that Firebolt has taken to utilize ClickHouse as its query engine offers lessons to us in the ClickHouse community. We owe Ben as well as the CMU Database Group a vote of thanks for sharing the information in such a transparent fashion. I hope readers find it inspires them to help make ClickHouse better than it is already.
One final note: thanks to Ben for the shoutout to Altinity and our talk on ClickHouse in the same CMU Database Group series. Here is a link if you have not seen it. And if you are developing a new database product I definitely recommend tracking down Andy Pavlo and getting on the schedule. It’s a great way to share database advances in front of an outstanding audience.
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.