Reducing Clickhouse Storage Cost with the LowCardinality Type – Lessons from an Instana Engineer

May 21, 2020

At Instana we are operating our Clickhouse clusters on m5.12xlarge AWS EC2 instances and similar sized custom build Google Cloud instances. The biggest cost driver however is not the size of the instance, but the EBS volumes / persistent SSDs that are attached to the instances. Every single one of our 12TB volumes costs $1320 per month in AWS and $2,040 per month in Google Cloud.
With write IOPS spiking to thousands per second, we, unfortunately, are not able to use cheaper ST1 volumes as we did previously for other instances.
Clickhouse is an amazingly fast analytics database that shines on high volume inserts combined with complex analytics queries which Instana uses to answer all kinds of questions about traces, like “Show me all traces that had an error, that were executed on one of these specific services. Also show me the latency distribution percentiles for each of the groups based on a particular parameter”.
Oftentimes the performance of these queries is directly proportional to the amount of data processed. So reducing the amount of stored data, would not only reduce our cost, but also improve the performance.
Compression
Of course we are already compressing our data. Clickhouse supports lz4 and zstd compression, and while zstd is a bit slower and resource intensive, the fact that Clickhouse needs to scan less data makes up for it. Also we use gzip compression for sending data into Clickhouse, to reduce cross-AZ traffic, like the Kafka cross-AZ traffic optimization we blogged about earlier, where we reduced cross-AZ traffic with configuration. For the type of data we send, we calculated that a level 2-3 compression is already sufficient and it is not worth doing higher levels.
Introducing LowCardinality
We have been running on the same schema for a year now and collected several changes we want to do. However a schema migration on billions of records is nothing that you want to do all the time. When we came across the LowCardinality data type the first time, it seemed like nothing we could use. We assumed that our data is just not homogeneous enough to be able to use it. But when looking at it recently again, it turns out we were very wrong. The name LowCardinality is slightly misleading. It actually can be understood as a dictionary. And according to our tests, it still performs better and is faster even when the column contains millions of different values.
So a new schema was created, and alongside a migration utility. We had several ideas for how to do the migration, some of them with a higher operational complexity but no downtime, others are faster and easier but do require downtime. In the end Clickhouse is our biggest database and has an incredibly high rate of updates every second. Luckily, we never update old data!
We ended up implementing a migration utility that can do everything: Online live migration, stop the world batch migration, easy stop and restart and much more. This also enables our self-hosted on-premises customers to choose what approach works best for them.
Results
The migration took several weeks to complete. When it now came to evaluating the overall result, we were happy to see that all the load tests and calculations we had done hold true for the full production dataset.
The size on disk went down by almost 50%:
SELECT
table,
formatReadableSize(SUM(bytes_on_disk))
FROM system.parts
WHERE (active = 1) AND ((table = 'calls_v2') OR (table = 'calls_v3'))
GROUP BY table
┌─table────┬─formatReadableSize(SUM(bytes_on_disk))─┐
│ calls_v3 │ 1.85 TiB │
│ calls_v2 │ 3.90 TiB │
└─────────┴─────────────────────────────────────────┘
And the performance improved almost by 2x!
Here two screenshots from our Instana self monitoring. They ironically show trace analytics screens which looks up the performance of calls to our “clickhouse” service for a specific customer. This customer is running in our US datacenter and does nightly reports using our REST API, and as such causes a lot of processing intensive Clickhouse calls. We performed the go-live of reading from the new schema by our European team in the morning at 9:14.
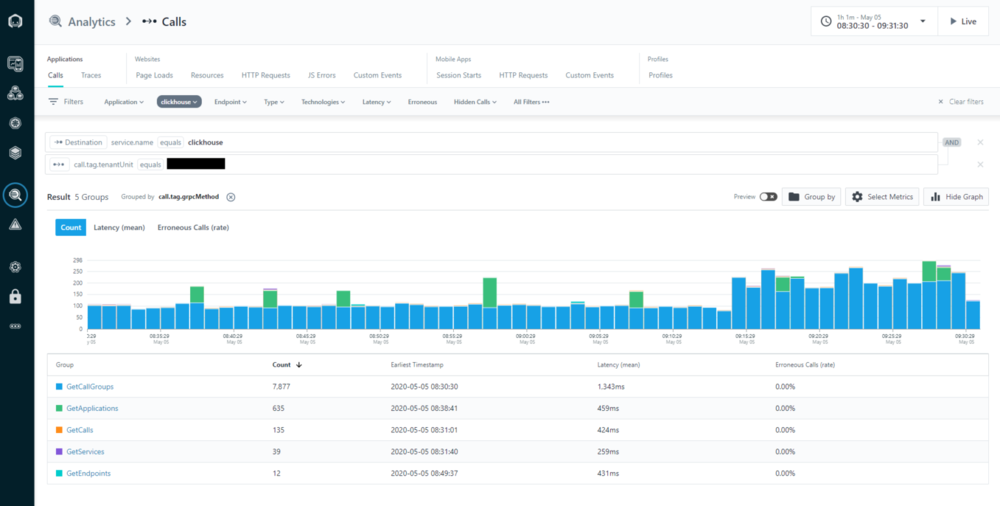
Immediately the number of calls more than doubled. Why is that? Well if we do not look at the count, but at the mean latency, it is pretty clear what happened:
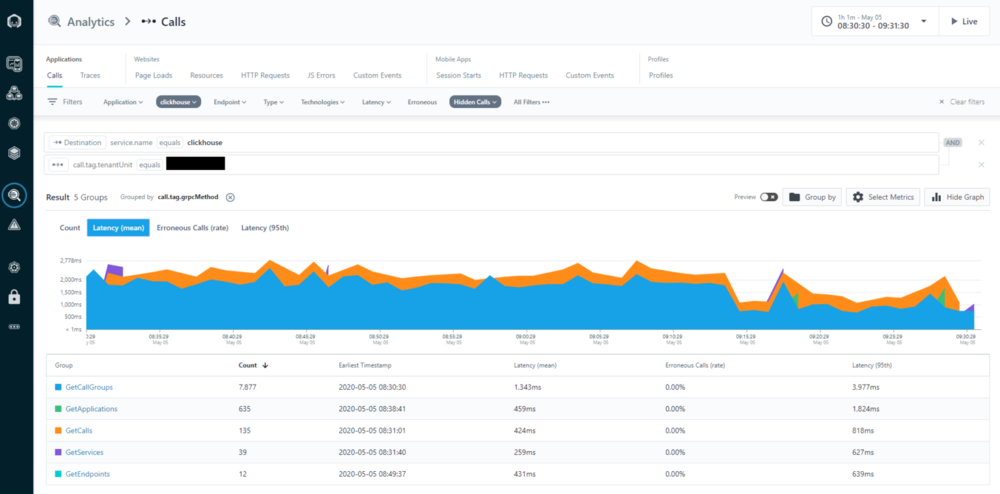
All those blue “GetCallGroups” queries are now twice as fast. And apparently our customer uses some kind of concurrency limiting, which now is able to do double the amount of calls in the same time.
We also see the same improvement in our own End User Monitoring. Since end-users tend to do less complex calls via the UI than via the API, the mean did not show an improvement that is easily recognizable on screenshots, but the higher percentiles like the 95th percentile did improve significantly:
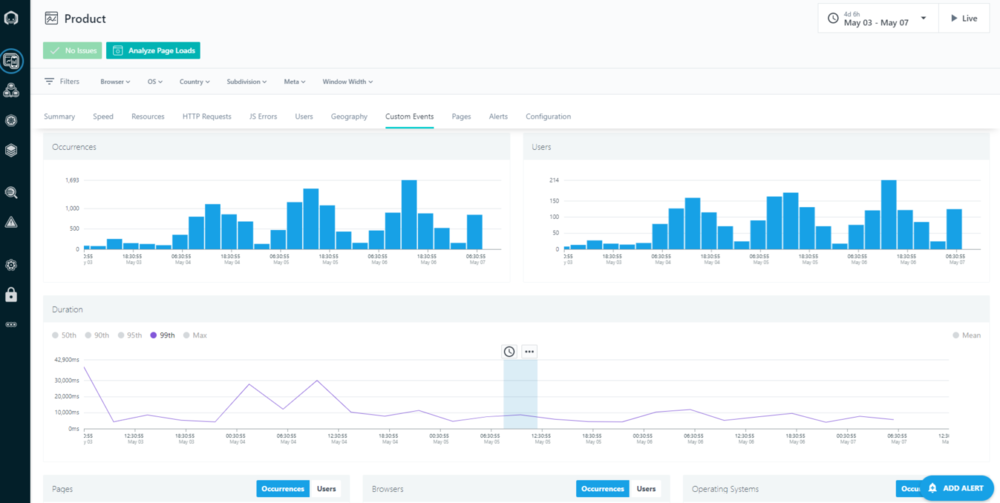
So not only did we cut our cost for storage roughly in half, we made the product twice as fast. Truly a Win-Win.
We welcome guest articles! This article was originally published here: https://www.instana.com/blog/reducing-clickhouse-storage-cost-with-the-low-cardinality-type-lessons-from-an-instana-engineer/
Instana is a SaaS Application Performance Monitoring solution provider for microservice and Cloud-Native applications. Clickhouse plays a big part in the company’s ability to deliver value over time. It’s also a big part of Instana operations. Thanks to Yoann for a great post.
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.
Nice write up. You didnt explain how many columns you chose to change, did you change them all, if not what were the factors to use low cardinality?