New Encodings to Improve ClickHouse® Efficiency


Modern analytical databases would not exist without efficient data compression. Storage gets cheaper and more performant, but data sizes typically grow even faster. Moore’s Law for big data outperforms its analogy in hardware. In our blog we already wrote about ClickHouse compression (https://altinity.com/blog/2017/11/21/compression-in-clickhouse) and Low Cardinality data type wrapper (https://altinity.com/blog/2019/3/27/low-cardinality). In this article we will describe and test the most advanced ClickHouse encodings, which especially shine for time series data. We are proud that some of those encodings have been contributed to ClickHouse by Altinity.
This article presents an early preview of new encoding functionality for ClickHouse release 19.11. As of the time of writing, release 19.11 is not yet available. In order to test new encodings ClickHouse can be built from source, or a testing build can be installed. We expect that ClickHouse release 19.11 should be available in public releases in a few weeks.
Encoding and Compression Overview
Encoding and compression are used for the same purpose — we use them in order to store data in a more compact way. They transform data differently, however. Encoding maps source data to a different (encoded) form, element by element. You can think of it as contiguous mathematical mapping. For example, dictionary encoding maps strings to dictionary indices. Encoding is aware of the data type being encoded. Compression on the other hand assumes some generic algorithm is used that compresses bytes, not data types.
For many years ClickHouse supported two compression algorithms: LZ4 (used by default) and ZSTD. Those algorithms sometimes have logic to apply encodings inside, but they are not aware of ClickHouse data types. Knowing the data type and the nature of the data allow us to encode data more efficiently. During the last several months ClickHouse syntax has been extended in order to accommodate column level encodings, and new encodings have been added to ClickHouse:
- Delta. Delta encoding stores the difference between consecutive values. The difference typically has smaller byte-size and cardinality, especially for sequences. It can be efficiently compressed later with LZ4 or ZSTD.
- DoubleDelta. With this encoding ClickHouse stores difference between consecutive deltas. It gives even better results for slowly changing sequences. To use an analogy from physics, Delta encodes speed, and DoubleDelta encodes acceleration.
- Gorilla. This one is inspired by a Facebook article some time ago [http://www.vldb.org/pvldb/vol8/p1816-teller.pdf], and nobody remembers the academic name of the algorithm anymore. Gorilla encoding is very efficient for values that does not change often. It is applicable both to float and integer data types.
- T64. This encoding is unique to ClickHouse. It calculates max and min values for the encoded range, and then strips the higher bits by transposing a 64-bit matrix (which is where the T64 name comes from). At the end we have a more compact bit representation of the same data. The encoding is universal for integer data types, and does not require any special properties from the data other than locality of values.
Encodings can be specified as a part of the column definition using the ‘Codec’ keyword. The example below defines DoubleDelta encoding for a column. Note, that it turns off default compression.
ts DateTime Codec(DoubleDelta) -- encoded but NOT compressed
In order to have both encoding and compression, codecs can be chained, as shown below:
ts DateTime Codec(DoubleDelta, LZ4) -- encoded AND compressed
Delta, DoubleDelta and Gorilla encodings can be found in many time series databases. Delta and DoubleDelta are traditionally used for timestamps, while Gorilla encoding is used for values. InfluxDB and Prometheus storage are good examples. As we demonstrated a few months ago [https://altinity.com/blog/clickhouse-for-time-series], ClickHouse competes well against InfluxDB in terms of performance, but was behind when efficiency of compression is concerned. Using new encodings will fix the gap. Let’s test them out!
Test Methodology
We are going to test encodings using several criteria:
- Efficiency of encoding without compression for different data types
- Efficiency of encoding with LZ4 and ZSTD compressions applied
- Efficiency of LZ4 and ZSTD compression applied to encoded data
We used 4 different generated datasets with 1,000,000 rows each that we store in different tables:
- Monotonic sequence of numbers with constant increments (codec_test1_seq).Sample data: 0,1000,2000,3000,4000,5000,6000,7000,8000,9000, …
- Monotonic sequence with random increment (codec_test2_mon).Sample data: 22,1072,2034,3076,4007,5094,6061,7074,8061,9058, …
- Constant sequence with random spikes (codec_test3_var).Sample data: 1825,1000,1000,1000,1000,1000,1000,1703,1000,1000, …
- Randomized set of values below 1B (codec_test4_rand).Sample data: 608745218, 167444263, 620949842, 956686395, 66062863, …
The first three datasets are typical for time series applications. The randomized set is the worst case scenario. Every dataset table has multiple columns that represent different combinations of data type, encoding and compression. We also store the unencoded column as a reference. That allows us to compare different combinations inside data sets and across data sets. To summarize, we test the following combinations:
- Int32, Int64 data types*
- None, Delta, DoubleDelta, Gorilla, T64 encodings
- None, LZ4, ZSTD compression**
- Originally we planned to test Float32 and Float64 with Gorilla encoding, but removed it to make the article more concise. You can still find the float data types and encoding combinations in scripts in the Appendix.
** It is possible to adjust compression level, but default compression levels were used.
Compression and encoding efficiency can be seen from ClickHouse system.columns table, which displays compressed and uncompressed size for each column as well as encodings and compressions that were applied to the column.
For those who are interested in detailed SQL examples, you can find scripts in the Appendix at the end of the article.
Encoding and Compression Efficiency Results: Integer types
When looking to results below, keep in mind the source data size: unencoded and uncompressed. It is 4,000,000 bytes for Int32 and 8,000,000 for Int64. We also include unencoded data size as a reference.
First let’s look at uncompressed data.
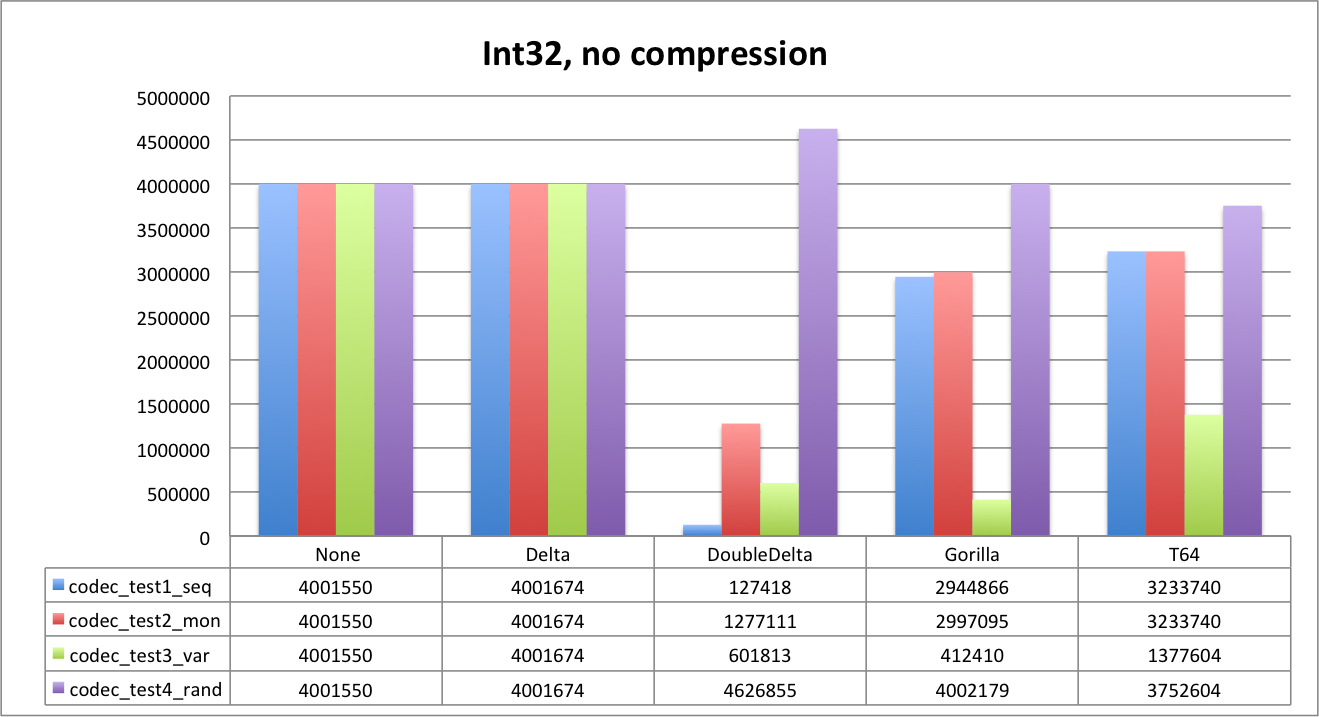
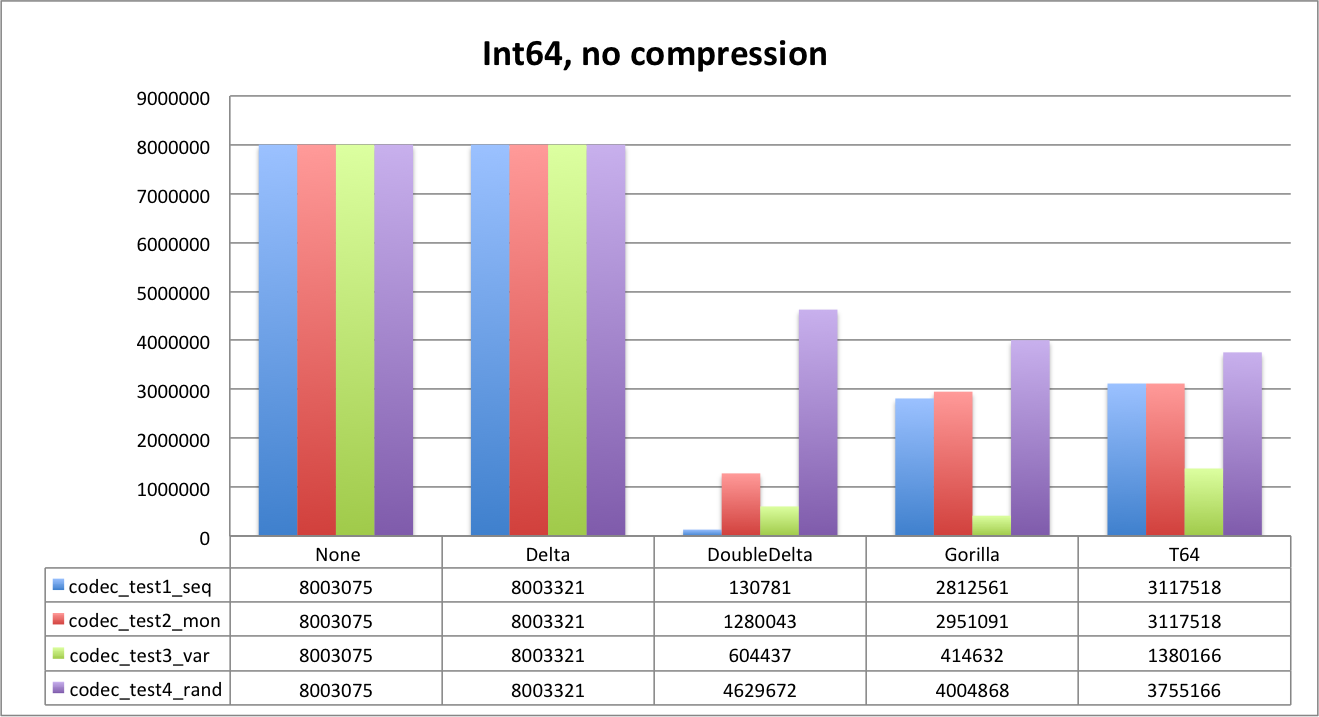
As you can see, Delta does not compress data at all, since default delta size is the same as data type. We will see that it will work better with LZ4. DoubleDelta is the best for uniform sequences and monotonic ones but not that good for random data.
It is also very interesting to see how Gorilla and T64 perform. Random data is the best example. Since we generated random values below 1B, data fits 30 bits. T64 is able to detect it and strip extra bits perfectly. You can clearly see it both for Int32 and Int64 — the data size is about the same, and is close to 3,750,000 bytes (1,000,000*30/8).
Gorilla is slightly worse on random dataset (32 bits), but it is fantastic for the ‘var’ dataset. ‘Gauge’ kind of data is the primary use case for such an encoding, though we were surprised by Gorilla performance on integer data types in general.
Next, let’s look at LZ4 compression.
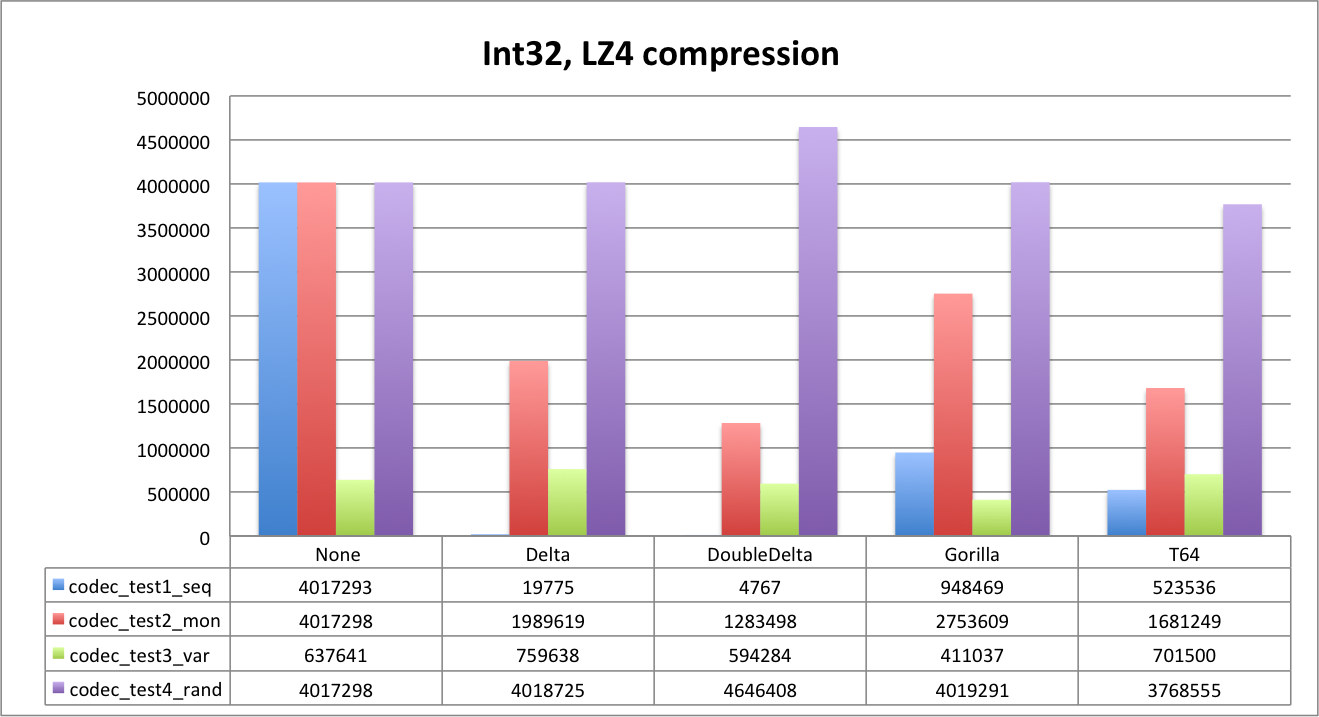
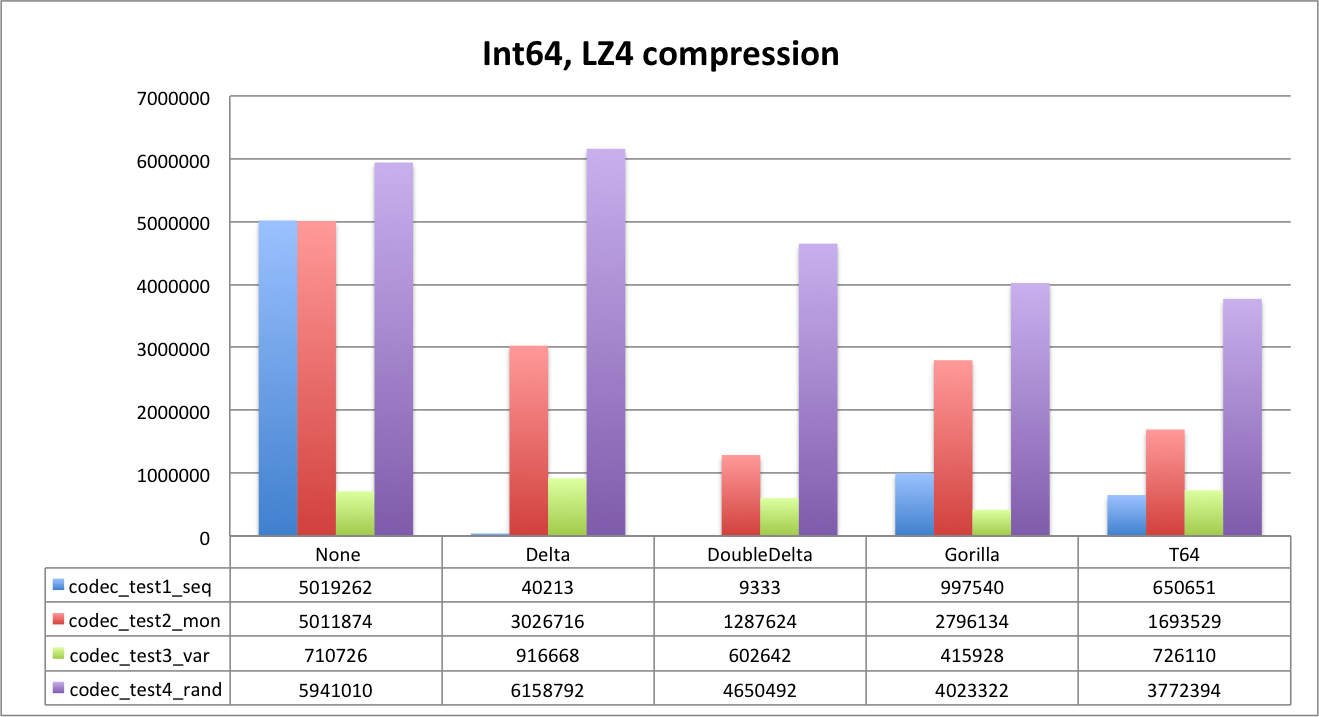
With LZ4 compression Delta encoding is already good for everything except random dataset. DoubleDelta evidently is the best for time series cases.
And now let’s look at ZSTD.
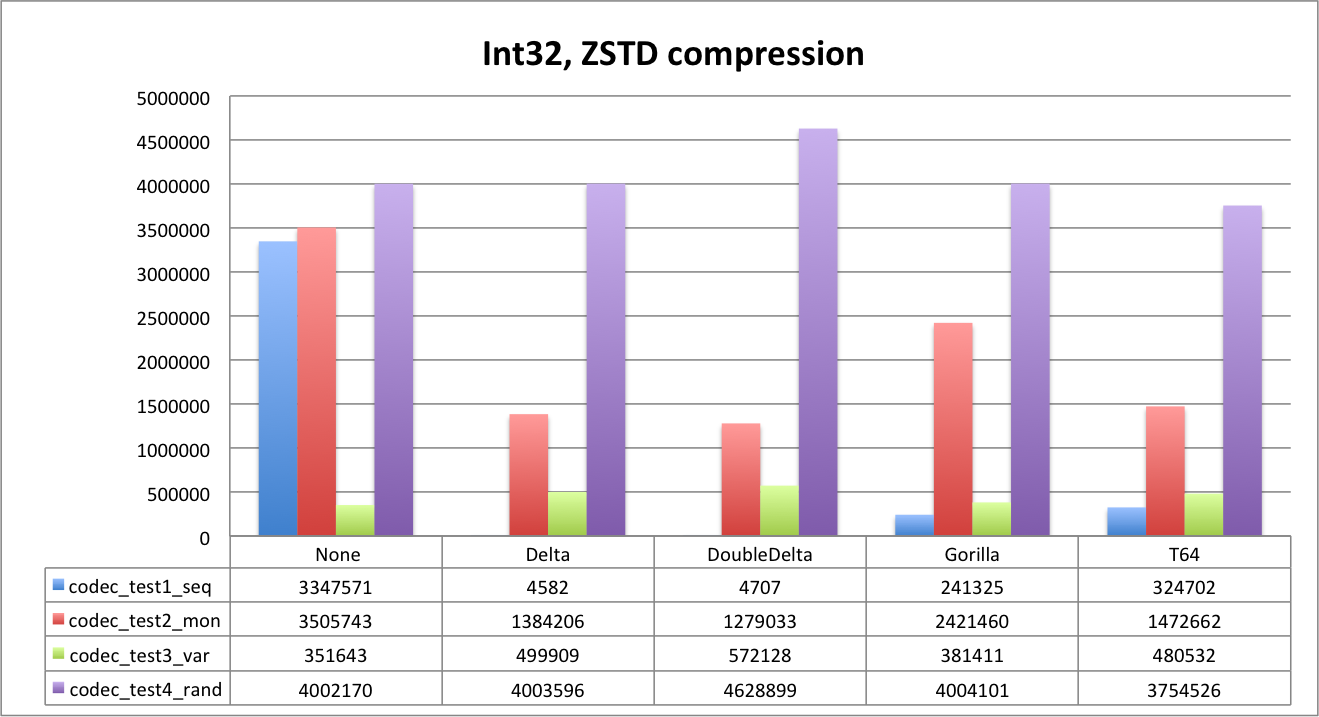
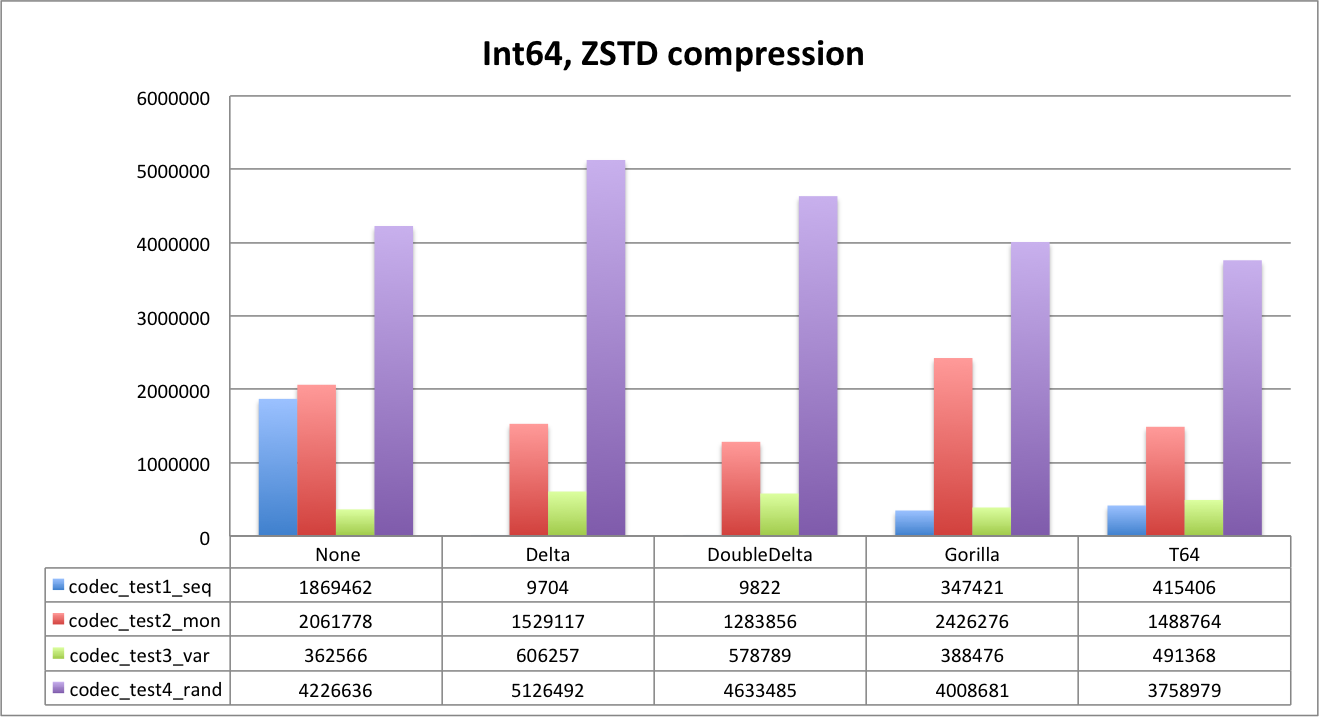
It’s interesting that ZSTD can compress Delta for sequences more efficiently than DoubleDelta. Compression ratio for sequences is impressive 1:800+ with both delta encodings and ZSTD. T64 is the best for random data again.
Let’s look at this from a different angle. For report below we combined all time series datasets in order to compare compression and encoding effects together.
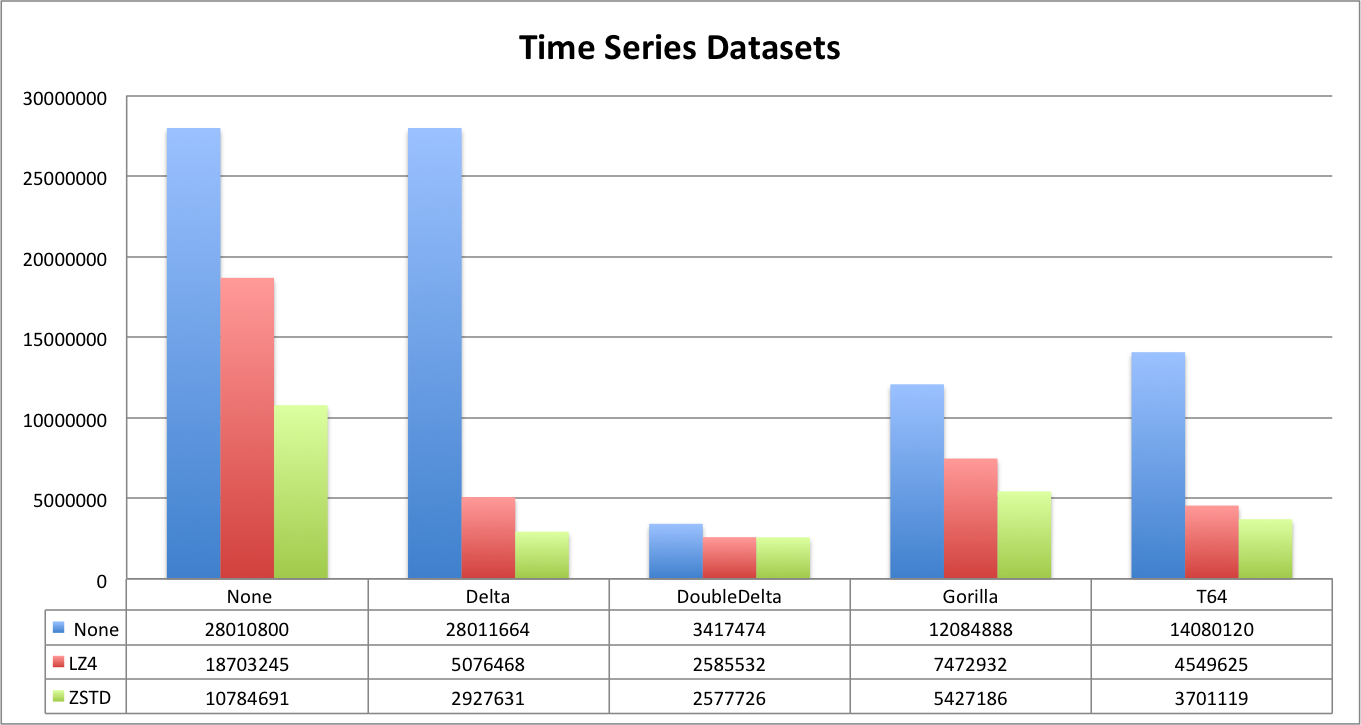
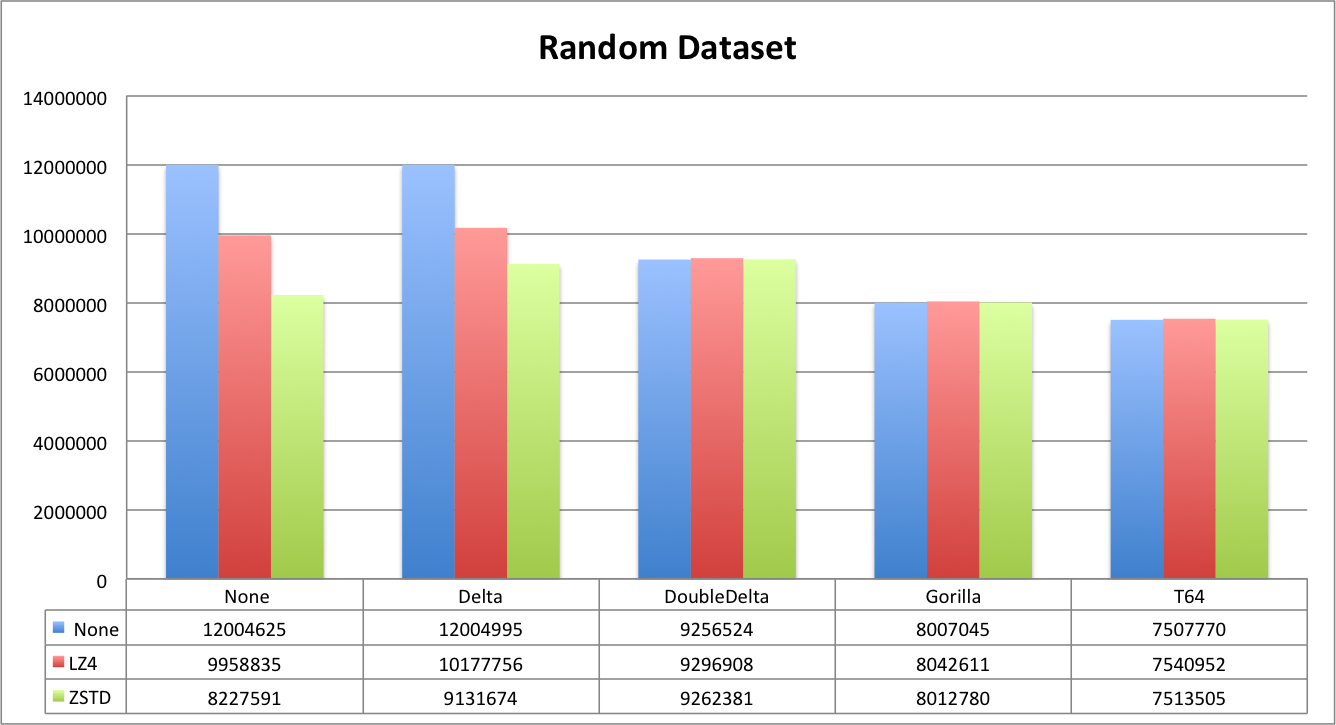
To summarize, Delta and DoubleDelta work well for time series specific data. DoubleDelta is very efficient with LZ4, so adding ZSTD does not improve it. T64 and Gorilla are great general purpose codecs that can be recommended for all cases where the data pattern is not known. Gorilla is better for time series, but T64 is more ‘compression-friendly’. Even if Gorilla can be more efficient initially, compression is more efficient with T64. But the difference is not that much. Note, however, that Gorilla can encode floats with the same efficiency, so for float values it is a no brainer.
Conclusion
ClickHouse codecs help a lot to improve general compression, reduce storage and increase performance due to less I/O. It is important to understand the nature of the data and choose the right codec. Delta encoding is the best to store time columns, DoubleDelta should compress very well for increasing counters, and Gorilla is the best for gauges. T64 can be used for integer data, provided you do not store random hashes. Using codes also allows you to stick with fast LZ4 and reduce CPU load when decompressing the data.
There is room for improvement left, however. In particular, it looks like DoubleDelta can be improved for Int32, a new version of the T64 codec has been added last week, and there is an article by VictoriaMetrics that claims significant improvement using modified Gorilla algorithm [https://medium.com/faun/victoriametrics-achieving-better-compression-for-time-series-data-than-gorilla-317bc1f95932]. We expect that even more efficient codecs will be available in ClickHouse over the next few months.
One might complain that this article lacks performance tests. Performance tests on synthetic data could be misleading. We are going to test the real effect using TSBS benchmarks. Stay tuned.
Appendix: Test Data Preparation
Below are scripts to repeat our benchmarks.
pre, code {
font-family: monospace, monospace;
font-size: 75%;
margin-left: 30px;
}
pre {
word-break: normal;
word-spacing: normal;
line-height: 1.5;
}
DROP TABLE IF EXISTS codec_test1_seq;
CREATE TABLE codec_test1_seq (
n Int32,
/* No compression */
n32 Int32 default n Codec(NONE),
n32_delta Int32 default n Codec(Delta),
n32_doubledelta Int32 default n Codec(DoubleDelta),
n32_t64 Int32 default n Codec(T64),
n32_gorilla Int32 default n Codec(Gorilla),
n64 Int64 default n Codec(NONE),
n64_delta Int64 default n Codec(Delta),
n64_doubledelta Int64 default n Codec(DoubleDelta),
n64_t64 Int64 default n Codec(T64),
n64_gorilla Int64 default n Codec(Gorilla),
f32 Float32 default n Codec(NONE),
f64 Float64 default n Codec(NONE),
f32_gorilla Float32 default n Codec(Gorilla),
f64_gorilla Float64 default n Codec(Gorilla),
/* LZ4 compression */
l_n32 Int32 default n Codec(LZ4),
l_n32_delta Int32 default n Codec(Delta, LZ4),
l_n32_doubledelta Int32 default n Codec(DoubleDelta, LZ4),
l_n32_t64 Int32 default n Codec(T64, LZ4),
l_n32_gorilla Int32 default n Codec(Gorilla, LZ4),
l_n64 Int64 default n Codec(LZ4),
l_n64_delta Int64 default n Codec(Delta, LZ4),
l_n64_doubledelta Int64 default n Codec(DoubleDelta, LZ4),
l_n64_t64 Int64 default n Codec(T64, LZ4),
l_n64_gorilla Int64 default n Codec(Gorilla, LZ4),
l_f32 Float32 default n Codec(LZ4),
l_f64 Float64 default n Codec(LZ4),
l_f32_gorilla Float32 default n Codec(Gorilla, LZ4),
l_f64_gorilla Float64 default n Codec(Gorilla, LZ4),
/* ZSTD compression */
z_n32 Int32 default n Codec(ZSTD),
z_n32_delta Int32 default n Codec(Delta, ZSTD),
z_n32_doubledelta Int32 default n Codec(DoubleDelta, ZSTD),
z_n32_t64 Int32 default n Codec(T64, ZSTD),
z_n32_gorilla Int32 default n Codec(Gorilla, ZSTD),
z_n64 Int64 default n Codec(ZSTD),
z_n64_delta Int64 default n Codec(Delta, ZSTD),
z_n64_doubledelta Int64 default n Codec(DoubleDelta, ZSTD),
z_n64_t64 Int64 default n Codec(T64, ZSTD),
z_n64_gorilla Int64 default n Codec(Gorilla, ZSTD),
z_f32 Float32 default n Codec(ZSTD),
z_f64 Float64 default n Codec(ZSTD),
z_f32_gorilla Float32 default n Codec(Gorilla, ZSTD),
z_f64_gorilla Float64 default n Codec(Gorilla, ZSTD)
) Engine = MergeTree
PARTITION BY tuple() ORDER BY tuple();
DROP TABLE IF EXISTS codec_test2_mon;
CREATE TABLE codec_test2_mon AS codec_test1_seq;
DROP TABLE IF EXISTS codec_test3_var;
CREATE TABLE codec_test3_var AS codec_test1_seq;
DROP TABLE IF EXISTS codec_test4_rand;
CREATE TABLE codec_test4_rand AS codec_test1_seq;
insert into codec_test1_seq (n)
select number*1000 from numbers(1000000) settings max_block_size=1000000;
insert into codec_test2_mon (n)
select number*1000+(rand()%100) from numbers(1000000) settings max_block_size=1000000;
insert into codec_test3_var (n)
select 1000 + (rand(1)%1000) * (rand(2)%10 = 0) from numbers(1000000) settings max_block_size=1000000;
insert into codec_test4_rand (n)
select rand()%(1000000*1000) from numbers(1000000) settings max_block_size=1000000;
/* sample rows */
select table, groupArray(n) samples from (
select 'codec_test1_seq' table, n from codec_test1_seq limit 10
union all
select 'codec_test2_mon' table, n from codec_test2_mon limit 10
union all
select 'codec_test3_var' table, n from codec_test3_var limit 10
union all
select 'codec_test4_rand' table, n from codec_test4_rand limit 10
)
group by table order by table;
/* validation. It is complicated because of mix of Int and Float types */
select arrayDistinct(avgForEach(CAST(replaceOne(replaceOne(toString(tuple(*)), '(', '['), ')', ']'), 'Array(Int64)'))) avg from codec_test1_seq
union all
select arrayDistinct(avgForEach(CAST(replaceOne(replaceOne(toString(tuple(*)), '(', '['), ')', ']'), 'Array(Int64)'))) avg from codec_test2_mon
union all
select arrayDistinct(avgForEach(CAST(replaceOne(replaceOne(toString(tuple(*)), '(', '['), ')', ']'), 'Array(Int64)'))) avg from codec_test3_var
union all
select arrayDistinct(avgForEach(CAST(replaceOne(replaceOne(toString(tuple(*)), '(', '['), ')', ']'), 'Array(Int64)'))) avg from codec_test4_rand;
/* Encoding benchmarks results */
select multiIf(table like '%rand', 'Random', 'Time-Series') dataset_type,
table, type as data_type,
multiIf(compression_codec like '%ZSTD%', 'ZSTD', compression_codec like '%LZ4%', 'LZ4', ' None') compression,
multiIf(compression_codec like '%DoubleDelta%', 'DoubleDelta',
compression_codec like '%Delta%', 'Delta',
compression_codec like '%T64%', 'T64',
compression_codec like '%Gorilla%', 'Gorilla',
' None') encoding,
compression_codec codec,
sum(data_uncompressed_bytes) uncompressed,
sum(data_compressed_bytes) compressed,
round(uncompressed/compressed,1) ratio
from system.columns
where table like 'codec_test%' and name != 'n'
group by dataset_type, table, data_type, compression, encoding, codec
order by dataset_type, table, data_type, compression, encoding, codec
FORMAT CSVWithNames;
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.
Great information, thanks!
I wonder do any of those codecs work for Float32 or Float64 ? We found Float32 especially very valuable data type for the cases when the data range can be higher than can be presented by 32bit but at this point exact accuracy is not critical
Hi Peter,Gorilla codec works fine for floats. We did not include results here, but they are close to corresponding compression for Int32/64 correspondingly.
Thanks a lot for your article.We’re about to start a project using ClickHouse and we will follow your recommendations and do some performance tests.Still not a lot of literature about ClickHouse out there so articles like these are precious gems.Cheers
Thanks a lot for your article.
We’re about to start a project using ClickHouse and we will follow your recommendations and do some performance tests.
Still not a lot of literature about ClickHouse out there so articles like these are precious gems.
Cheers
What would be the preferred compression and/or codec to use for a String Column.
Hi Alan,
For Strings values the best is LowCardinality. If you store long strings (text), LowCardinality is not an option, you may use higher levels of ZSTD instead.
Thanks,Alexander
Hm… What if the strings are actually NOT of low cardinality and differ from user to user? For example referrer URL column, IP address column, etc.Also what bothers me is what to use for a column of unique hash values. Using Delta LZ4 for DateTime column, DoubleDelta LZ4 for unique incrementing counter (UInt64) and timestamp (UInt64) columns (both increasing with small int every time), and T64 for some UInt8, UInt32 and UInt64 columns I managed to reduce table size by 5%. Sounds great, but think it could do better by using encoding and compression on other columns, too.