Rescuing ClickHouse® from the Linux OOM Killer
The Linux OOM killer terminates ClickHouse servers that use too much memory. Learn how to detect and prevent it in your environment.

The Linux OOM killer terminates ClickHouse servers that use too much memory. Learn how to detect and prevent it in your environment.

Bloom filters are an important ClickHouse index type with mysterious parameters. Take a closer look at the theory behind bloom filters, parameter selection using queries on a test dataset, and effective tuning.

We are pleased to announce a new tool for ClickHouse users: the Altinity Knowledge Base. The ClickHouse Knowledge Base is maintained by our fantastic team of engineers here at Altinity. Here you’ll find quick answers to common questions involving ClickHouse…

Kafka is a popular way to stream data into ClickHouse. ClickHouse has a built-in connector for this purpose — the Kafka engine. This article collects typical questions that we get in our support cases regarding the Kafka engine usage. We…
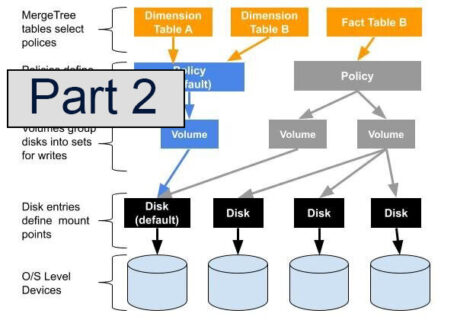
This article is a continuation of the series describing multi-volume storage, which greatly increases ClickHouse server capacity using tiered storage. In the previous article we introduced why tiered storage is important, described multi-volume organization in ClickHouse, and worked through a…
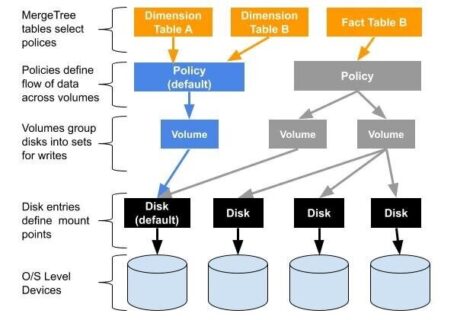
As longtime users know well, ClickHouse has traditionally had a basic storage model. Each ClickHouse server is a single process that accesses data located on a single storage device. The design offers operational simplicity–a great virtue–but restricts users to a…

June 11, 2019The most interesting innovations in databases come from asking simple questions. For example: what if you could run ClickHouse queries without a server or attached storage? It would just be SQL queries and the rich ClickHouse function library….

May 3, 2019The previous post surveyed connectivity benchmarks for ClickHouse to estimate general performance of server concurrency. In this next post we will take on real-life examples and explore concurrency performance when actual data are involved.

May 2, 2019ClickHouse is an OLAP database for analytics, so the typical use scenario is processing a relatively small number of requests — from several per hour to many dozens or even low hundreds per second –affecting huge ranges of…

Many applications have very different requirements for acceptable latencies / processing speed on different parts of the database. In time-series use cases most of your requests touch only the last day of data (‘hot’ data). Those queries should run very…