ClickHouse® In the Storm. Part 2: Maximum QPS for key-value lookups

The previous post surveyed connectivity benchmarks for ClickHouse to estimate general performance of server concurrency. In this article we will take on real-life examples and explore concurrency performance when actual data are involved.
MergeTree: Key-value lookup
Let’s see how the MergeTree engine table deals with high concurrency, and how many QPS for key-value lookups it is able to process.
We will use 2 synthetic datasets:
‘fs12M’ – table with 12 million records, id is FixedString(16) and 5 parameters of different types:
CREATE TABLE default.fs12M (
id FixedString(16),
value1 Float64,
value2 Float64,
value3 UInt32,
value4 UInt64,
str_value String
) ENGINE = MergeTree PARTITION BY tuple() ORDER BY id
SETTINGS index_granularity = 256
‘int20M’ – table with 20 million records, id is UInt64 and one Float32 parameter:
CREATE TABLE default.int20M (
id UInt64,
value Float64
) ENGINE = MergeTree PARTITION BY tuple() ORDER BY id
SETTINGS index_granularity = 256
You can find the create table statements here.
We will use two selects below to check the performance of lookup queries to those tables in 4 scenarios:
- query single records by id
- query 100 random records with 1:3 hit/miss ratio
- and also check two flavours of ClickHouse filtering for every test above — WHERE and PREWHERE (PREWHERE clause has the same syntax as WHERE but works slightly different internally).
SELECT * FROM table WHERE id = …
SELECT * FROM table WHERE id IN (... SELECT 100 random ids ...)You can find all the select statements here.
Choosing index_granularity
One of the most important parameters for MergeTree is index_granularity. Let’s try to find the best index_granularity for each case:
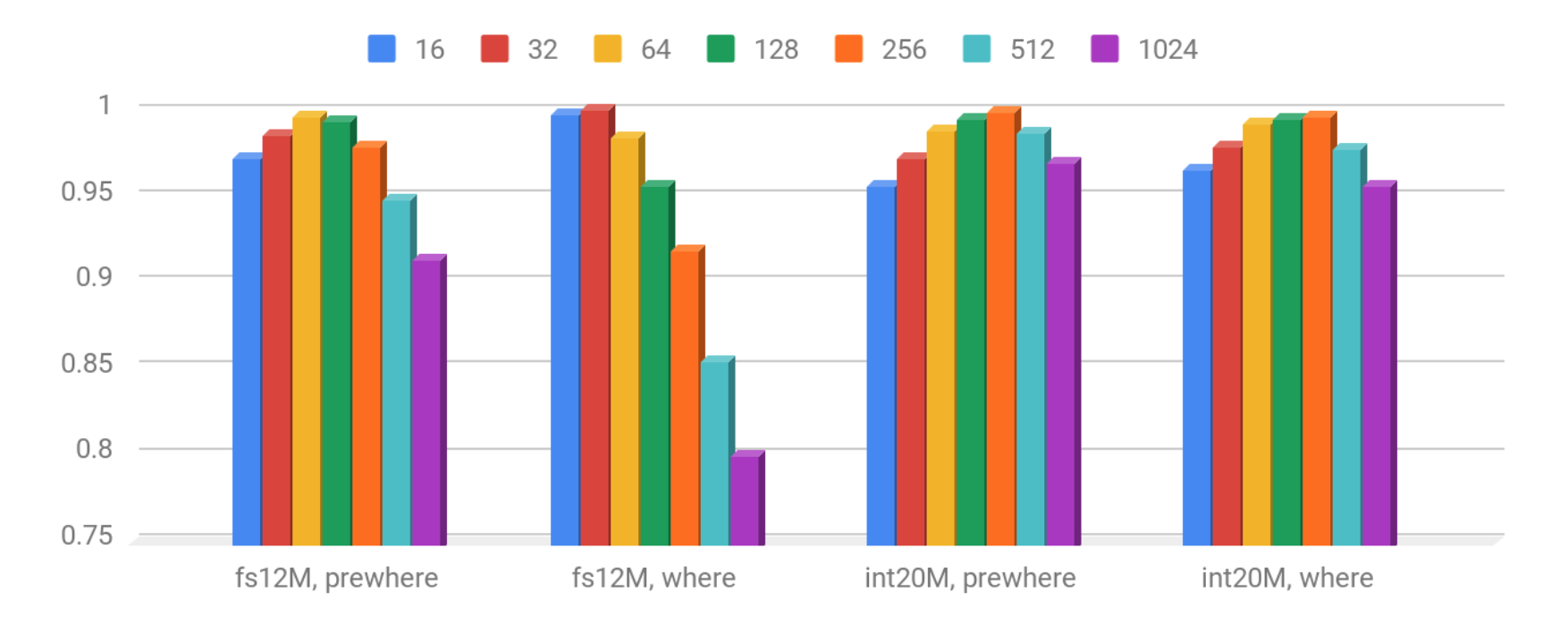
Because the above table summarizes the results of several different tests the chart shows the QPS normalized to best runs (i.e. 1 = means all tests gives the maximum QPS). As you can see ‘fs12M’ prefers a bit lower index_granularity than ‘int20M’, because key is bigger and more columns are involved (including a quite large string).
- For fs12M the best QPS performance gives index_granularity 64 & 128
- For int20M – 128 & 256.
The performance of small queries can be improved via use of the uncompressed cache. ClickHouse usually does not cache data but for fast short queries it is possible to keep an internal cache of uncompressed data blocks. It can be turned on with the use_uncompressed_cache setting at profile level. The default cache size is 8GB, but it can be increased.
Let’s see how QPS looks for 100 random ID lookups:
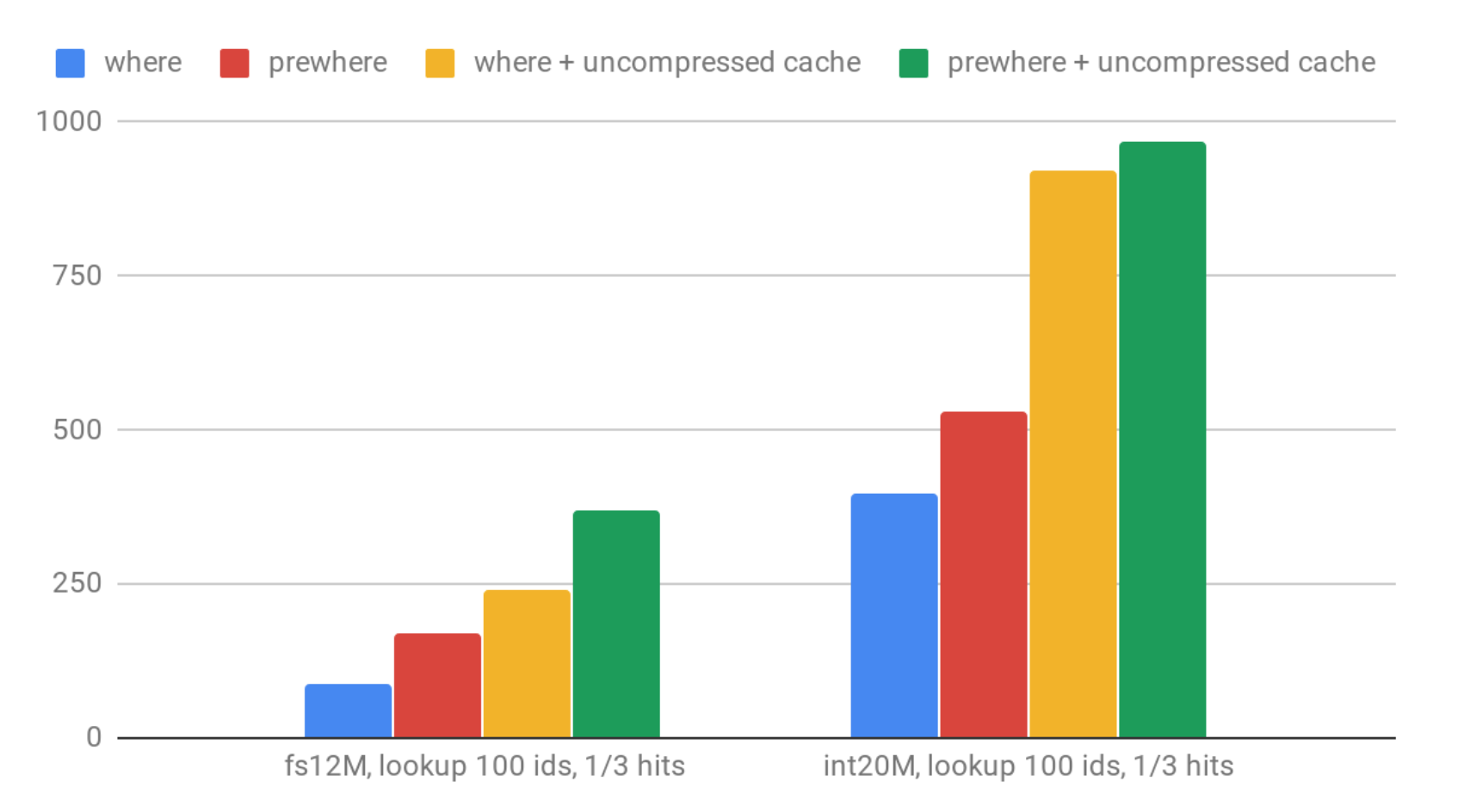
Lookups to ‘fs12’ are slower than to ‘int20M’, as we expected. Using PREWHERE instead of WHERE gives significant improvement.
Here are QPS numbers for single value lookup:
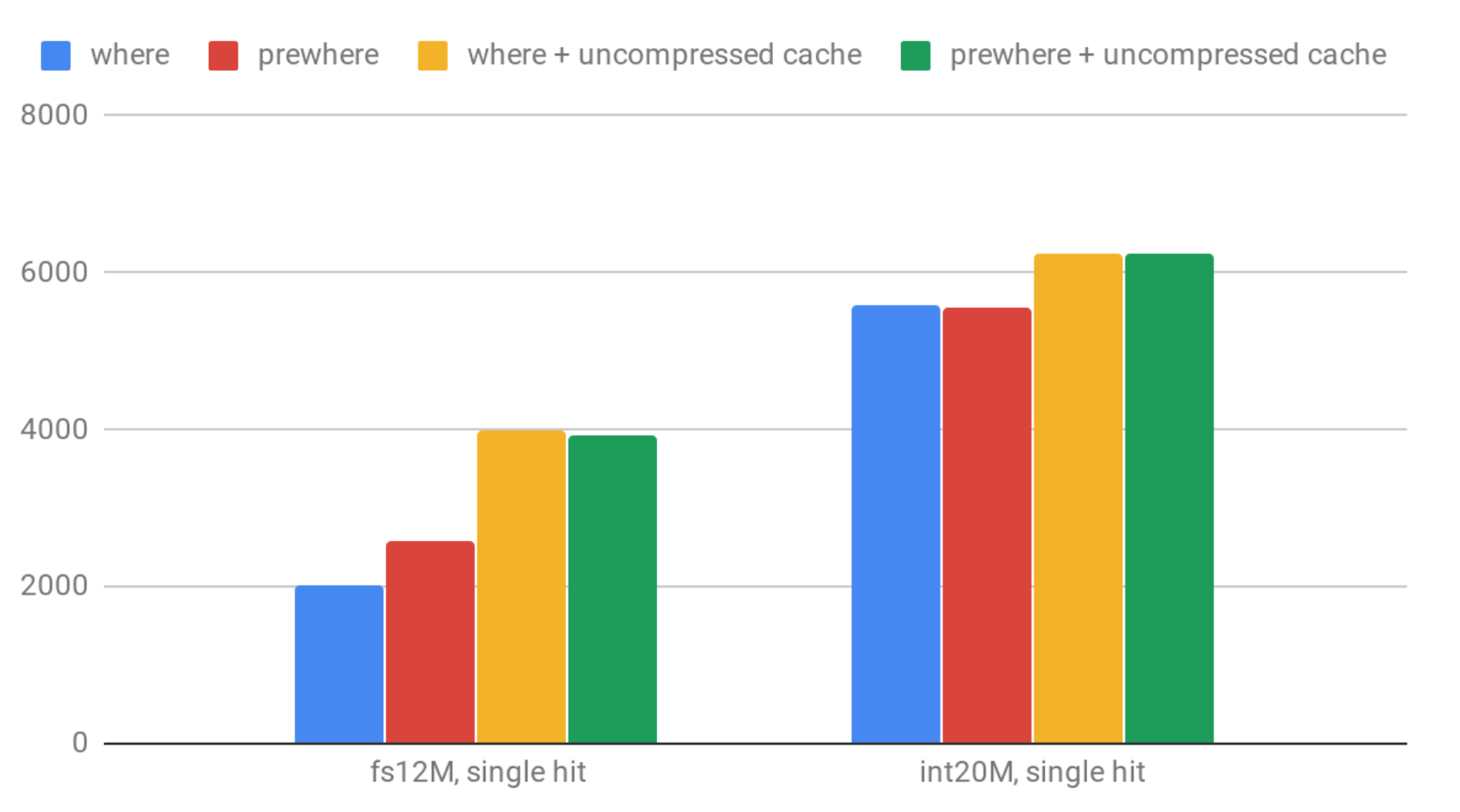
Enabling use_uncompressed_cache gives up to 50% improvement. That said, it appears that for ‘int20M’ single hit case it has lower effects because it’s already very fast in all the tested cases.
But what if that QPS is not enough? Can ClickHouse do better? Well it can, but we have to switch to a different data structure to make sure the data is always in memory. ClickHouse has several options for that: we will try external Dictionary and Join engine.
Dictionary
Dictionaries are normally used in order to integrate with external data. See our blog post on this topic. However, dictionaries can also be used in order to build in-memory caches for the data already stored in ClickHouse. Let’s see how.
First, let’s configure the dictionary for ‘int20M’ table:
<dictionaries>
<dictionary>
<name>int20M</name>
<source>
<clickhouse>
<host>localhost</host>
<port>9000</port>
<user>default</user>
<password></password>
<db>default</db>
<table>int20M</table>
</clickhouse>
<lifetime>0</lifetime>
<layout><hashed></hashed></layout>
<structure>
<id><name>id</name></id>
<attribute>
<name>value</name>
<type>Float32</type>
<null_value>0</null_value>
</attribute>
</structure>
</dictionary>
</dictionaries>You can download a ready to use file from here, which needs to be placed in the ClickHouse configuration folder.
Unfortunately creating a dictionary with FixedString key is currently impossible, so we will test the ‘int20M’ case only.
In order to get the value by the key we can query it using the dictionary get function:
select dictGetFloat32('test100M','value',9221669071414979782)You can find all the test selects here
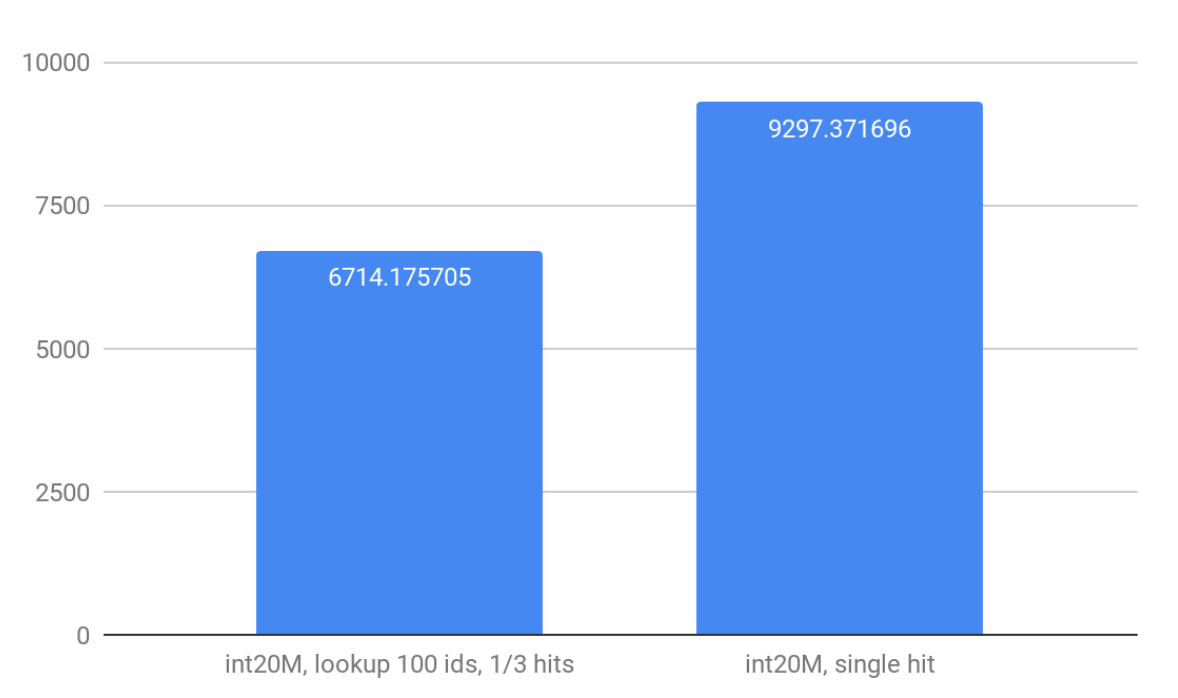
Well, it’s about 9.2K QPS: much better than with MergeTree.
Another option is to use ‘cached’ dictionaries layout which prompts ClickHouse to keep in memory only some part of the rows. It can work well if you get a high cache hit ratio.
Dictionaries work well if you do not need to update them too often. The update is asynchronous; the dictionary checks the source table periodically in order to decide if it needs to be refreshed. It may be not convenient sometimes. Another inconvenience is XML configuration. It should be fixed soon with dictionary DDLs, but for the time being we have to stick with XML.
Join table Engine
Join table engine is used internally by ClickHouse in order to handle SQL joins. But you can create such a table explicitly, just like that:
CREATE TABLE fs12M ( id FixedString(16), value1 Float64, value2 Float64, value3 UInt32, value4 UInt64, str_value String ) ENGINE = Join(ANY, LEFT, id)
After that you can insert into that table like into any other table. Ideally you fill the entire table with one INSERT, but you can also do it in parts (but still big enough parts and not too many parts are preferrable). The Join table persists in memory (just like a dictionary, but in a bit more compact way), and also flushed on disk. I.e. it will be restored after server restart.
It is not possible to query Join table directly; you always need to use it as a right part of the join. There are two options to extract data from a Join table. The first is similar to dictionary syntax using joinGet function (it was added by one of the contributors, and is available since 18.6). Or you can do a real join (with system.one table for example). We will test both approaches using the queries like the following:
SELECT joinGet('int20M', 'value', 9221669071414979782) as value
SELECT 9221669071414979782 as id, * FROM system.one ANY LEFT JOIN int20M USING (id);Results, QPS:
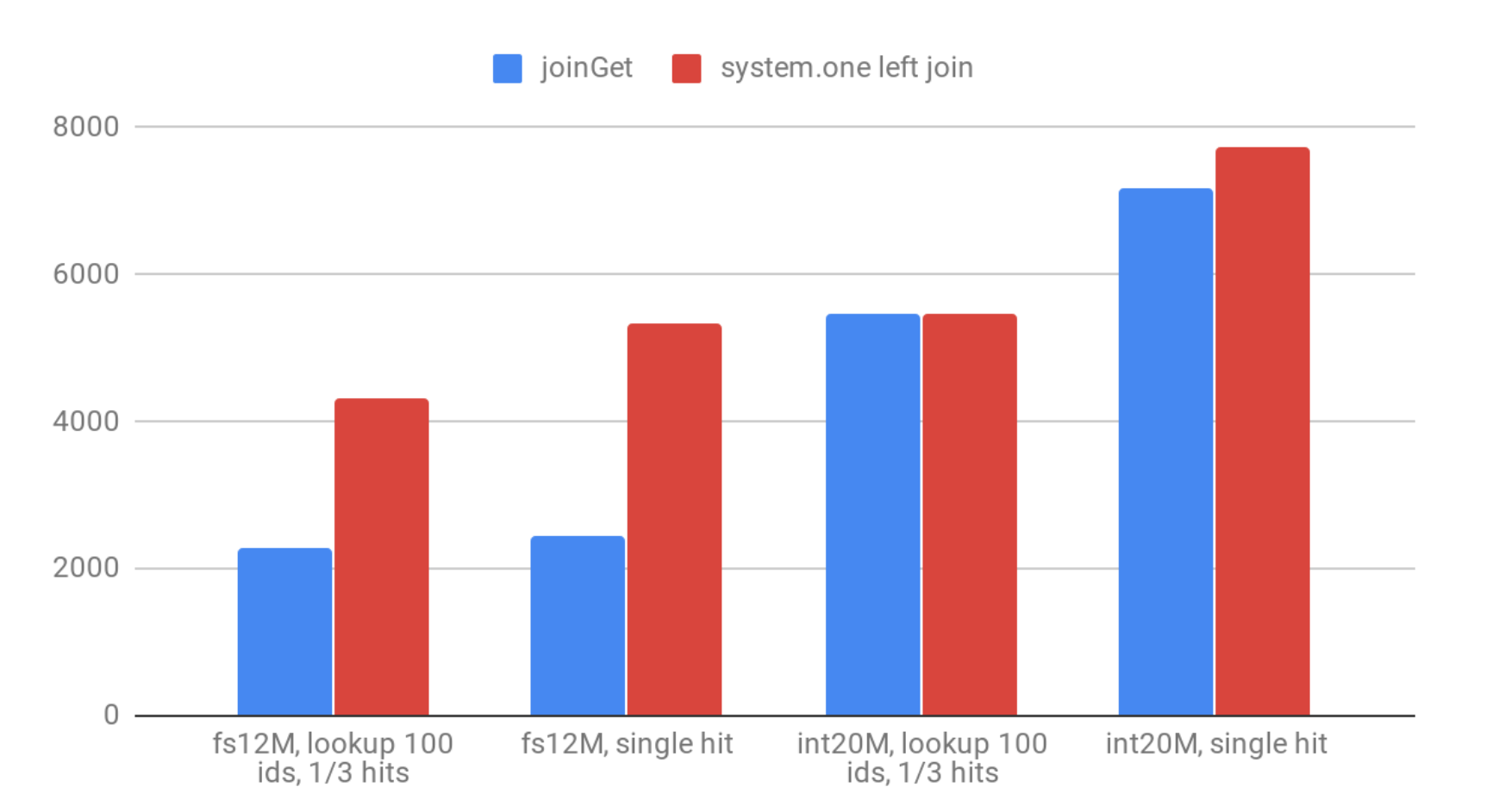
The difference between joinGet and real join is clearly visible for ‘fs12M’ when you need to do a lot of joinGet calls for every lookup. When you need to call it only once – there is no difference.
The performance of Join table is slightly worse compared to the dictionary. But it is easier to maintain, since it’s already inside the database schema. In comparison to dictionaries Joins use less memory and you may easily add new data and so on. Unfortunately, the updates are not possible. (That would be too good. 🙂 )
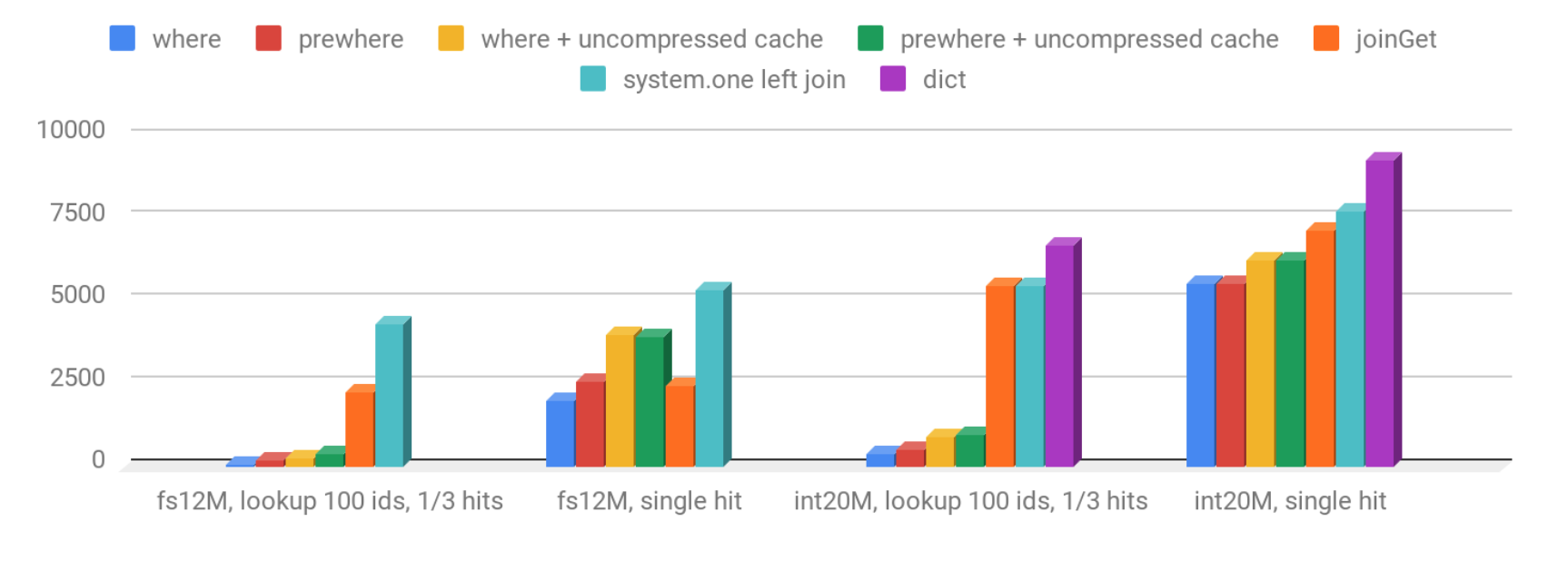
Let’s summarize and put all the QPS results on one chart:
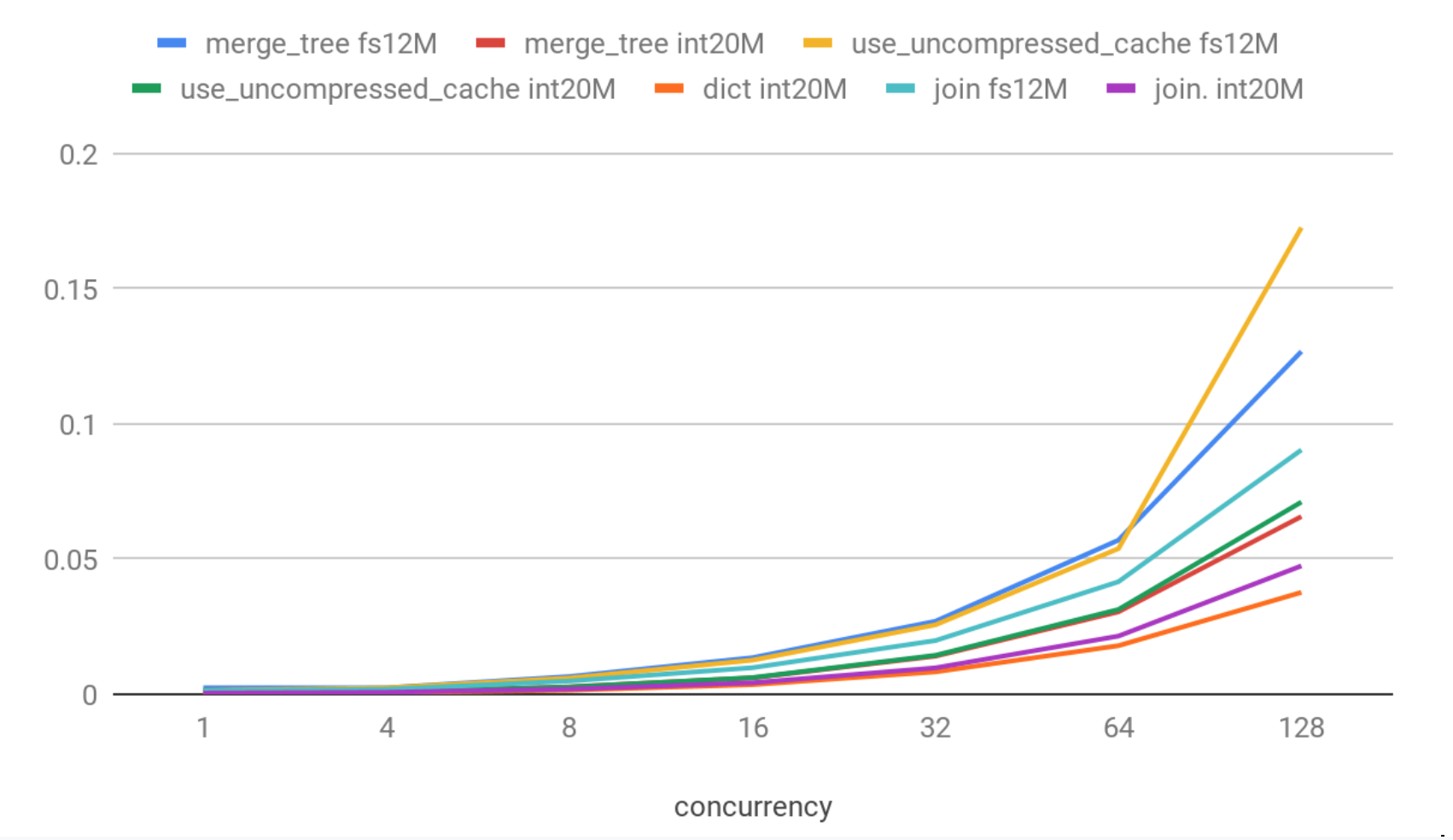
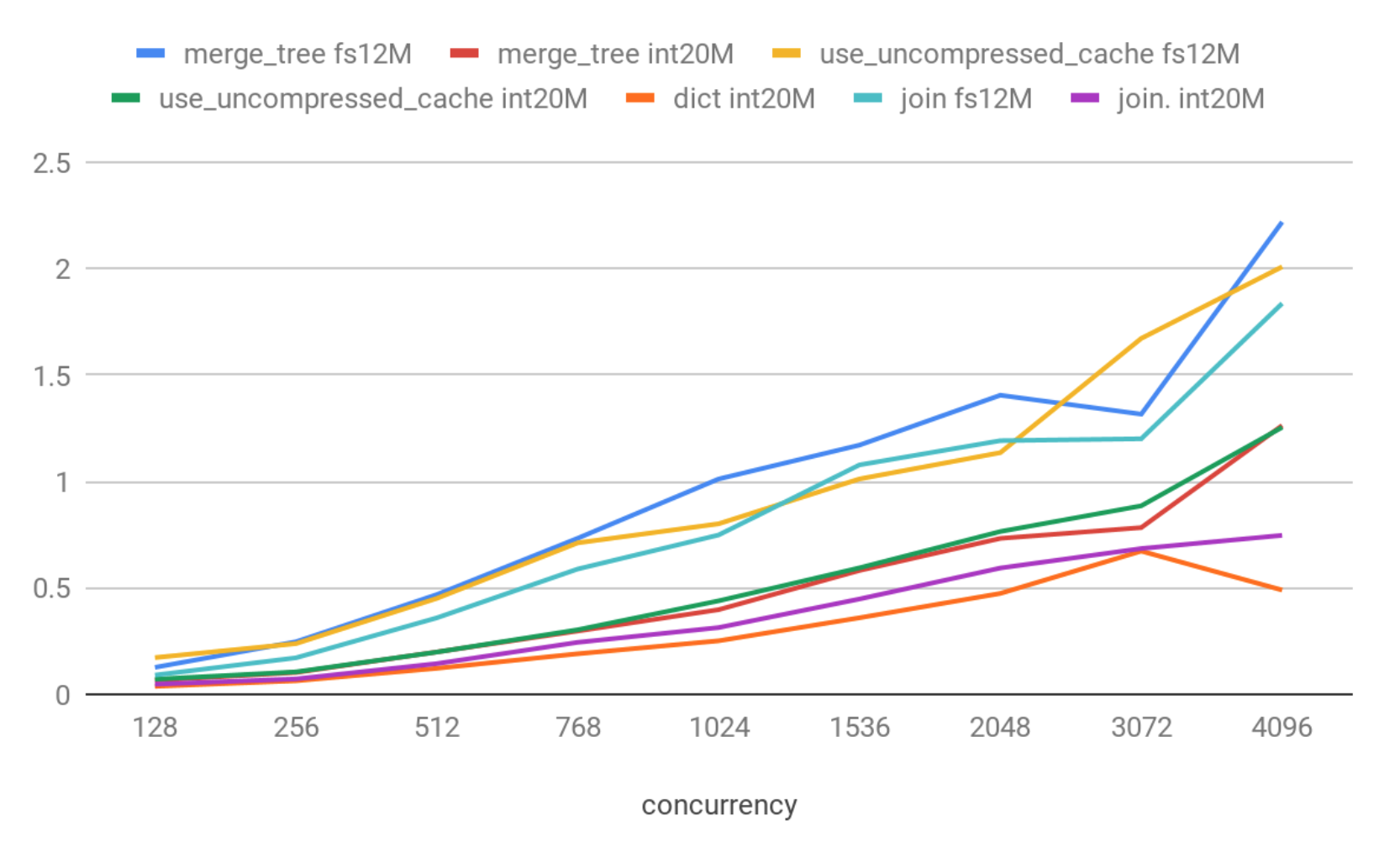
Latencies (90th percentile)
Conclusions
We have dug into concurrency basics over the course of the article. Here are some of the main conclusions that you can use for your own applications.
- ClickHouse is not a key-value database (surprise! 🙂 )
- If you need to simulate key-value lookup scenarios inside clickhouse – Join engine and Dictionaries give the best performance
- Disabling logs (or decreasing log levels) can improve performance if you have a lot of queries per second
- Enabling the uncompressed cache helps to improve selects performance (for ‘small’ selects, returning few rows). It’s better to enable it only for specific selects and a specific user profile
- Use max_thread=1 in high concurrency scenarios
- Try to keep the number of simultaneous connections small enough to get maximum QPS performance. Specific numbers depend on hardware of course. With our low-end machine used for tests, connections in the 16-32 range showed the best QPS performance
- index_granularity = 256 looks the best option for key-value type scenarios for UInt64 keys, for FixedString(16) keys consider also index_granularity = 128.
- use PREWHERE instead of WHERE for point lookups.
Summary
ClickHouse is not a key-value store, but our results confirm that ClickHouse behaves stably under high load with different concurrency levels and it is able to serve about 4K lookups per second on MergeTree tables (when data is in filesystem cache), or up to 10K lookups using Dictionary or Join engine. Of course on better hardware you will have much better numbers.
Those results are far from key-value databases (like Redis, which gives about 125K QPS on the same hardware), but there are cases when even such QPS rates can be satisfying. For example – to make some id-based lookups in data created in realtime by complicated OLAP calculations / extracting some aggregations from materialized view by id, etc. And of course, ClickHouse can be scaled both horizontally & vertically.
The QPS difference between simple ping and trivial selects shows that there is some potential for future optimizations. Also the idea of having some combination of ClickHouse with key-value databases that can cooperate with ClickHouse in both directions seamlessly sounds very promising. If you follow ClickHouse pull requests you probably saw that there are already some draft integrations with Cassandra and Redis.
Stay tuned, and subscribe to our blog!
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.