The Altinity Build System for ClickHouse®: Why, What, and How


On February 19, 2026, we shipped yet another stable release, this time the long-awaited Altinity Stable 25.8.16. It’s based on upstream ClickHouse v25.8.16.34-lts, with 15 carefully chosen patches on top. It went through 10 build configurations, four sanitizer suites, two fuzz engines, 17,000+ integration test passes, ~128 regression test jobs across two architectures, CVE scans on six Docker images, and a security signing step. The full CI report is publicly available, and anyone can click through and look at the results.
But the 25.8 release is just the latest example among many. We shipped our very first stable build back in 2021, version 21.1.10, and we haven’t stopped since. What started as a way to give our customers a version of ClickHouse with extended long-term support has grown into something much bigger, a full open-source build program with its own CI pipeline, regression suites, and security scans. Along the way, this work always presents a lot of challenges, some of which include answering basic questions about how we do our builds and why.
Note: If you landed on this page while looking for Altinity builds, packages are here and containers are here.
The Why and the What
First, we love ClickHouse as a database, and even more so the community behind it. We’ve been contributing to it for years, and we have enormous respect for the upstream engineering team. The pace of development is remarkable; the 25.8 release alone spans thousands of commits from hundreds of developers. New features land monthly, and it’s one of the most exciting open-source projects out there, with 46k stars and 8.1k forks as of recently.
The pace is exhilarating but there are also big trade-offs. If you’ve ever been responsible for keeping a ClickHouse cluster running in production, you know that “new” and “stable” aren’t always the same thing. Major version upgrades are expensive: planning, testing, cross-team coordination, security review. A recent upstream issue captures this well: Version-Aware Feature Activation for Safe Upgrades. For many teams, the priority isn’t getting new features first, but knowing that their applications will keep working without surprises.
That’s why our stable builds exist and the reason why many organizations run them in production today, including inside our Altinity.Cloud where we have customers whose nodes have been up for hundreds of days, processing petabytes of data, without a major version change. That’s not an accident, it’s the whole point.
Back in 2023, we wrote “Why Every ClickHouse User Should Appreciate Altinity Stable Builds”. A lot has happened since then. The past twelve months alone have been the busiest in our build program’s history. Here’s a quick snapshot of what we shipped and provided to the community:
Eight stable releases across five branches combined with ten Antalya releases across three major versions, with every one running through our CI pipeline.
Here’s what shipped:
| Track | Release | Shipped | Highlights |
| Stable | 24.3 | Jun 2025 refresh | Continued maintenance |
| Stable | 24.8 | Jan 2025 (refreshed Mar, Jun, Oct) | Parquet bloom filters, Keeper SSL, operational backports |
| Stable | 25.3 | Jul 2025 (refreshed Nov) | JSON/Dynamic/Variant GA, Refreshable MVs GA, workload management, Parquet improvements |
| Stable | 25.8 | Feb 2026 | Lightweight MergeTree updates, correlated subqueries, vector search GA, Iceberg writes, CoalescingMergeTree |
| Stable | 23.8 | Dec 2024 (final) | End of life |
| Antalya | 25.3, 25.6, 25.8 | Jun 2025 – Jan 2026 (10 releases) | Hybrid Table, Compute Swarms, MergeTree part export, Parquet v3, token auth, Iceberg integration |
That’s eighteen total releases across two build tracks, all fully open source and tested.
So how does the build process actually work?
Starting From Upstream
Every stable build starts from an upstream ClickHouse LTS release. Not a fork, not a proprietary variant, but the same Apache 2.0 licensed code, built independently. Take again the 25.8.16 Stable release page which shows exactly what we added on top of upstream v25.8.16.34-lts. Every patch links back to the upstream PR it came from and the Altinity PR that brought it in. Anyone can diff the two, and we actually encourage it.
The source lives at github.com/Altinity/ClickHouse. The goal is to provide fully open source releases that are stable, supported for lengths of time required by enterprises, and most importantly are free from limitations like support for shared storage or OAuth that limit a user’s ability to create capable analytic systems. Our build process reflects these goals.
One thing you’ll notice is that our stable builds carry their own version scheme — 25.8.16.10001.altinitystable rather than upstream’s 25.8.16.34-lts. That’s on purpose. When you’re debugging an issue at 3 AM, you want to know exactly which build you’re running: which patches are in it, which CI pipeline validated it, and who supports it. The version string, the Docker tags, the package names all tell you unambiguously what you have. To make the version stand out clearly and to avoid conflicts with upstream, the last part of the version is 5 digits and starts from 10000 for Stable and 20000 for Antalya. While this forces the version string to be longer than we’d like, we prefer clarity over confusion.
The Deliberate Delay
Our stable release typically ships 3–4 months after the upstream LTS appears. We know that sounds like a long time, but there’s a good reason. When an LTS release first lands, it’s essentially the latest monthly build with a promise of longer support in future. Regressions surface and community members, including us and our customers, find problems and contribute fixes. We track backport progress carefully and wait for things to stabilize before we certify.
Take the 24.8 Stable. 250+ contributors had submitted 2,400+ PRs. We spent several months testing, tracking fixes, and collecting feedback from early adopters running upstream builds. By the time we shipped, we’d also backported Parquet improvements (compression level, Boolean support, page header V2, bloom filters) and operational fixes (SSL for Keeper, S3 Express, numactl seccomp) that upstream hadn’t yet included in the 24.8 branch.
Delayed does not mean out of date. Each stable release is based on the latest upstream patch release available at shipping time, so it has all the latest changes. The 25.8 Stable shipped on February 18, 2026, based on upstream v25.8.16.34-lts — the most recent patch in the 25.8 branch. All upstream bug fixes and security patches up through that point are included. After release, we continue issuing refreshes that pick up new upstream patches. The 25.3 Stable, for example, got a refresh in November 2025 that included an OpenSSL bump for CVE-2025-9230 alongside the latest upstream backports. And during Extended Support after upstream EOL, we keep backporting critical security fixes.
The bottom line is that when you install a stable build, you can be reasonably confident it’ll work in production without needing immediate follow-up patches, or worse still, prompting a hasty downgrade
The CI/CD Pipeline Is the Hard Part
While upstream pipeline code is open-source, independently running it is actually the hard part, and not something that many people appreciate. This is because ClickHouse has one of the most complex CI/CD pipelines in open source. Credit where it’s due, the upstream ClickHouse team built something formidable. The upstream CI (github.com/ClickHouse/ClickHouse/tree/master/ci) includes:
- 17 GitHub Actions workflow files covering master merges, pull requests, merge queue, release branches, nightly fuzzers, nightly Jepsen, and hourly runs
- 12 Python workflow definitions orchestrating the pipeline logic
- 30+ job scripts for builds, functional tests, integration tests, AST fuzzer, BuzzHouse, ClickBench, performance tests, stress tests, unit tests, upgrade tests, Jepsen checks, SQLancer, libfuzzer, and more
- 16 specialized Docker images for different test environments
- A recently introduced custom CI framework called “praktika” that ties it all together
- Infrastructure definitions, build settings, and job configuration layers
It’s a bespoke CI system, and you can’t just clone it and run it. For anyone outside the core upstream team, reproducing this pipeline means re-engineering substantial infrastructure, not just “running the tests.”
Keeping the pipeline green is hard and is a full-time job. On a typical day, nearly 7 million tests run across the upstream pipeline. The aretestsgreenyet.com tracks upstream’s pipeline test stability in real time and the numbers reflect the sheer scale and ambition of the upstream ClickHouse testing infrastructure.
Our own builds and the whole community benefit enormously from the upstream CI. Every PR that lands in ClickHouse has already been through upstream’s pipeline, including fuzzers, performance benchmarks, and test suites. That work is done before the code reaches us. It is a significant aid to anyone building ClickHouse, including us.
What we do is adapt the upstream pipeline framework to run the core build, test, and release jobs on our own infrastructure, for our own release branches. Altinity’s CI pipeline (github.com/Altinity/ClickHouse/tree/releases/25.8.16/.github) includes:
- 27 workflow files, adapted from upstream, covering builds, stateless/stateful tests, integration tests, sanitizer runs, stress tests, AST fuzzer, BuzzHouse, and release packaging
- Plus Altinity-specific additions that upstream doesn’t have:
- regression.yml + regression-reusable-suite.yml — the Altinity regression test suite
- grype_scan.yml — CVE scanning on every Docker image
- docker_publish.yml — Docker image publishing to Docker Hub
- sign_and_release.yml — release signing
- compare_fails.yml — failure comparison between runs
- scheduled_runs.yml — scheduled regression runs against all supported versions
- Custom Grype tooling for scanning, parsing, and uploading vulnerability results
- 5 custom GitHub Actions for workflow reporting, Docker setup, and runner setup
So it’s not a full reproduction of everything upstream runs, but rather the core pipeline adapted to our branches, with Altinity-specific testing layered on top, which is informed by input from our support team and users.
The scale difference tells the story. Just check out the GitHub Actions usage metrics for the past year (Feb 2025 – Feb 2026).
| Repository | Minutes | Job runs | |
| ClickHouse/ClickHouse | 128,395,687 | 3,280,919 | metrics |
| Altinity/ClickHouse | 19,994,993 | 393,362 | metrics |
| Altinity/clickhouse-regression | 8,284,135 | 168,437 | metrics |
Upstream consumed 128 million minutes across 3.3 million job runs, and our two pipelines combined consumed 28 million minutes across 562 thousand job runs. Together, that’s 156 million CI minutes (nearly 300 years of compute) and 3.8 million job runs in a single year, all publicly visible on GitHub. These numbers represent the combined CI investment behind ClickHouse, and we think it’s one of the most thoroughly tested open-source databases out there.
One of the main reasons upstream has many more job runs is that its CI pipeline runs on every commit in each PR, increasing both the total number of runs and overall CI minutes consumed. We also don’t re-run every PR-level check that upstream already handled, but we do test every release branch through builds, sanitizers, fuzzers, integration tests, our own regression suite, and CVE scans. For a team our size, running at one-fifth the CI volume of upstream ClickHouse is something we’re proud of.
We keep costs down using self-hosted Hetzner Cloud runners deployed and managed by the TestFlows GitHub Hetzner Runners, our own open-source autoscaler that spins up ephemeral VMs per job and tears them down when done. When GitHub announced a $0.002/min charge for self-hosted runners, we did the math, and 28 million minutes would have been a significant bill. Fortunately, GitHub listened to the community and reversed that decision.
CI minutes and runners aside, the important thing is that both the Stable and Antalya branches run through the same pipeline. (More on Antalya shortly.) Same rigor, same checks — the only difference is the code being built.
And all of it runs on GitHub Actions, publicly visible, with full build logs and test results for every run. The 25.8 CI run is right there: 133 artifacts, every job clickable, every test result inspectable. The CI run report summarizes it on one page. Getting a fully green run across this many jobs is a challenge, and we don’t always get there. But the report makes it clear exactly what passed, what failed, and what we investigated before shipping. If you want to audit the build, you don’t need to take our word for it. You can open the URL and look for yourself.
None of this is easy, and by no means perfect, but we think it matters, and not just for our users. Open source is more than a license file, it’s the practical ability to build, test, and ship the software independently. The fact that someone outside the core upstream team can adapt the ClickHouse CI pipeline, run it on their own branches, and ship verified builds is a healthy sign for the project and for every organization that depends on it. It means ClickHouse isn’t just open in theory. It’s open in practice.
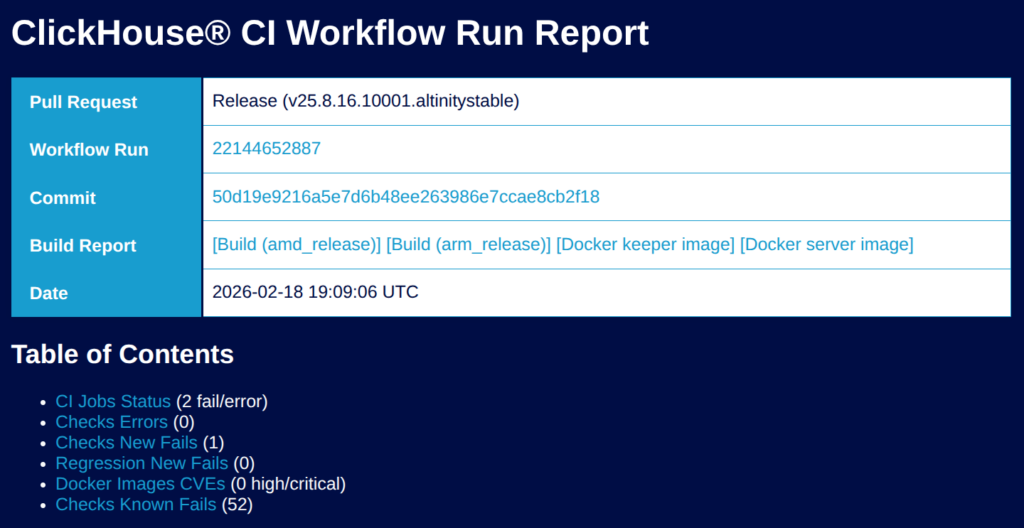
Walking Through the 25.8 CI Report
Enough talking about the pipeline. Let’s look at it. Here’s the actual CI report for 25.8.16 Stable. The GitHub Actions run took 4 hours and 17 minutes and produced 133 artifacts. The overall status is strict and shows failure because a single known flaky stateless test 03174_exact_rows_before_aggregation failed during the run.
As you can see, the workflow has so many jobs that the overall pipeline graph grows too large to display and read at the same time.
Here’s what happens, phase by phase:
| Phase | What runs | 25.8 results |
| Builds | 10 configurations: release, debug, 4 sanitizers (ASan, TSan, MSan, UBSan), binary, coverage — for AMD64 and Aarch64 | amd_release 1h49m, arm_release 54m |
| Upstream tests | Integration tests, stateless tests, unit tests, stress tests, AST fuzzer, BuzzHouse fuzzer, ClickBench | 17,164 integration passes across 21 shards, zero failures. Fuzzers green across all sanitizer configs |
| Regression tests | ~128 jobs using clickhouse-regression (TestFlows) across two architectures | More on these below |
| Security | Grype CVE scans on 6 Docker images (keeper, server, Alpine and test variants) | All 0 high/critical |
| Release | Package verification, compatibility checks, Docker builds, signing, CI report | Both architectures |
We don’t run every configuration upstream does (they add performance benchmarks, nightly fuzzers, Jepsen, and more on every PR), but we run the core suite on our release branches.
The regression suite deserves a closer look. Just on aarch64 alone, the 25.8 run covered AES encryption (5,794 examples), aggregate functions (3 multi-hour runs), alter operations (thousands of scenarios across attach, move, and replace), ClickHouse Keeper (SSL and non-SSL, multiple shards), Iceberg (2,049 scenarios across 2 shards), Kafka, Kerberos, LDAP, RBAC, S3/GCS/MinIO benchmarks, Parquet, tiered storage, disk-level encryption, SSL server, window functions, and more. Then the same suite runs again on amd64.
These tests run against real cloud infrastructure (AWS S3, GCS), not mocked environments. Outside of release builds, we also run the clickhouse-regression suite on its own schedule: Tuesday, Thursday, and Saturday against the latest head, and on Saturday against all supported versions.
When you add it all up, upstream tests, sanitizers, fuzzers, benchmarks, our own regression suite, and CVE scans, each layer catches different things. But what does it look like when they actually catch something?
The 25.8 Detective Story
A good example came during 25.8 testing. Our team kept hitting OOM errors — on idle clusters. That’s the kind of thing that shouldn’t happen, so they dug in. Turns out system.metric_log had grown to 1,417 columns, and horizontal merge of wide parts at that width needed ~6GB of RAM just to merge system tables. We submitted the upstream fix (PR #89811) and wrote up the full story. The 25.8 release notes now call this out in the “Require attention” section.
That’s what “tested and vetted” actually means, not a checkbox on a marketing slide, but engineers chasing down why idle clusters run out of memory, finding that system.metric_log grew to 1,417 columns, and submitting the fix upstream.
Finding and fixing bugs is one thing. But what happens after you ship? That’s where extended support comes in.
Three Years of Support
Let’s start with an example that matters to ops teams. 25.8.16 Stable was released February 19, 2026. Upstream support for the 25.8 LTS branch ends December 19, 2026, but Altinity Extended Support runs until February 19, 2029, giving three years of support to our users.
Here is how each release type compares:
| Release type | Support window |
| Upstream monthly stable | ~3 months |
| Upstream LTS (twice a year) | ~12 months |
| Altinity Stable | 36 months |
While upstream is actively maintaining the branch, bug fixes flow naturally, the upstream team backports them, and we pick them up in Altinity refreshes. However, for our builds, after upstream EOL, we keep going with Extended Support for P0/P1 bugs and critical security issues. Feature backports are also available by customer request.
The 25.3 Stable release (shipped July 2025) is a good example that shows how refreshes work in practice. Specifically, the November 2025 refresh picked up upstream fixes plus an OpenSSL bump to address CVE-2025-9230.
What this means for your team is that you can plan upgrades on your schedule, not the project’s. You’re not forced into a major version change every year just to stay supported, and as of this writing, some of our customers are still on 22.8 that we shipped in February 2023, for which our 3-year extended support just ended.
Focus On Security
Given that we are also users of our own builds, security matters a lot to us, to the community, and to our customers. We run Grype scans against all the Docker images that we ship. Here are the example results for 25.8 scans:
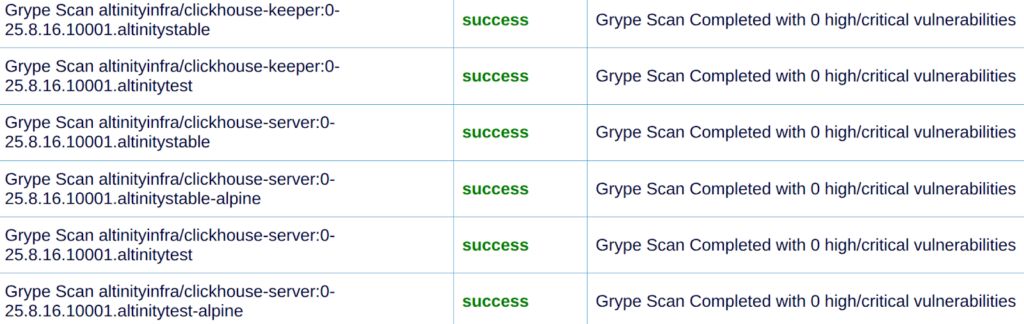
This isn’t a one-time audit we run before a big release. It runs on every build, every Docker image: server, keeper, Alpine variants, test variants. We don’t ship if it’s not clean.
Security runs through the whole pipeline:
- CVE scanning: Grype on every Docker image, zero tolerance for high/critical
- Encryption testing: dedicated regression suites for SSL, disk-level encryption, and AES encryption (5,794 test examples in the 25.8 run alone)
- FIPS builds: BoringSSL crypto libraries for organizations that need FedRAMP or PCI-DSS compliance
Given that users have different security and stability requirements, we publish three build tracks:
Altinity Stable — The production-ready choice. Based on upstream LTS, three years of support. This is what most organizations run.
Altinity FIPS — Same stability guarantees, same testing, but with FIPS 140-2 compatible cryptography via BoringSSL. For when compliance requires it.
Altinity Antalya — Our track for rapid innovation, pushing ClickHouse into the data lake era. Not all features are production ready yet, but it’s where we build and test what’s coming next.
Building The Future Together
We mentioned Antalya above. Here’s what it looks like up close. The most recent Antalya release 25.8.14.20001 (January 29, 2026) gives a good sense of where we see ClickHouse heading:
- GCS support for data lakes — expanding beyond AWS S3
- Hybrid Table improvements — the Hybrid engine now accesses ALIAS columns across segments
- Part export enhancements — accepts table functions as destination, inherits schema automatically
- Bug fixes for Iceberg columns with dots in names, two-level aggregation with Merge over Distributed
Earlier Antalya releases added Parquet reader v3 enabled by default, token-based authentication, export partition for ReplicatedMergeTree, icebergLocalCluster, and Hybrid Table auto-cast columns.
Why Antalya Builds Exist
While Antalya builds add extra work to our already busy stable builds pipeline, they address a growing need for a different architecture. We started Antalya to tackle the ballooning cost of storage and compute in large open source ClickHouse installations. This has become even more important in the AI era, where we are also adapting ClickHouse to make it the preferred AI platform, including adding real-time query on data lakes as well as built-in support for OAuth and OIDC. These builds pull in both community and upstream work as well as our own extensive contributions (e.g., OAuth).
Antalya tackles this head-on with three pillars:
- Parquet on object storage as an open data format
- Iceberg as an open table format
- Compute Swarms for separation of storage and compute, with stateless query nodes that launch instantly
We’ve already delivered Iceberg as a first-class citizen (CREATE TABLE, INSERT, schema evolution, partitioning, time travel), Compute Swarms that can match or even exceed MergeTree query performance, Hybrid Tables that let you query MergeTree and Iceberg tiers as one, and integration with AWS Glue Data Catalogs, S3 Table Buckets, and GCS.
Altinity is making a major investment in Antalya, as it not only solves cost issues but positions our builds to support new workloads from agentic AI. The 2026 roadmap is publicly available and includes production-grade maturity, standalone swarms, data transformation, catalog support (Google Metastore, Unity, Polaris), and security/OAuth. You can read more at altinity.com/project-antalya-real-time-data-lakes/.
Careful Release Notes and Upgrade Guidance
Builds are not only about CI pipelines and code; release notes and upgrade guidance are another part of the builds story that shows how we think about release decisions.
A good example is when upstream ClickHouse 25.8 enabled write_marks_for_substreams_in_compact_parts by default. This change brings a real performance improvement with significantly faster reads of subcolumns from compact parts, which matters for the new JSON data type. Good change. But it came with a catch: servers older than 25.5 can’t read the new compact part format!
If you’re running in production, the ability to roll back matters. So if you upgrade to 25.8 and discover a problem, you need to downgrade safely. However, with the new default, parts written by 25.8 would be unreadable by the version you’re rolling back to. This is why we had to revert this default. Not because the feature is bad (on the contrary, it’s genuinely useful) but because downgrade compatibility matters more than a performance default.
And in this case, the CI pipeline proved its worth again. The tests for that revert revealed a new crash: with the setting disabled, reading Object(‘json’) columns from compact MergeTree parts caused a server crash. The root cause was subtle: the old Object type converts JSON to nested Tuple structures, and without per-substream marks the compact reader couldn’t handle the deserialization. Our team wrote a targeted fix to force Wide part format for tables with deprecated Object columns, then we verified it against the failing tests, confirmed downgrade/upgrade cycles, and merged it the same day we tagged the release. Both fixes shipped together in 25.8.16 Stable.
The pipeline did what it’s supposed to do; the fix surfaced a deeper problem, the tests caught it, and the team fixed it before any user was affected. The “Require attention” section of the release notes flags all of this explicitly, so operators know what changed and why, and when you’re ready for the performance improvement, you can simply flip the setting.
This kind of opinionated choice defines our work on builds with our strong belief that we should not break rollbacks.
We’re also pretty meticulous about release notes. Every release comes with categorized changes like backward-incompatible, new features, critical bug fixes, performance improvements. The GitHub release page shows the exact diff against upstream, and every change links to both the upstream PR and the Altinity PR. So if you want to see exactly what we changed compared to upstream, the full diff is one click away.
And if you’re planning an upgrade, we wrote an e-book for that too.
Conclusion
The build process is complicated, but using our builds is not. They’re a drop-in replacement for upstream ClickHouse with the same binary interface, same configs, and same tools, and your existing client libraries, visualization tools, and monitoring integrations work without changes. If you haven’t tried them yet, it’s easy.
- Package managers: apt or yum
- Docker: altinity/clickhouse-server:25.8.16.10001.altinitystable
- Downloads: builds.altinity.cloud
Everything ships for both AMD64 and Aarch64 as .deb, .rpm, or .tgz.
And when something goes wrong, whether a crash, a performance regression, or unexpected behavior, our engineers can analyze the stack traces, reproduce the issue, and provide a fix, because we built the binaries, ran the CI that validated them, and know the code. Exactly like the metric_log OOM story above, same team, same process.
And if we come back to where we started—the 25.8 release—from upstream LTS to Altinity Stable, every step is out in the open. The source code, the patches, the CI report, the regression results, the CVE scans, the release notes.
Our philosophy is transparent, tested, supported, and opinionated where it counts.
Thousands of hours of engineering, testing, and operational experience are behind these builds. Our goal is making sure organizations can run in production with confidence for years, knowing that the entire pipeline is independently open and reproducible. That independence is good for us, for our users, and for ClickHouse as a project.
And with Antalya, we’re building the next chapter of ClickHouse for real-time data lakes in the same open, rigorous way. So whether you’re an Altinity customer or not, now you know how and why we build ClickHouse, and we’d love for you to give our Stable and Antalya builds a try.
Links:
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.