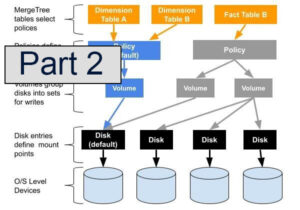
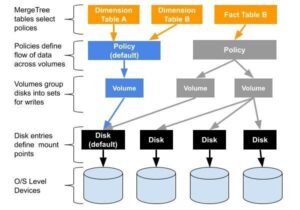
ClickHouse® and S3 Compatible Object Storage
ClickHouse is a polyglot database that can talk to many external systems using dedicated engines or table functions. In modern cloud systems, the most important external system is object storage. It can hold raw data to import from or export…