Putting Things Where They Belong Using New TTL Moves
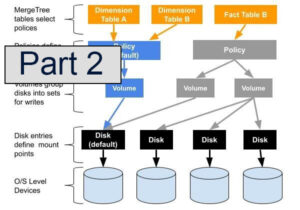
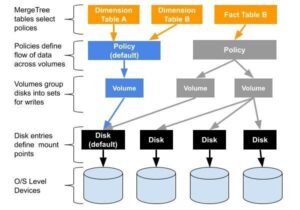
Multi-volume storage is crucial in many use cases. It helps to reduce storage costs as well as improves query performance by allowing placement of the most critical application data on the fastest storage devices. Monitoring data is a classic use…