ClickHouse® Object Storage Performance: MinIO vs. AWS S3

In our recent blog article, Integrating ClickHouse with MinIO, we introduced certified support for integrating ClickHouse‘s disk storage system and S3 table function with MinIO. Now that ClickHouse fully supports both AWS S3 and MinIO as S3-compatible object storage services, we will compare the performance of AWS S3 and MinIO when used to store table data from two of our standard datasets. We will be working with the OnTime dataset, which contains almost two hundred million rows of airline flight data, and the New York Taxi dataset, which contains just over 1.3 billion rows of New York taxi ride data. Instructions to download the datasets can be found at the links above.
For impatient readers we can share some results up-front.
- MinIO running in local Kubernetes outperforms AWS S3, often by a significant margin.
- MinIO scales well out to 64 threads, while AWS S3 tops out around 32 threads. Further work is necessary to understand AWS S3 scaling at higher numbers of threads.
- Both MinIO and AWS S3 are viable solutions that allow both cloud as well as on-prem/private cloud users to reap benefits from cheap object storage, especially for long-tail data.
We would like thank our partner MinIO, Inc., for providing the Kubernetes lab environment as well as engineering advice to enable MinIO performance tests.
Setup
AWS S3
To run our performance benchmarks on AWS S3, we start with the latest version of ClickHouse (21.5.5) running inside Kubernetes on an Amazon m5.8xlarge EC2 instance. This is a mid-range instance with 32 vCPUs, 128GB of RAM and EBS gp2 storage. The EC2 instance is located in US-East-1, the same location as the AWS S3 storage bucket we will be using. This will minimize latency while querying table data stored in S3.
The full specifications for the EC2 instance can be found here, under the section for M5 instances in the “General Purpose” section.
MinIO
In order to replicate these settings with MinIO, we also start with the latest version of ClickHouse and MinIO running inside Kubernetes 1.20.4, along with a MinIO client service to interact with MinIO directly. As noted above, the Kubernetes cluster was kindly supplied by the team at MinIO, Inc. The Kubernetes hosts were spec’ed as follows:
Architecture: x86_64
CPU(s): 80
Model name: Intel(R) Xeon(R) Gold 5218R CPU @ 2.10GHz
RAM: 128GB
Storage: NVMe SSDThe MinIO cluster was deployed using the following command from MinIO docs to create a new tenant.
kubectl minio tenant create altinity \
--servers 8 \
--volumes 80 \
--capacity 40Ti \
--namespace altinity \
--storage-class direct-csi-min-ioData Loading
The preliminary data loading is very simple. Since MinIO and AWS S3 are both S3-compatible storage services, we can use the MinIO client to load data into the MinIO bucket and AWS CLI to load data into AWS S3. After the data is loaded, we can use the ClickHouse S3 table function to load data from the buckets into our cluster.
Loading data from MinIO into the ClickHouse cluster
First, we will use the MinIO client to load data into the MinIO bucket. Assuming that the files we want to load are in a local directory named tripdata, and the MinIO client is configured with our host, we can load the files into MinIO using the mc mv command with the --recursive option. We then insert into ClickHouse using the s3 table function.
mc mv --recursive tripdata altinity-clickhouse-data/nyc_taxi_rides/data/INSERT INTO tripdata_minio SELECT *
FROM s3('https://minio.altinity.svc.cluster.local/altinity-clickhouse-data/nyc_taxi_rides/data/tripdata/data-20*.csv.gz', [access_key_id, secret_access_key], 'CSVWithNames', 'pickup_date Date, ... <see column names> ... , junk2 String', 'gzip')
Query id: 6d25f772-044d-4c98-b8ce-ce420435bcc9
Ok.
0 rows in set. Elapsed: 255.184 sec. Processed 1.31 billion rows, 167.39 GB (5.14 million rows/s., 655.96 MB/s.) Loading data from AWS S3 into the ClickHouse cluster
Similarly, we can use AWS CLI to load data into the AWS S3 bucket. Assuming that the files we want to load are in a local directory named tripdata, and AWS CLI is configured with credentials to access the bucket, we can load the files into AWS S3 using the aws s3 cp command with the --recursive option. As with MinIO, we insert into ClickHouse using the s3 table function.
aws s3 cp tripdata s3://altinity-clickhouse-data/nyc_taxi_rides/data/ --recursiveINSERT INTO tripdata_s3 SELECT *
FROM s3('https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/nyc_taxi_rides/data/tripdata/data-20*.csv.gz', 'CSVWithNames', 'pickup_date Date, ... <see column names> ... , junk2 String', 'gzip')
Query id: 59dbcdc6-8c76-4c43-836c-fdc33e42c679
Ok.
0 rows in set. Elapsed: 366.402 sec. Processed 1.31 billion rows, 167.39 GB (3.58 million rows/s., 456.85 MB/s.) We will load the OnTime dataset in the same way.
OnTime Dataset
The OnTime dataset contains almost two hundred million rows of airline flight data. We will be testing performance with queries that could be useful for analysis of this data, such as determining the number of flights per day in a certain year.
ClickHouse Schema
One reason we selected this dataset for performance benchmarks is because the dataset contains 109 columns. It will be very interesting to compare performance scaling for MinIO and AWS S3 when there are so many columns in the dataset.
You can find the complete schema for the table on the OnTime dataset page. You can find the full list of benchmarking queries in the query section.
Overall Results
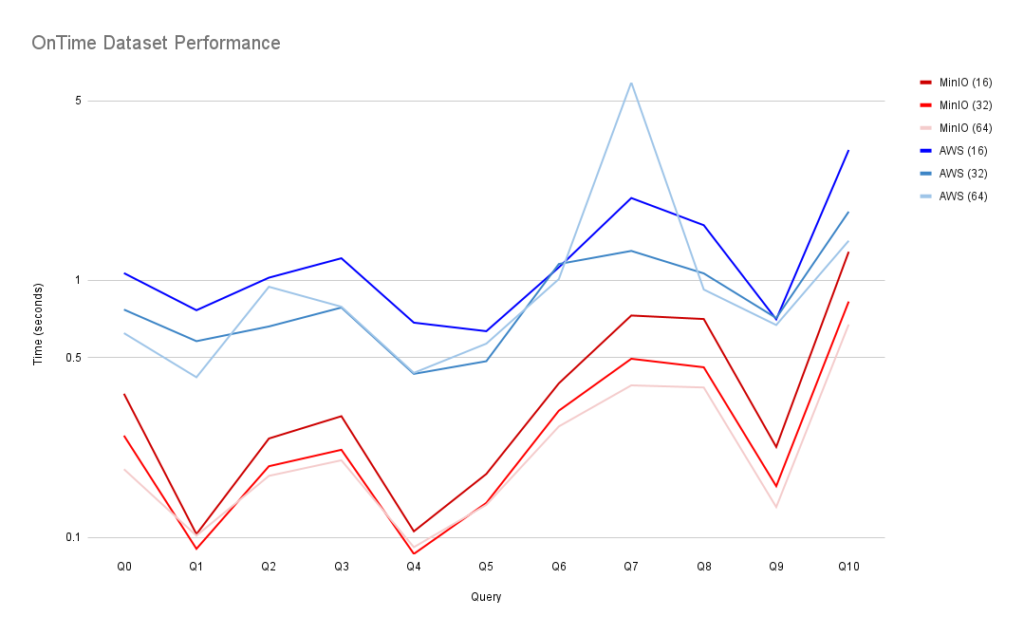
Here are the results for all benchmark queries, with query response time in seconds. Smaller is better.
| MinIO (16) | MinIO (32) | MinIO (64) | AWS (16) | AWS (32) | AWS (64) | |
| Q0 | 0.362333 | 0.249 | 0.18433333 | 1.06766666 | 0.77 | 0.62366666 |
| Q1 | 0.103 | 0.0903333 | 0.10166666 | 0.76566666 | 0.58033333 | 0.42 |
| Q2 | 0.2426666 | 0.18933333 | 0.17366666 | 1.025 | 0.662 | 0.94466666 |
| Q3 | 0.2963333 | 0.21933333 | 0.19966666 | 1.21966666 | 0.78433333 | 0.79 |
| Q4 | 0.10566666 | 0.08633333 | 0.09166666 | 0.685 | 0.433 | 0.437 |
| Q5 | 0.17666666 | 0.13633333 | 0.134 | 0.63466666 | 0.485 | 0.56766666 |
| Q6 | 0.39766667 | 0.31133333 | 0.27033333 | 1.124 | 1.15833333 | 1.012 |
| Q7 | 0.73033333 | 0.49566666 | 0.39066666 | 2.092 | 1.30266666 | 5.896333 |
| Q8 | 0.70766666 | 0.45933333 | 0.3833333 | 1.64 | 1.065 | 0.92166666 |
| Q9 | 0.225 | 0.15833333 | 0.13133333 | 0.70566666 | 0.714 | 0.67066666 |
| Q10 | 1.2926666 | 0.82766666 | 0.674 | 3.217 | 1.85133333 | 1.4266666 |
And here is a visual comparison of AWS S3 and MinIO for each query and thread count. As this log-scale graph shows, MinIO consistently outperformed native S3 across all queries.
Detailed Query Results
We will now explore specific queries in the Ontime benchmark.
Q0: Average number of flights per month
This query tests aggregate functions, nested queries, and multiple grouping.
SELECT avg(c1)
FROM
(
SELECT Year, Month, count(*) AS c1
FROM ontime_s3
GROUP BY Year, Month
);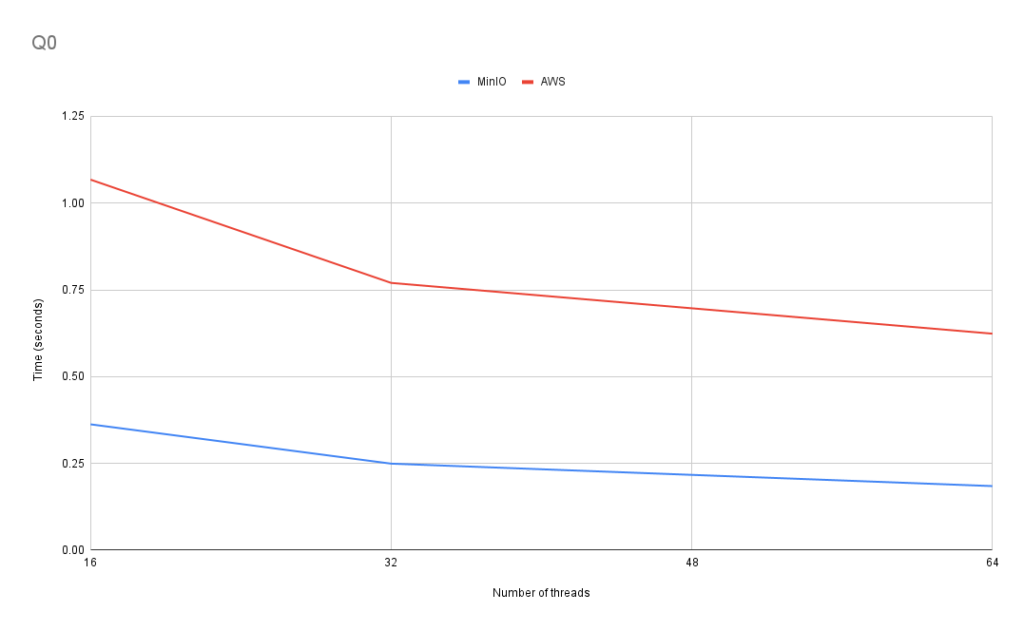
In Q0, the scaling is consistent for both storage services as we increase the number of threads available. However, the increase in performance is larger between 16 and 32 threads than between 32 and 64. For AWS S3, the performance increase was about 28% between 16 and 32 threads and 19% between 32 and 64 threads. For MinIO, the performance increase was about 31% between 16 and 32 threads and 26% between 32 and 64. We see roughly similar behavior for the other queries we ran.
Q5: The percentage of delays by carrier for 2007
This query tests JOIN performance.
SET joined_subquery_requires_alias = 0;
SELECT Carrier, c, c2, c*100/c2 as c3
FROM
(
SELECT
Carrier,
count(*) AS c
FROM ontime_s3
WHERE DepDelay>10
AND Year=2007
GROUP BY Carrier
)
JOIN
(
SELECT
Carrier,
count(*) AS c2
FROM ontime_s3
WHERE Year=2007
GROUP BY Carrier
) USING Carrier
ORDER BY c3 DESC;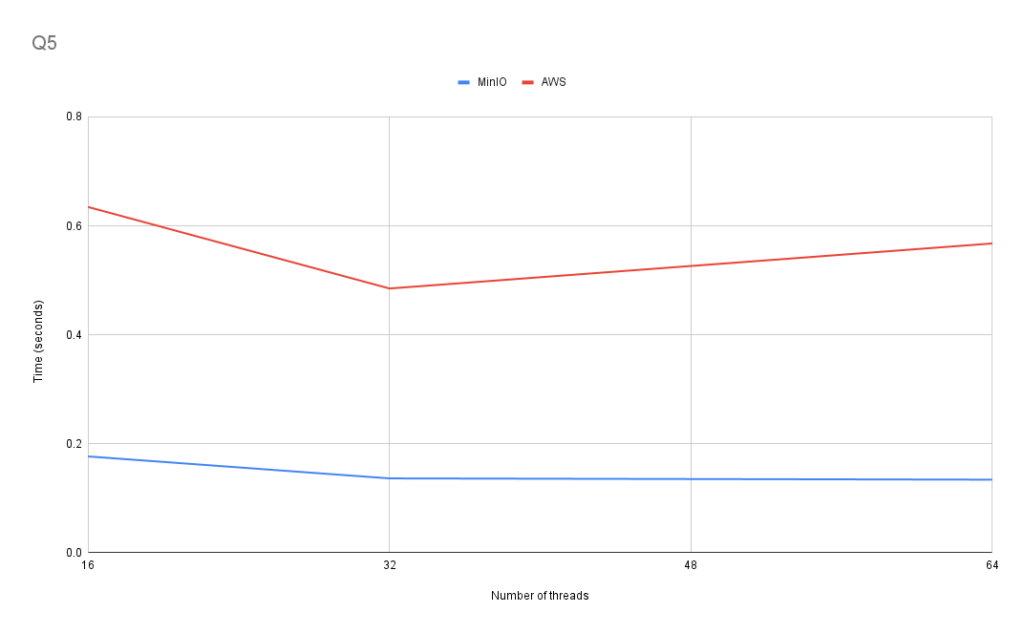
In Q5, the scaling between 32 threads and 64 threads is much less consistent. When using AWS S3, the performance with 32 threads was better than the performance with 64 threads, while MinIO showed a negligible difference in performance. The inconsistent performance improvement between 32 and 64 threads using AWS S3 reoccurred several times, and we will discuss this later.
Q8: The most popular destinations by the number of directly connected cities for various year ranges
This query tests the performance of the uniqExact ClickHouse aggregate function.
SELECT DestCityName, uniqExact(OriginCityName) AS u
FROM ontime_s3
WHERE Year >= 2000 and Year <= 2010
GROUP BY DestCityName
ORDER BY u DESC LIMIT 10;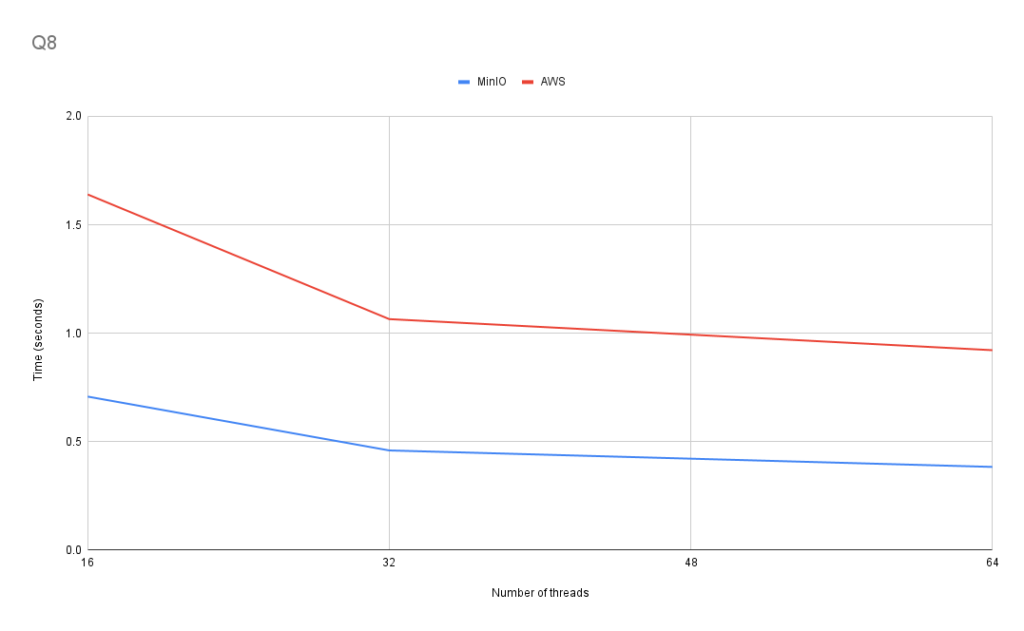
Q8 displays scaling similar to Q0.
Q10: Carrier lifespan, number of trips, and other data with several where conditions
This query tests performance using several aggregate functions simultaneously. It also has several conditions in the WHERE and HAVING clauses.
SELECT
min(Year), max(Year), Carrier, count(*) AS cnt,
sum(ArrDelayMinutes>30) AS flights_delayed,
round(sum(ArrDelayMinutes>30)/count(*),2) AS rate
FROM ontime_s3
WHERE
DayOfWeek NOT IN (6,7) AND OriginState NOT IN ('AK', 'HI', 'PR', 'VI')
AND DestState NOT IN ('AK', 'HI', 'PR', 'VI')
AND FlightDate < '2010-01-01'
GROUP by Carrier
HAVING cnt>100000 and max(Year)>1990
ORDER by rate DESC
LIMIT 1000;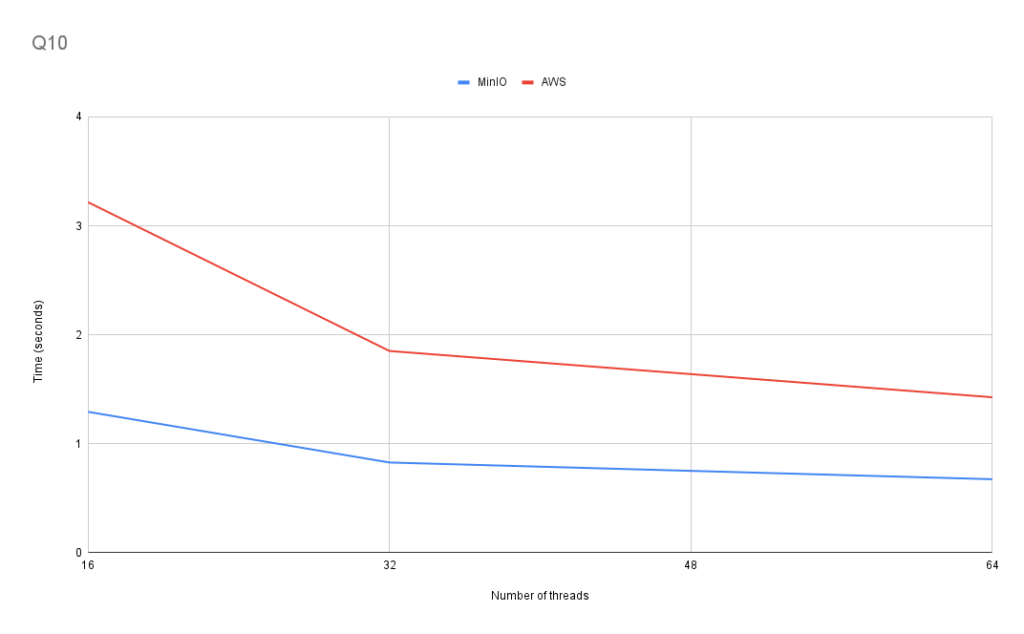
Q10 also displays similar scaling.
General Analysis
MinIO outperforms AWS S3 in all of our Ontime benchmarking queries. In fact, MinIO outperformed AWS S3 when we used MinIO with 16 threads and AWS S3 with 64 threads, illustrating the sizeable difference in performance between the two object storage services.
As we can see in the graphs, the performance of each query uniformly scales as we increase the number of threads available, the query runtime drops, with one notable exception. The scaling is due to the behavior of the max_threads setting, which can be changed using the SET command. The max_threads setting governs the maximum number of query processing threads that ClickHouse can use. As we increase the number of query processing threads available, we increase the level of parallelization, which will decrease the runtime in most cases. We will discuss the notable exception when we use the New York Taxi dataset.
In the graph, you may notice unusual behavior during Q7 by the AWS S3 bucket. It takes several seconds longer to complete the query when using 64 threads than 16 and 32 threads. After looking through the log files, we noticed tail lag for one thread when we use 64 threads. This thread receives a response nearly a second after the other threads have finished execution.
Here is a histogram of the worst response times of each thread used in the 16 thread trial and the 64 thread trial.
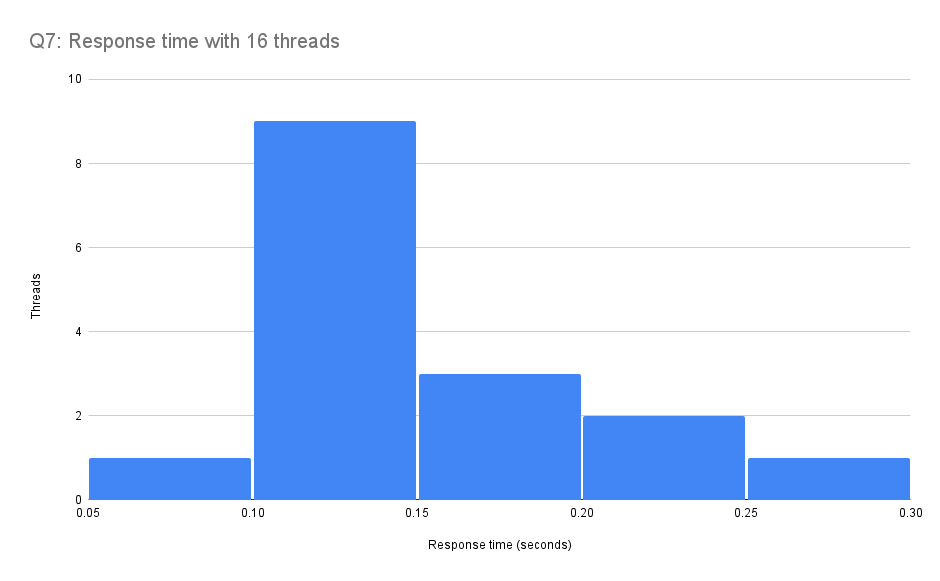
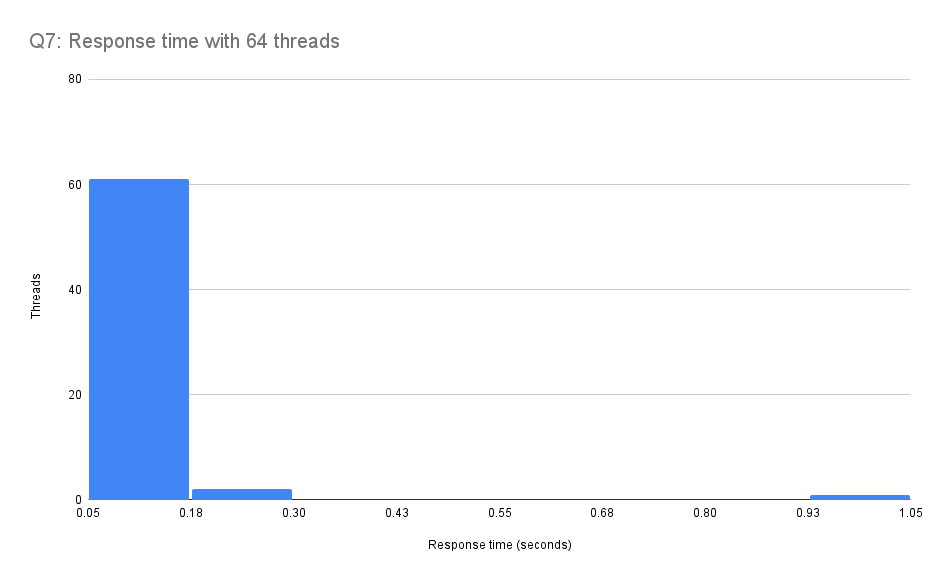
As you can see in the histogram above, there is a single outlier with over one second response time. Here is a close-up histogram of the same data with the outlier removed. The rest of the threads’ response times are distributed similarly to the run with 16 threads.
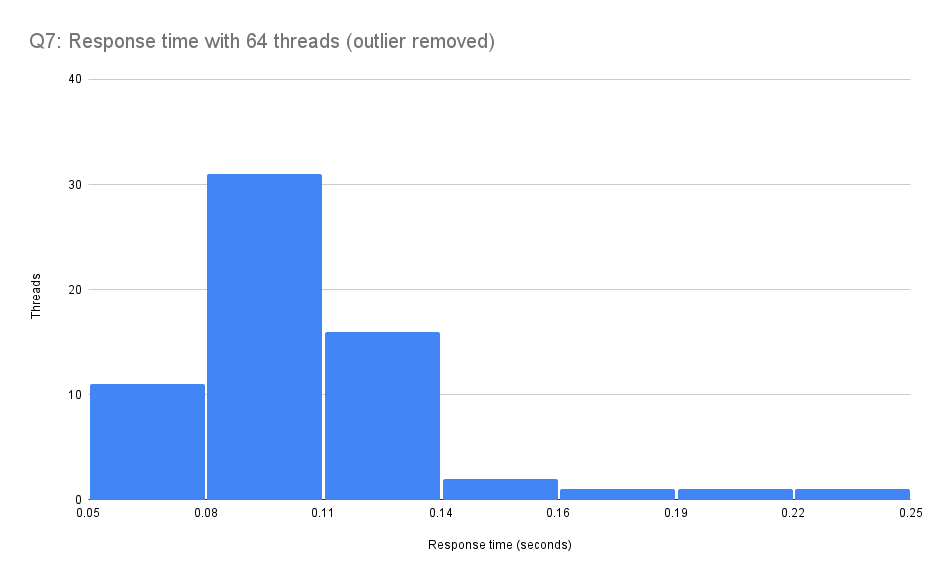
Outlier seem to be common when there are large numbers of threads accessing S3. We saw similar results across a number of runs. One hypothesis is that we’re seeing a long-tail performance effect that becomes more visible with large numbers of threads accessing S3 across the network. Another possibility is that this is a local effect due to the VM configuration and/or load within the host. We plan further work to investigate.
New York Taxi Dataset
The New York Taxi dataset contains approximately 1.3 billion rows of New York taxi ride data. We will be testing performance with queries that could be useful for analyzing this data, such as determining the average tip amount for each month in a year.
ClickHouse Schema
This dataset is much larger than the OnTime dataset, and it only contains twenty-five columns. It will be interesting to compare the results of each dataset to see how AWS S3 and MinIO perform using datasets with different dimensions as we increase the number of threads ClickHouse uses for query processing.
You can find the complete schema for the table on the New York Taxi dataset page.
Overall Results
Here are the results for all the queries (query time is in seconds). You can find the full list of queries at New York Taxi Dataset Queries. As with the Ontime benchmark, smaller is better.
| MinIO (16) | MinIO (32) | MinIO (64) | AWS (16) | AWS (32) | AWS (64) | |
| Q0 | 2.265666 | 1.265666 | 0.877333 | 5.055 | 7.42166666 | 8.70233333 |
| Q1 | 2.214333 | 1.22733 | 0.754 | 4.751 | 2.16166666 | 1.77933333 |
| Q2 | 3.567 | 2 | 1.48066 | 8.14366666 | 7.865 | 8.5766666 |
| Q3 | 2.971 | 4.76 | 1.09 | 7.0433333 | 7.73733333 | 8.651 |
| Q4 | 2.72666 | 1.4883333 | 1.0826666 | 7.08066666 | 7.85 | 8.53833333 |
| Q5 | 1.527 | 0.854 | 0.55233 | 3.656 | 2.12033333 | 1.79266666 |
| Q6 | 2.538 | 1.396 | 0.96866666 | 6.03433333 | 6.968 | 7.66566666 |
| Q7 | 5.76 | 3.157 | 2.2283333 | 12.54366666 | 12.89233333 | 14.503 |
| Q8 | 2.073 | 1.2026666 | 0.833 | 2.99166666 | 1.96466666 | 2.03033333 |
And here is a visual comparison of AWS S3 and MinIO for each query and thread count.
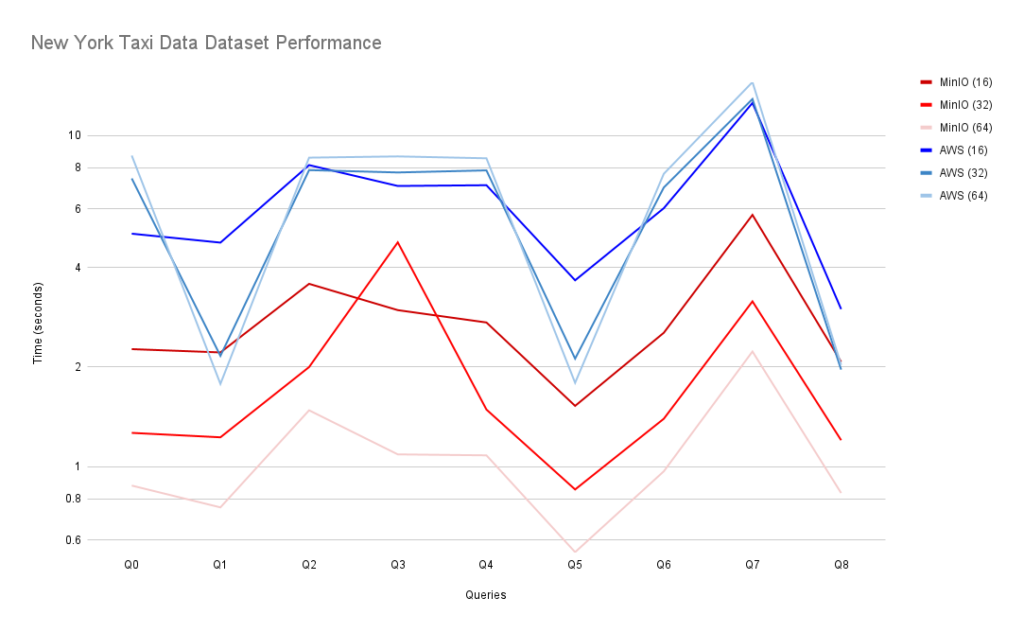
Queries
We will explore detailed results for specific queries in the benchmarks.
Q1: Passenger count for each year
This query tests performance using aggregate functions and grouping over the entire dataset.
SELECT passenger_count, toYear(pickup_date) AS year, count(*) FROM tripdata_s3 GROUP BY passenger_count, year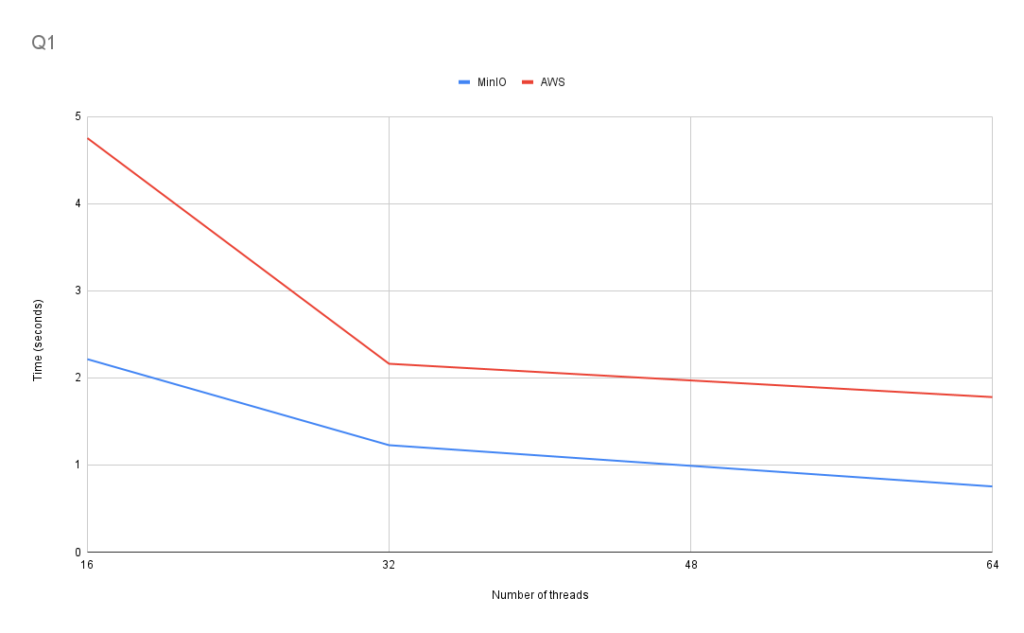
In Q1, we see scaling similar to what we saw using the OnTime dataset. The increase in performance is larger between 16 and 32 threads than between 32 and 64 threads. For AWS S3, the performance increase was about 54.5% between 16 and 32 threads, and 18% between 32 and 64 threads. For MinIO, the performance increase was approximately 44.5% between 16 and 32 threads and 38.5% between 32 and 64 threads. However, scaling in this dataset is not as consistent as using the OnTime dataset.
Q3: Yearly average trip distance
This query tests performance by using aggregate functions and grouping to calculate yearly average trip distance.
SELECT
avg(trip_distance),
toYear(pickup_datetime) AS year
FROM tripdata_s3
GROUP BY year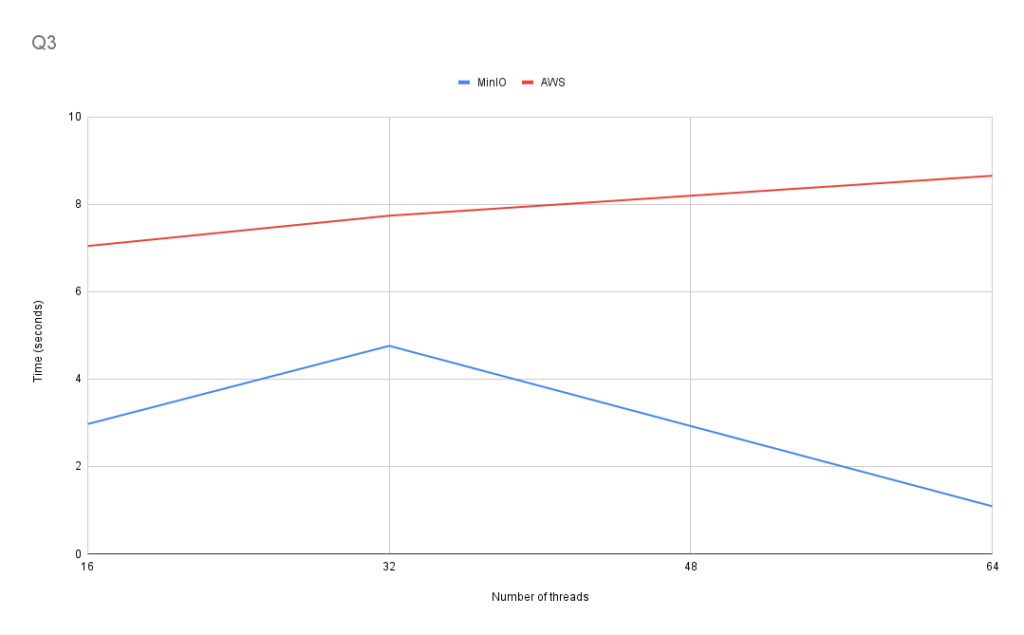
As we can see in Q3, the query performance no longer scales consistently. In fact, the performance of the AWS S3 bucket became worse as we increased the number of threads available. MinIO also showed inconsistent scaling, seeing that performance worsened between 16 and 32 threads.
Q5: Most used payment type
This query uses GROUP BY and ORDER BY to select the most used payment type.
SELECT payment_type
FROM tripdata_s3
GROUP BY payment_type
ORDER BY count(*) DESC
LIMIT 1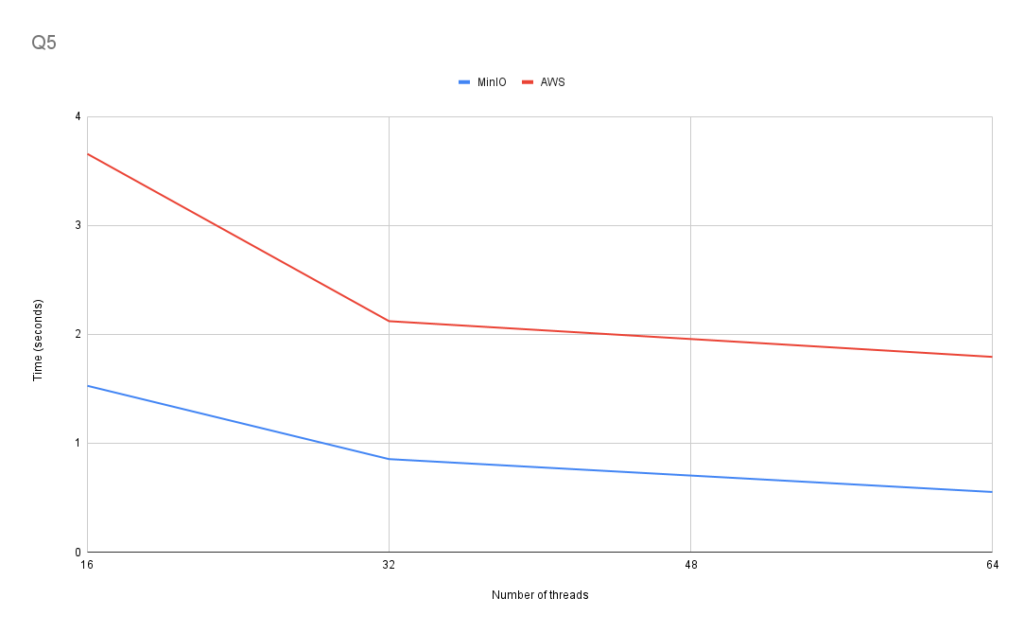
Q5 shows consistent scaling as we increase the number of query processing threads available.
Q8: Most common vendor
This query uses GROUP BY and ORDER BY count(*) to select the most common vendor in the entire dataset.
SELECT vendor_id
FROM tripdata_s3
GROUP BY vendor_id
ORDER BY count(*) DESC
LIMIT 1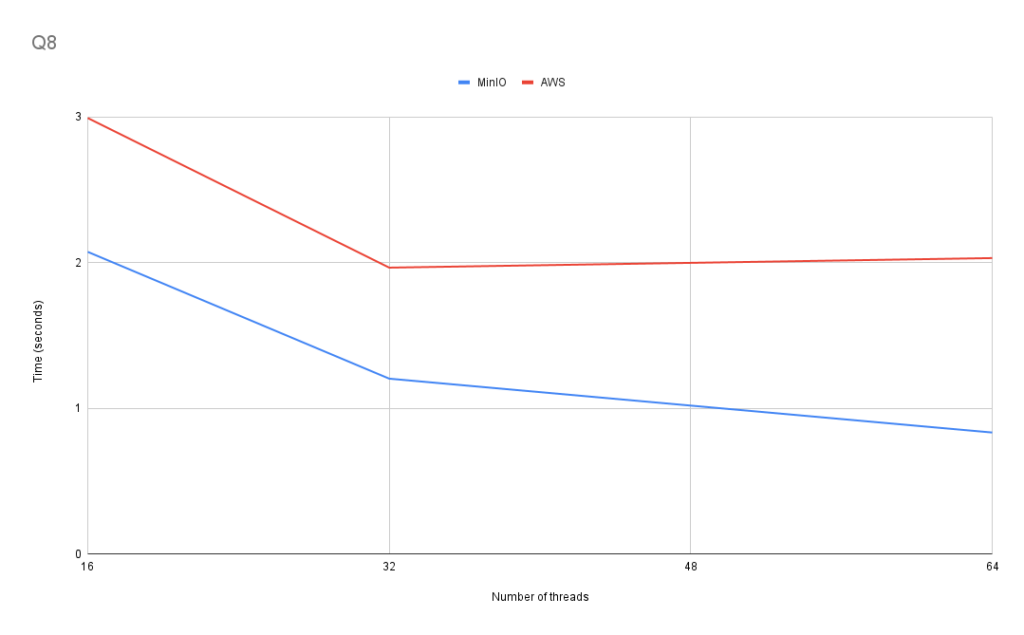
Q8 does not show consistent scaling as we increase the number of query processing threads available. Once again, when increasing the number of threads available from 32 to 64 when using AWS S3, the performance decreased.
General Analysis
MinIO once again outperforms AWS S3 in all of the Taxi data benchmarking queries. In almost all the queries we ran, MinIO outperformed AWS S3 when using MinIO with 16 threads and AWS S3 with 64 threads. However, performance was much less consistent for both storage services. In Q1, Q5, and Q8, we can see that the difference in the performance of AWS S3 and MinIO is much narrower than for other queries, with the AWS S3 lines even crossing the MinIO lines at some points.
AWS S3 Performance Scaling
At first glance, we attributed the inconsistent scaling of the AWS S3 bucket to the bandwidth limitations on the EC2 m5.8xlarge instance we used, which is capped at 10 Gbps. However, after checking the request and response times for individual threads, during runs with 64 threads, some threads again had a much slower response time. We believe that these two factors are the leading causes of the slow runtimes using the AWS S3 storage bucket with 64 threads.
Conclusion
In conclusion, MinIO is significantly faster than AWS S3 when used to store ClickHouse table data. Using the OnTime dataset, the average speedup using MinIO versus using AWS S3 ranged from 41% to 79%. When we used the New York Taxi Data dataset, the average speedup using MinIO versus AWS S3 ranged from 57% to 83%. It would be interesting to compare MinIO against block storage.
Both object storage services showed relatively consistent scaling as we increased the number of threads available to use during query processing. MinIO showed smoother scaling than AWS S3, which topped out at 32 threads. We have further work ahead to provide root cause and mitigations for AWS S3 performance variations. In the meantime our benchmarks demonstrate that S3 performance does scale well at lower numbers of threads.
ClickHouse now provides full support for AWS S3 and MinIO external object storage. You can find a brief tutorial for using each service in two of our previous articles: Integrating ClickHouse with MinIO and ClickHouse and S3 Compatible Object Storage. We welcome your feedback and encourage you to try object storage. It’s a major feature of ClickHouse for large datasets that works well in the cloud as well as self-managed environments.
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.
“ClickHouse now provides full support for AWS S3 and MinIO external object storage. ”
— Is this a official released feature or still experimenting?